






多模态表征学习,作为一种学习不同模态信息及其相互关系的技术,已经在多种应用中取得了显著的成功,例如视觉问答(Visual Question Answering, VQA)、自然语言视觉推理(Natural Language for Visual Reasoning, NLVR)和视觉语言检索(Vision Language Retrieval, VLR)。在这些应用中,跨模态交互和不同模态的互补信息对于高级模型执行任何多模态任务至关重要,例如理解、识别、检索或生成。研究人员提出了多种方法来解决这些任务。基于变换器的架构的不同变体在多个模态上表现出色。本综述提供了关于深度学习多模态架构的演变和增强的全面文献,以处理文本、视觉和音频特征,用于各种跨模态和现代多模态任务。本研究总结了(i)最新的特定任务深度学习方法,(ii)预训练类型和多模态预训练目标,(iii)从最先进的预训练多模态方法到统一架构,以及(iv)多模态任务类别和可能的未来改进,以便更好地进行多模态学习。此外,我们为新研究人员准备了一个数据集部分,涵盖了大多数用于预训练和微调的基准。最后,探讨了主要的挑战、差距和潜在的研究主题。
1 引言
多模态系统利用两种或更多输入模态,如音频、文本、图像或视频来产生一个可能与输入不同的输出模态。跨模态系统,作为多模态系统的一个子部分,利用一个模态的信息来增强另一个模态的性能。例如,一个多模态系统会使用图像和文本模态来评估情况并执行任务,而跨模态系统会使用图像模态来输出文本模态[1, 2]。音频-视觉语音识别(AVSR)[3]、检测模因中的宣传[4]和视觉问答(VQA)[5]是多模态系统的例子。多模态表征学习技术通过分层处理原始异构数据来减少不同模态之间的异构性差距[6]。来自不同模态的异构特征以上下文信息的形式提供额外的语义[6]。因此,可以通过多种模态学习互补信息。例如,视觉模态可以通过提供唇部运动[7]来帮助语音识别。最近的深度学习方法变体通过将不同模态映射到标准表示空间来解决经典的多模态挑战(相关性、翻译、对齐、融合)。
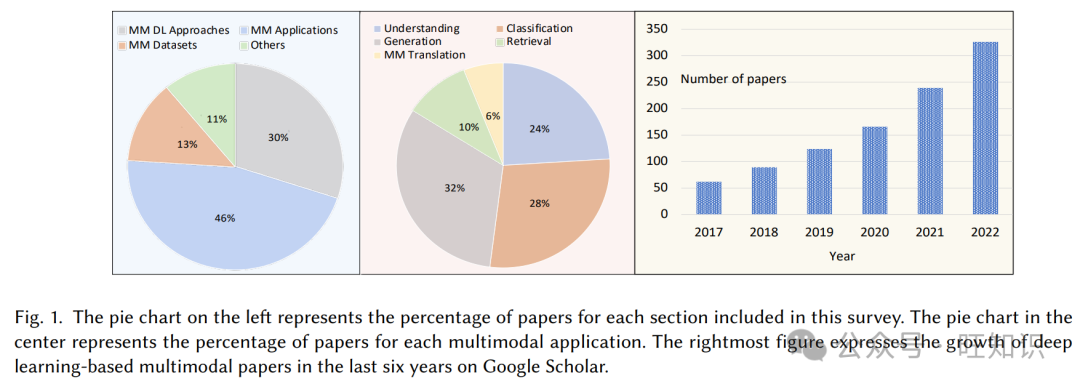
过去,许多特定任务的深度学习策略显著提高了各种多模态任务的性能[8]。最近,自然语言处理(NLP)和计算机视觉(CV)的预训练和微调方法引起了广泛关注,主要是因为它们语义丰富的表示和大规模公共模型的可用性[9]。本研究总结了多模态表示的任务特定方法的流程。我们讨论了使预训练模型在各种多模态或跨模态下游任务上变得健壮所需的预训练类型和前文任务。我们展示了大多数预训练方法利用变换器,导致统一架构的出现。这些模型能够处理所有模态跨不同下游任务,减少了对个别任务特定微调的需求,从而降低了计算复杂性和处理时间[10]。此外,对下游任务的评估、多模态基准、广泛的多模态应用范围,包括通过结合视觉和音频模态而丰富的NLP任务,例如情感分析、文档理解、假新闻检测、检索、翻译和其他推理应用,在本综述中得到了全面呈现。图1展示了包含在本综述中的深度学习多模态论文的分类百分比。条形图显示了过去六年基于谷歌学术的深度学习多模态方法的发展和可用性。
2 背景 - 多模态架构的先进演变
多模态研究的概念最初受到音频-视觉语音识别(AVSR)领域的启发[11],在该领域中,视觉和听觉的良好对齐是一个基本要求。来自AVSR研究的鼓舞人心的结果促使研究社区将这种方法的应用扩展到其他多模态任务,例如内容索引和检索[12]、视频摘要[13]和镜头边界检测[14]。在2000年代初,AMI会议[15]和SEMAINE[16]语料库的创建是为了理解人类的多模态行为和人际互动的动态。这些基础数据集不仅导致了音频-视觉情感挑战(AVEC)[17]的诞生,而且后来推动了其扩展到自动检测抑郁和焦虑的领域[18]。随着时间的推移,多模态方法已经发展,使得能够同时处理多种模态,如语音、视觉和文本[2, 19]。最新的类别包括来自多媒体源的数据,这些数据的复杂性超出了两三种模态的复杂性。这些复杂的多模态方法激励研究人员通过更有效的策略,如预训练和微调,来解决相关挑战。这些方法已经发现与传统任务特定框架相比提供了更优越的性能。先进的方法特别擅长处理复杂的多模态任务,表现出比以往模型更优越的性能。
多模态方法的主要障碍在于理解多种编码方案之间的关系,这通常被认为是学习表示中的异构性差距[20]。多模态学习系统中的融合模块有助于通过关联不同模态的相似语义来减少异构性差距,这一策略已被证明可以提高大多数任务的性能[21]。最近的研究表明,深度学习方法由于其强大的学习能力,有效地理解和处理表示[22]。深度学习的一个关键优势是其能够分层学习表示,作为通用学习而不需要额外的结构信息。这些因素使得深度学习成为多模态表示学习的一个极其兼容的方法。
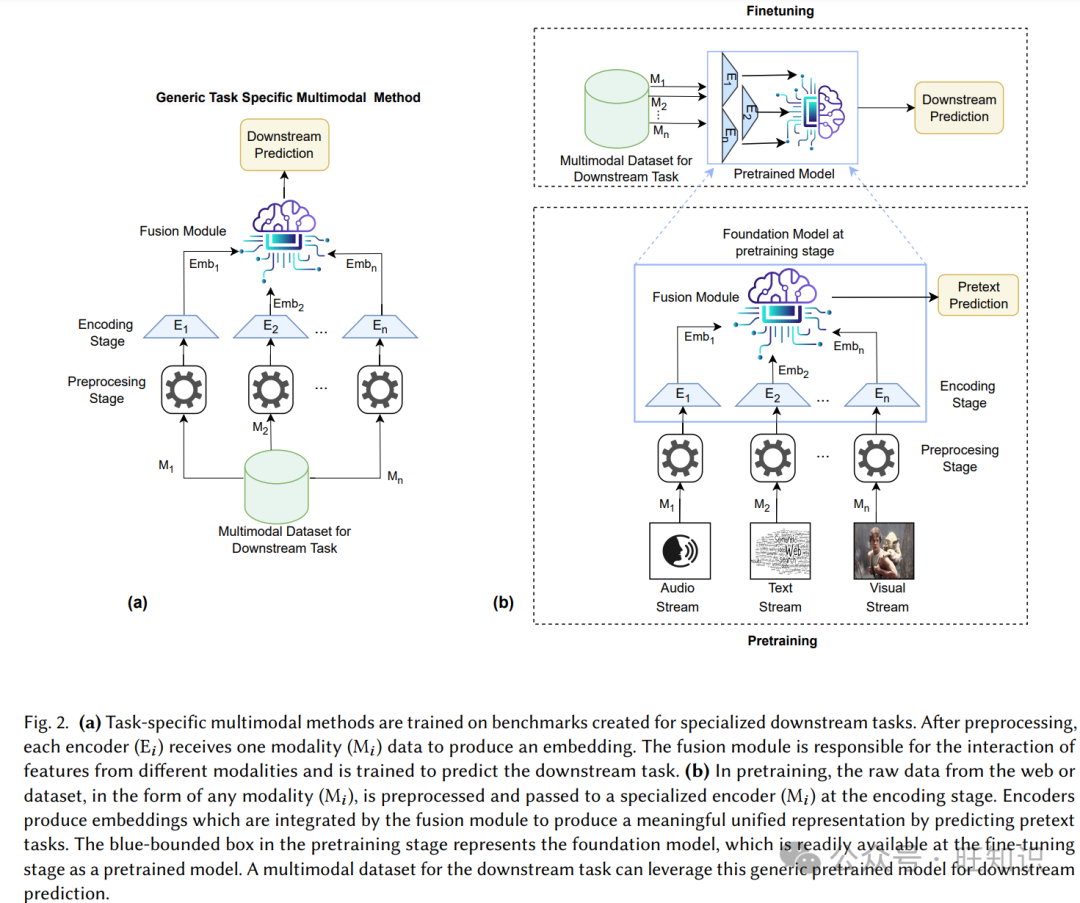
早期的任务特定多模态方法被训练来只解决一个多模态任务。图2(a)广泛描述了任务特定多模态方法的流程。例如,在VQA中,通常基于某种变体的卷积神经网络(CNN)[23, 24]的视觉编码器用于提取视觉特征。同时,文本特征由通常建立在词袋[25]、序列到序列模型[26]上的文本编码块编码,可能带有注意力机制[27]。随后,编码的表示被引导到多模态融合(广泛探索多模态学习),它融合并构建不同模态特征之间的交互以产生统一的表示[28]。这些多模态融合方法已经演变为(i)简单融合,通过连接、逐元素求和或乘积来融合特征[29],(ii)模态间注意力,对齐不同模态的特征并构建更信息丰富的联合表示[30],(iii)模态内注意力,通过形成图形表示在模态内部发展关系推理[31],(iv)变换器,通过同时关注其他模态和同一模态内的关联区域来利用上述技术[32]。由于变换器学习并建立不同模态之间的复杂交互[33, 34],它们被视为通用多模态预训练方法的结构基础。
随着大规模数据集和计算资源的可用性,预训练范式在各个领域,包括文本[35]、视觉[36]和语音[37]中产生了高效的性能。这激发了对多模态预训练的兴趣,允许使用半监督、自监督或无监督方法处理原始数据(包括标记和未标记的数据)。如图2(b)所示,每种模态都由专用编码器处理以生成嵌入。然后,这些嵌入被传递到专门训练用于多模态前文任务的融合模块。通过专用编码器生成的上下文丰富的嵌入允许融合模块学习不同模态之间更健壮的关联。这反过来可以导致在下游任务中更准确的性能,因为模型变得擅长处理复杂的多模态数据。在多模态学习的微调阶段,预训练模型作为灵活的主干,使用特定多模态数据集针对目标任务进行进一步训练。通过微调,模型调整其学习到的表示,以更好地适应任务特定数据集中存在的不同模态之间的关系和交互。因此,预训练的丰富、通用知识被转化为任务特定的洞察力,提高了模型在下游任务上的性能。图2清楚地说明了多模态学习的两种关键方法:任务特定方法和预训练-微调范式。它们主要通过输入数据的类型来区分:任务特定方法利用专门的基准,而预训练可以使用任何类型的数据。任务特定方法是直接针对下游任务进行训练的,而预训练是针对前文任务进行的,并产生一个通用的预训练模型,该模型可以适应各种下游任务,从而节省了与单独训练每个模型相关的计算时间和复杂性。
2.1 与以往综述的比较
许多综述已经广泛研究了多模态性,特别关注多模态学习技术、预训练技术、模型特定拓扑和任务特定应用。表示、相关性、融合、翻译和共学习是多模态学习的基本组成部分,在[2, 6, 7, 38, 39]中进行了调查。在[2]中,建立了多模态学习组成部分的分类。此外,[7]通过提供计算机视觉领域的视角,为这些组成部分做出了贡献。[6]和[39]的工作仅检查了表示和融合,分别提出了它们的数学框架、架构、挑战和前景。尽管多模态学习组成部分在理解和处理不同模态方面很重要,但这些综述是专注的,未能提供一个全面的多模态性描述。
视觉-语言预训练目标、策略、架构和数据集在[28, 40–42]中得到了广泛研究。多模态预训练综述[41]专注于图像-文本任务,因为它回顾了原始图像和文本的编码方法以及交互的架构。虽然所有预训练综述都涉及下游任务,但对最新框架的细节程度有限,并且对多模态领域内不同应用的覆盖不足。研究[43]、[1]和[44]检查了多模态深度学习模型,它们分别根据[1]中涉及的模态和[44]中的主要任务进行了介绍。[43]的工作提出了寻找最优多模态架构和跨模态正则化的方法。各种作品从特定应用的角度评估了多模态学习,例如视觉问答[45]、生物医学应用[46]、事件检测[47]、情感分析[48, 49]和对象检测[50]。
我们的工作扩展了现有研究,提供了对任务特定方法和多模态预训练发展的更全面的探索。我们详细阐述了对大规模预训练多模态模型的预训练任务的重要性及其在各种下游任务中的健壮性。此外,我们对预训练基准数据集进行了编目,涵盖了它们的规模、包含的模态和目标任务。本综述还调查了统一架构的进步,并提出了各种最新技术的比较分析。我们扩展了对包括视觉、语言、音频、医疗和特定NLP任务在内的广泛应用的探索。
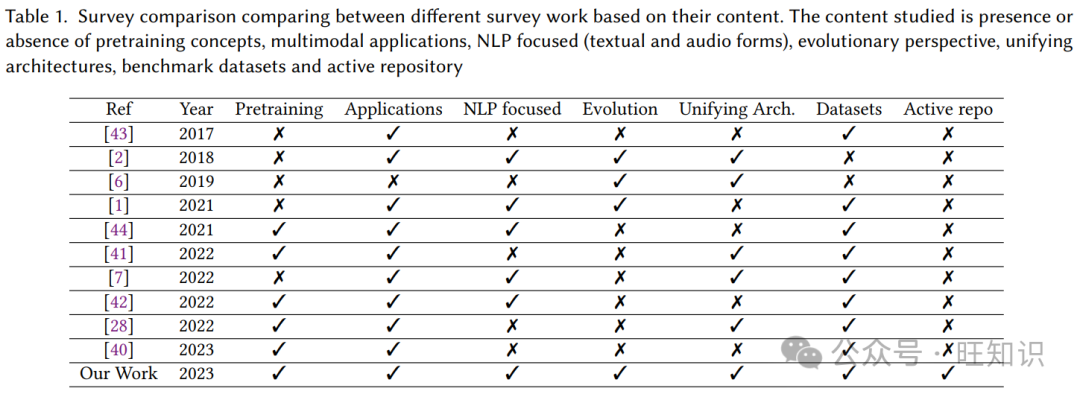
表1提供了我们工作与其他综述的比较视图,突出了预训练概念、下游应用、NLP应用、进化视角、统一架构、数据集和活动存储库的包含情况。这种广泛的方法有助于全面了解多模态学习,通过揭示有效处理多模态技术的指导,为未来研究提供指导。
3 多模态深度学习方法
本节探讨了多模态架构,分为任务特定和预训练-微调架构(图2)。小节3.1回顾了任务特定方法,最近发展成大规模预训练方法。小节3.2概述了预训练过程,包括前文任务和多模态任务的最新技术(SOTA)框架。小节3.3比较了SOTA方法的结果,而3.4列出了使用的缩写词。
3.1 多模态任务特定方法
多模态表示学习提高了深度学习(DL)模型的鲁棒性,因为存在互补特征。本节描述了可以一般分类为编码器-解码器基础、基于注意力和基于强化学习的模型的任务特定多模态方法。
3.1.1 编码器-解码器基础模型。
编码器-解码器模型,如级联CNN-RNN和RNN-RNN,通过语义丰富的潜在表示将输入数据转换为输出。Hu和Wu[51]提出了一个级联循环神经网络(CRNN),用于学习图像-文本交互。这使用了VGG16网络作为编码器和堆叠门控递归单元(SGRU)作为解码器。Ji等人[52]建议了一个全局增强变换(GET)网络,采用Faster-RCNN和ResNet-101作为编码器。GET网络在MS-COCO数据集[53]上超过了CRNN,具有更高的BLEU分数。
自编码器[54],是一种使用无监督学习的编码器-解码器模型,构建潜在表示以重构原始数据点[54]。在[55]中,为处理音频和视频模态构建了一个基于自编码器的多模态架构,输入到传统的编码器-解码器架构中。
3.1.2 基于图的模型。
在多模态学习中,融合模块促进了不同模态特征之间的相互作用,已成为一个关键和中心组件[56]。任务特定方法广泛采用基于图的方法进行融合任务[28]。图神经网络(GNN)在处理多模态数据时表现出卓越的鲁棒性,通过利用其他模态的信息来补偿一个模态中的不完整或嘈杂输入[57]。在多模态任务中,GNN能够通过迭代邻域聚合来封装局部和全局上下文[58]。用于神经机器翻译(NMT)的基于图的多模态融合编码器[59]在Multi30K数据集上表现优越。该方法构建了包含两种类型的节点的图:句子中的所有单词都包括为文本节点,而由Stanford Parser识别的名词由视觉定位工具包检测为视觉节点。此外,使用了两种类型的边:模态内边连接同一模态中的节点,模态间边连接不同模态中的相应节点,捕获多模态数据的语义关系。这些图通过多个基于图的多模态融合层进行处理,这些层迭代促进语义交互并学习节点表示,最终为解码器产生基于注意力的上下文向量。同样,Gao等人[60]通过设计多模态图神经网络(MM-GNN),比预训练的词嵌入更好地解决了场景文本歧义问题。VQA-GNN[61]将图像级信息和概念知识整合到统一的多模态语义图中,用于联合推理。该模型的有效性通过在VCR任务中的顶级表现得到证明,超过了以前的模型,并且值得注意的是,它还为视觉和文本知识在视觉问答任务中提供了开创性的跨域可解释性。VQA-GNN[61]将图像级信息和概念知识整合到统一的多模态语义图中,用于联合推理。该模型的有效性通过在VCR任务中的顶级表现得到证明,超过了以前的模型,并且值得注意的是,它还为视觉和文本知识在视觉问答任务中提供了开创性的跨域可解释性。
3.1.3 基于注意力的模型。
注意力机制通过检查信息流、特征和资源来改善模型学习。这些模型帮助网络处理长时间依赖性,通过将注意力分配给重要信息并过滤所有不必要的或不相关的刺激。Jiang等人[62]最近通过注意力权重门(AWG)模块和自门控(SG)模块将注意力概念应用于多门控注意力网络(MGAN)流程。此外,MGAN提取并利用了网络中的内部对象关系[62]。另一种基于注意力的变体在注意力引导的多模态相关性(AMC)[63]中进行了探索。注意力机制应用于模态而不是向量中的语义上下文,根据系统所需的查询变化每个模态的重要性。AMC的应用已经应用于搜索日志,其中用户输入图像和文本进行搜索,系统确定哪个模态更有价值。
3.1.4 基于强化学习的模型。
强化学习模型通过环境感知代理与其环境之间的试错交互来学习,平衡利用先前知识和探索新行动。算法“强化”产生高奖励的行动。与监督学习不同,它不需要标记数据。这种概念在[64]中与深度学习集成,使用基于层次的强化学习(HCL)框架,具有管理者、工作者和批评者等角色。管理者为工作者设定目标,工作者执行行动以实现这些目标,而批评者评估目标完成情况。HCL在将视频模态转换为文本方面超过了基线模型。
随着多模态框架的复杂性增加,进一步的深度学习架构被修改和增强,例如生成对抗网络(GAN)和概率图模型(PGM)[65, 66]。然而,本节中提到的方法在时间和计算资源效率方面面临挑战,因为需要为每个特定任务重新训练。认识到这些挑战,许多研究人员现在将注意力转向预训练框架。这些框架旨在解决和克服任务特定方法固有的限制,减少为不同任务重复训练的需求,从而为未来的多模态表示学习提供了更有效的途径。
3.2 多模态预训练方法
本节涵盖了预训练框架的详细讨论,特别强调多模态预训练,包括预训练类型、前文任务和多模态任务的最新技术(SOTA)方法。早期,自监督学习(SSL)为语言任务的预训练提供了动力[27],后来用于视觉任务并取得了有效的结果[67]。这个概念后来扩展到多模态场景。在大规模标记或未标记数据集上进行预训练,并在任务特定数据集上进行微调,已成为各个领域的一种现代范式[68]。
3.2.1 预训练类型。
Kalyan等人[46]提出了研究人员用来设计和训练大规模模型的不同预训练方法。这些方法包括:(1)从头开始预训练(PTS),使用大量未标记的文本从头开始训练模型,使用随机初始化对语言模型的所有层进行初始化,例如ELECTRA[69]、RoBERTa[70]和BERT[35]。(2)持续预训练(CPT),模型使用现有的预训练模型进行初始化。这种方法减少了所需的计算资源。领域特定任务使用这种方法来缓解目标词汇表短的挑战。BioBERT[71]、HateBERT[72]和infoXLM[73]是CPT的例子。(3)同时预训练(SPT)在[74]中使用。它同时使用领域特定和通用文本进行训练。(4)任务自适应预训练(TAPT)在[75]中使用,需要少量数据。(5)知识继承预训练(KIPT)[76]使用知识蒸馏技术。
3.2.2 预训练任务。
在预训练阶段,解决预定义的或前文任务以学习语言表示。这些任务基于自监督学习,并且足够具有挑战性,可以通过利用训练信号使模型变得健壮,包括:(1)因果语言建模(CLM)是单向的,使用上下文预测下一个词,由GPT-1[77]首次使用。(2)掩蔽语言模型(MLM)通过考虑双向上下文增强表示,并仅消耗15%的标记,由[35]首次应用。(3)替换标记检测(RTD)通过将替换的标记分类为原始或非原始来减轻MLM的预训练挑战(较少的监督信号)[69]。(4)洗牌标记检测(STD)通过利用区分性任务(检测洗牌标记)来减少预训练和微调之间的差异[78]。其他预训练任务包括RTS(随机标记替换)、NSP(下一句预测)、SLM(交换语言模型)、SOP(句子顺序预测),这些任务为多模态预训练建立了基线前文任务。
预训练方法已广泛用于执行NLP下游任务的异常性能。研究人员提出了包括BERT[35]、ALBERT[85]、RoBERTa[70]和T5[86]在内的预训练模型,以学习通用文本表示并提高下游任务的性能。同样,预训练方法也被采用以减少基于视觉的下游任务的时间和计算[87, 88]。同时,预训练范式在多模态数据领域也在取得进展,提高了从跨模态到完全多模态的各种任务的性能。下一节揭示了最近构建的架构,以利用这些丰富的多模态数据。
3.2.3 基于变换器的架构。
最近关于大规模预训练的工作激发了研究社区在多模态任务上的进展[89]。在大规模图像-文本对上的联合预训练的先进方法正在迅速发展,这些方法优于任务特定架构。例如,在ViLBERT[9]中,作者在不同流中预训练了BERT对文本和视觉输入进行预训练,通过共同注意层保持关系。在概念字幕数据集[90]上预训练后,该模型被转移到主流语言-视觉任务,包括VQA、VCR和基于字幕的图像检索,并在任务特定架构上取得了一致的改进。视觉-语言预训练(VLP)以统一的方式被提出[91],它在图像字幕和VQA任务上超过了以前的SOTA。提出的模型遵循共享编码器-解码器架构,并在大规模图像-文本对上以无监督方式进行预训练。他们在VQA 2.0、COCO字幕和Flickr30k[92]字幕上评估了模型。与之前的工作一致,Li等人[93]提出了一种预训练方法,其中使用对象标签作为锚点来增强与配对文本的对齐学习。
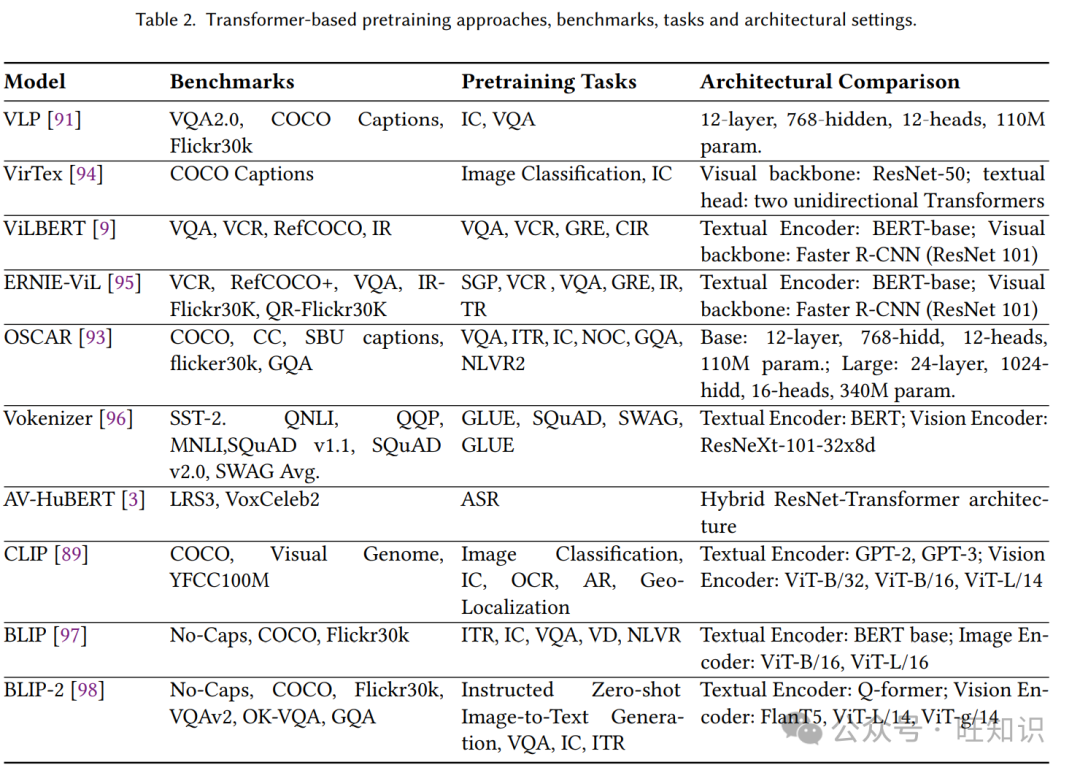
除了上述方法,最近的研究[95]从场景图中提取结构化知识,这有助于学习联合表示作为文本和视觉的语义连接特征。作者在预训练阶段提出了包括对象预测(OP)、属性预测(AP)和关系预测(RP)的场景图预测任务。提出的模型可以学习语义对齐的联合表示。该模型在五个跨模态任务中的有效性得到评估,其中它在VCR任务中领先,表现出3.7%的性能提升。Desai等人[94]提出了VirTex,这是一种数据高效的替代方案,用于监督预训练,它使用字幕作为视觉任务的监督信号。他们对模型进行了联合预训练,该模型包括从零开始为视觉和语言模态构建的卷积和变换器骨干。训练后,文本头部被丢弃,因为主要目标是利用学习到的特征用于后续的视觉任务。此外,Shi等人[3]提出了音频-视觉隐藏单元BERT(AV-HuBERT),它在LRS3基准上从头开始训练,该基准包括语音和视觉特征。所提出的模型的混合架构ResNet-Transformer作为所提出模型的骨干。AV-HuBERT同时从音频和视觉流中提取语音和语言特征,以产生潜在表示。这种表示可以用于预训练基线,例如HuBERT[99],它可以在单一模态上预训练的模型上提高性能。表2根据基准、任务和架构设置,对讨论的方法进行了比较。
Word2Vec[100]、GPT[77]、ELMO[101]、BERT和其他基于SSL的框架在自然语言理解方面表现良好,但不考虑来自视觉世界的接地信息,如Bender等人[102]和Bisk等人[103]所激励的。Tan等人[96]设计的预训练过程,称为Vokenization,考虑了语言标记及其对应的视觉信息,称为“vokens”,作为监督的输入。作者使用小型图像字幕数据集训练了一个vokenizer,可以进一步生成大型语料库的语言vokens。通过视觉监督模型在GLUE、SWAG和SQuAD基准上取得了一致的改进。然而,使用监督方法训练的模型通常严重依赖标记数据,这可能限制了它们的通用性和可用性。因此,为了克服这些挑战,出现了自监督多模态学习方法,如CLIP[89]。CLIP(Contrastive Language-Image Pre-training)在WIT(WebImageText)[89]上进行了预训练,它包含从网络上收集的图像-文本对。与标准视觉模型不同,CLIP在训练阶段联合训练了图像编码器和文本编码器。CLIP在30多个视觉和视觉-语言数据集上的性能进行了基准测试,包括COCO[53]、Visual Genome[104]和YFCC100M[105]等。BLIP(Bootstrapping Language-Image Pre-training)[97],一个统一的视觉-语言框架,使用字幕知识蒸馏来提高性能。它在各种任务上实现了最新技术的结果,包括图像-文本检索、图像字幕、VQA,甚至在文本到视频检索和VideoQA上的零样本性能。BLIP在No-Caps[106]、COCO[53]和Flickr30k[92]上进行了广泛评估。BLIP-2[98],一个改进的视觉-语言模型,基于全面预训练策略,在众多视觉-语言任务上实现了最新技术的性能。BLIP-2展示了广泛的零样本图像到文本能力,包括视觉知识推理、视觉常识推理、视觉对话和个性化图像到文本生成。像它的前身一样,BLIP-2使用相同的评估数据集,并继续实施字幕和过滤(CapFilt)方法。
3.2.4 统一架构。
统一架构旨在接受不同模态作为输入,并在多个任务上训练模型,以减少任务特定参数,作为通用架构。Li等人[107]提出了一个统一模型,用于文本和视觉任务。作者努力创建一个单一的适合的基于变换器的预训练模型,可以在任何模态上进行微调,以适应任何下游任务。基础模型是一个在未配对图像和文本上联合预训练的变换器。预训练基于从教师预训练模型进行知识蒸馏,以更好地进行联合训练和梯度掩蔽,以平衡参数更新。使用的共享变换器可以编码所有模态,以执行不同任务,通过使用任务特定分类器。目标是通过提出一个更通用的模型,减少任务和模态特定参数,并在共享变换器模块中进行最大计算。
UNITER[82]是一个在四个基准数据集上进行大规模预训练的方法。从两种模态中学习联合嵌入,以执行异构下游任务。MLM、MRM(掩蔽区域建模)、ITM(图像-文本匹配)和WRA(词区域对齐)被用作预训练任务。此外,预训练任务使用条件掩蔽实现全局图像-文本对齐。作者的第二个概念是WRA任务的最优传输,以改善图像和单词之间的对齐。Hu等人[108]提出了一个基于多模态学习的统一变换器,用于多任务。所提出的架构为每种模态使用专用编码器,并为每个任务使用共享解码器。DETR[87]用于视觉特征编码,BERT[35]执行文本特征编码。Akbari等人[109]使用对比学习在多模态数据上训练变换器编码器,同时处理音频、文本和视频。
Wang等人[110]提出了一种“一劳永逸”(OFA)方法,通过基于统一词汇表(适用于所有模态)的序列到序列框架统一任务和模态。OFA表示不同模态的数据,在形成统一输出词汇表时将图像和文本离散化。他们提出了一个统一模型应该支持的三个质量,以维持任何模态的多任务处理:(1)任务不可知:手工制作的基于指令的学习用于实现这一属性。(2)模态不可知:使用全局共享的多模态词汇表使其模态不可知。(3)任务全面性:在各种单模态和多模态任务上进行预训练,以实现任务全面性。变换器是编码器-解码器统一网络的骨干,用于预训练、微调和零样本任务。它考虑了多模态性和多任务性,使其更通用于看不见的任务。OFA在多模态和基准测试上超过了UNITER、UNIMO和其他最新技术。值得注意的是,OFA在RTE和RefCOCO0+上取得了最高分,超过了任务特定和统一架构。具体来说,OFA的结果表明,大规模多模态预训练方法可以与自然语言预训练的最新技术竞争,用于理解和生成任务。此外,OFA在领域外任务上超过了Uni-Perceiver,例如单句和句子对分类。
InstructBLIP[112]是一个通用的视觉-语言模型,已经在众多基准测试上实现了最新技术,零样本性能。InstructBLIP是一个视觉-语言指令调整框架,包括图像编码器、大型语言模型(LLM)和Q-Former[98]。在其评估中,InstructBLIP使用了两个LLM:FlanT5[113]和Vicuna[114]。评估指标包括11个任务,涵盖28个数据集,包括图像字幕、视频推理、视觉对话QA、知识接地图像问答、视频问答、图像字幕阅读理解、图像问题生成、图像分类和LLaVa-Instruct-150k,一个包含视觉对话、复杂推理和详细图像描述的基准。
3.3 讨论
大多数多模态方法使用变换器作为骨干。这些架构在大多数视觉任务上超越了CNN,因为自注意力在低级阶段专注于全局上下文学习。然而,大规模多模态架构的泛化在很大程度上取决于预训练目标、学习技术和基准的性质,如本综述所示。
VLP[91]被认为是特定于联合视觉-语言多模态任务(特别是生成和理解)的首个最新技术。同样,VirTex在多模态任务上显示了最新技术的性能[94]。ViLBERT[9]在VQA和RefCOCO+上标记了最新技术,差距很大。AV-HuBERT[3]在音频基准上使用了音频-视觉表示(用于仅音频语音识别),并实现了40%的相对WER降低。ERNIE-ViL[95]在5个跨模态下游任务上实现了最新技术,并在VCR排行榜上以3.7%的绝对改进位居第一。OSCAR[93]在六个成熟的视觉-语言理解和生成任务上创造了新的最新技术。Vokenizer[96]展示了在多个语言任务上一致的改进。在相似的基准上进行微调提供了出色的结果,尽管这需要更多的参数、时间和资源。许多研究人员正在通过提出统一架构来解决这些挑战,以处理多个模态和相同的主干进行多任务处理。如表3所示,这些通用模型可以在不同下游任务上共享参数,避免为每个任务进行广泛的预训练或微调。
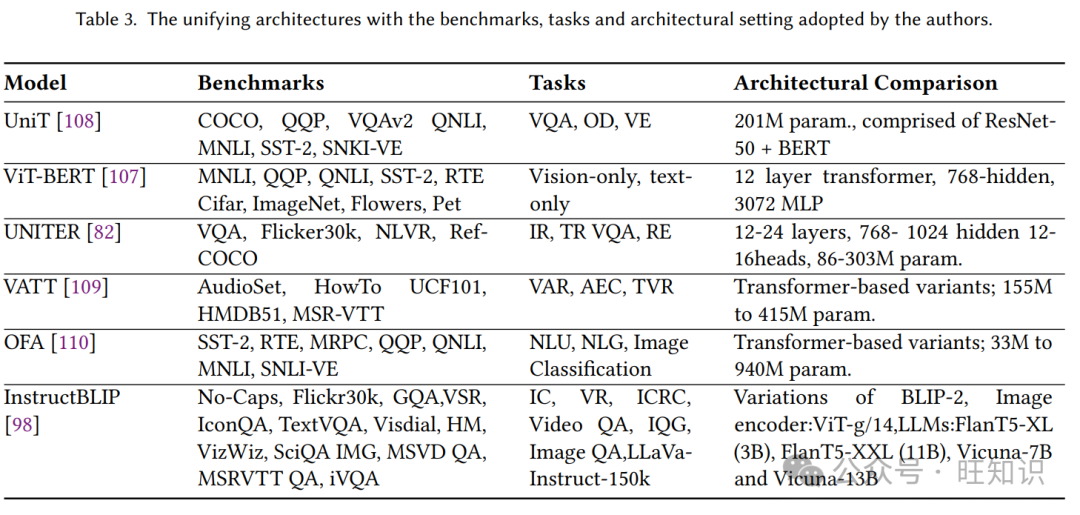
尽管统一架构不是专门为特定任务设计的,但它们显示出有竞争力的结果。
观察到,如果考虑不同模态之间的强对齐和对应关系,则以相关方式进行预训练可以提高性能。在多模态上训练的模型也在单模态任务上表现出色,例如ViT-BERT[107]在视觉任务上超过了ViT。然而,由于微调时数据量小,特别是在RTE数据集上,ViT-BERT未能超过BERT,后者仅针对特定任务进行训练。同样,联合训练的基线结果比跨模态微调的结果更好,后者面临预训练目标和下游任务不匹配的挑战。ViT-BERT在文本和视觉任务上分别取得了83%和89%的平均分数,使其成为具有86%平均分数的中等选项(参数少于UniT)。作为通用模型的UniT[108]在所有任务上取得了有希望的结果,共享参数。然而,UniT未能超过专门针对特定任务训练的VisualBERT或BERT。较小的批量大小和较高的学习率分别导致性能降低和发散问题。
UNITER-large[82]模型在所有基准测试中都取得了可比的性能,但消耗了303M参数。UNITER-base模型在86M参数上表现良好,除了VQA。VATT[109]在所有指标上都优于基于CNN的方法,用于音频事件识别和视频动作识别任务。此外,它还为文本到视频检索提供了有竞争力的结果。作者引入了DropToken策略,该策略通过减少计算复杂性来替代维度和分辨率降低,以缓解冗余挑战。此外,基于噪声对比估计和多实例学习的多模态对比学习用于在投影到共享空间后对齐视频-音频和视频-文本对。OFA[110]在VQA和SNLI-VE上超过了UNITER、UNIMO和其他最新技术。值得注意的是,它在RTE和RefCOCO0+上取得了最高分,超过了任务特定和统一架构。具体来说,OFA的结果表明,大规模多模态预训练方法可以与自然语言预训练的最新技术竞争,用于理解和生成任务。此外,OFA在领域外任务上超过了Uni-Perceiver,例如单句和句子对分类。
InstructBLIP[112]提出了一个新颖的指令调整框架,用于通用视觉-语言模型。他们提出的方法在多个基准测试上实现了最新技术的性能,并具有强大的评估协议。此外,InstructBLIP展示了作为下游任务微调的高级初始模型的潜力。
3.4 缩略语
本节包含表格中使用的所有缩略语。AEC:音频事件分类,自动驾驶:自动驾驶,AR:动作识别,AVSS:音频视觉语音合成,CIR:字幕到图像检索,CMR:跨模态检索,ED:事件检测,EL:实体标注,EQA:具体现世问题回答,GR:手势识别,GRE:生成指代表达,IC:图像字幕,ICRC:图像字幕阅读理解,IE:信息提取,IQG:图像问题生成,IR:图像检索,IS:室内分割,ITR:图像到文本检索,LaVa-Instruct-150k:包括视觉对话、复杂推理和详细图像描述,MML:多模态学习,MMSA:多模态情感分析,NLG:自然语言生成,NLU:自然语言理解,NLVR:自然语言视觉识别,OCR:光学字符识别,OD:对象检测,RE:指代表达,SSS:声音源分离,TD:文本检测,TR:文本检索,TVR:文本到视频检索,VAC:视频动作识别,VAR:视觉到音频检索,VC:视频字幕,VCR:视觉常识推理,VD:视觉对话,VE:视觉蕴含,VG:视觉生成,VLP:视觉语言预训练,VQA:视觉问答,VR:视频推理,VU:视觉理解。
4 多模态应用
本节介绍了通过深度学习架构增强的多模态应用的分类细节,如图3所示。多模态任务分为主要类别:理解、分类、检索、生成和翻译。讨论了每个多模态应用的最佳架构的基准、评估指标、描述和比较。
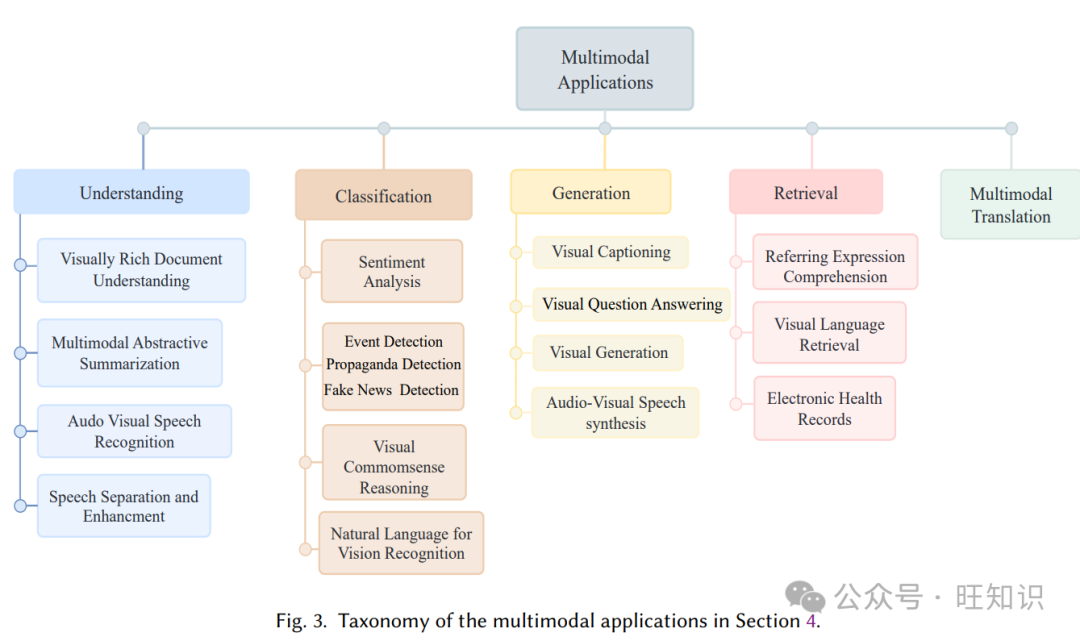
4.1 理解
理解文本、语音和视觉是基于AI系统的最重要和主要任务。从不同媒介(文本、图像、语音)中提取相关信息、识别和识别实体是其子任务。通过理解获得的信息直接或间接地有益于许多下游任务。
4.1.1 视觉丰富的文档理解。
理解具有结构化信息的视觉丰富文档对于不同应用很重要[115]。与传统的信息提取方法不同,视觉丰富的文档理解考虑了视觉布局和文本。LayoutLMv2[116]预训练了一个变换器,通过整合和对齐布局、文本和视觉信息,在预训练阶段从不同模态中学习。LayoutMv2使用了超过100亿份文档来预训练一个模型,该模型在文档理解任务上超过了最新技术。最近,Li等人[117]提出了StrucTexT,通过自监督方式预训练变换器,参数更少,得分更高。公共可用的下游任务基准数据集是SROIE[118]和FUNSD[119]。LayoutLMv2在SROIE和FUNSD上分别取得了97%和84%的F1分数。StrucTexT在SROIE和FUNSD上分别取得了96.88%和85.68%的F1分数。
Gu等人[120]发布了LayoutLMv2[116]的改进版本XYLayoutLM。他们提出了增强XY Cut来捕获作为布局信息的阅读顺序,这在以前被忽略了。此外,输入序列的可变长度通过DCPE(扩张条件位置编码 - 受CPE[121]启发)处理,它为文本和视觉输入分别创建了1D和2D特征,用于卷积。该模型在XFUN[116]基准的SER(语义实体识别)和RE(关系提取)任务上取得了成功。
4.1.2 多模态抽象摘要。
这项任务从互联网上获取大量多模态内容(视频、图像和相应的文本),并提取关键信息以生成摘要[122]。Palaskar等人[123]使用多源seq2seq和层次化注意力生成摘要,该摘要整合了不同模态的信息。同样,提出了一个多阶段融合网络,建立了不同源模态之间的交互。最近,提出了一种方法[124],利用视觉模态生成摘要,该方法利用生成预训练语言模型(GPLMs)。在视觉上引导的GPLMs中插入了基于注意力的附加层,以保持视觉整合和文本生成。该模型在How2[125]数据集上进行了评估,该数据集包含2000小时的指导视频,每2000小时包含两到三句话。视觉上接地的变体超过了基线,在基准测试上取得了最高的ROGUE-1、ROGUE-2和ROGUE-L。
4.1.3 音频-视觉语音识别。
音频-视觉语音识别(AVSR)是最早的多模态研究领域之一,它鼓励研究社区通过同时使用听觉和视觉特征来理解语音。视觉特征和语音在理解语音中起着至关重要的作用,特别是在噪音和帮助患有言语障碍的患者方面。大多数最近的模型wav2vec2.0[37]、HuBERT[99]和De-CoAR2.0[126]仅使用音频进行语音识别。唇部运动提供了通过利用自监督来更好地识别的监督信号。
最近发布的音频-视觉隐藏单元BERT(AV-HuBERT)[3]是一个自监督表示学习框架。提到的方法通过利用唇读和ASR学习音频-视觉语音表示。提出的方法在LRS3[127]基准上使用30小时的标记数据(来自433小时)实现了32.5%的WER,并以26.9%的性能超过了以前在31K小时上训练的最新技术[128]。作者还指出,确切的表示在音频任务上执行语音识别,将WER降低了40%。该模型在视觉模态上表现出色,利用AV-HuBERT的上下文化表示。
4.1.4 语音分离和增强。
语音增强(SE)是在嘈杂环境中提取目标说话人语音信号的过程。SE提高了语音质量(声音)和语音可懂度(语言内容)。估计语音中的多个目标被称为语音分离或源分离[129]。以前,这些任务在信号处理下通过统计和数学标准处理[130]。目前,随着监督学习、多模态方法和融合技术的演变,实现了在嘈杂环境中伴随声学特征的说话人的未受影响的视觉特征。
音频-视觉句子提取(AV-SE)和音频-视觉句子分离(AV-SS)系统计算了几个说话人并追踪了他们的面孔。使用检测和跟踪算法来实现高维视觉帧的面孔。通过基于主成分分析(PCA)[131]的主动外观模型来降低维度。通过周等人[132]使用的外观注意力模块实现声源分离,该模块利用单帧视频的分类信息。作者通过将外观嵌入和特征映射相关联来优化模型。声源通过嵌入和特征映射的标量乘积来定位。MUSIC数据集包含由不同乐器组成的YouTube视频,并有背景噪音[133]。该模型在MUSIC数据集上使用标准化评估矩阵进行评估,即信噪比(SDR)、信号干扰比(SIR)和信号伪影比(SAR)。基于注意力的方法超过了Resnet-18和Resnet-50,实现了SDR 10.74、SIR 17.29和SAR 13.04。
4.2 分类
分类是将样本系统地安排到遵循既定标准的组或类别中。视觉、文本和语音的许多任务都属于分类范畴。本研究讨论的主要多模态分类任务包括情感分析、假新闻检测和事件检测。
4.2.1 情感分析。
情感分析是NLP中的核心任务,它提取和分类评论、感受、手势和对特定实体的行为。情感分析理解人们的观点,以便在多个领域中进行有效的决策。以前的研究广泛分析了文本表示,例如[134]、[135]和[136]。然而,由于社交媒体和互联网的使用,情感分析任务从文本模态转移到了另一种模态。陈等人[137]设计了深度学习架构,通过设计两个基于组件的方法(包括浅层融合和聚合部分)从多模态复杂数据中提取情感。浅层融合组件使用注意力机制从不同领域提取上下文信息,聚合部分实现情感词感知融合。提出架构在多模态数据集CMU-MOSI、CMU-MOSEI和YouTube数据集上取得了最高分,超过了其他方法。
4.2.2 事件检测。
通过社交媒体上可用的内容检测事件、趋势或情况变得更加高效和丰富[138]。生成了大量数据,这些数据显著影响了人类的生活、财产和心理[139]。事件检测可以映射到其他现实场景,如紧急管理、灾害检测和主题检测[47]。尽管来自不同视角的数据增强了性能,但挑战也增加了,因为方法必须处理冗余和异构特征。除了CrisisMMD[140]、CrisisNLP和CrisisLex之外,还没有足够大的数据集可用于灾害检测,以使用深度学习架构。对于交通事件检测,陈等人[141]通过整合与交通相关的过滤推文和传感器数据创建了一个多模态数据集。作者在CNN、RNN和mmGAN(多模态GAN)模型上分别取得了84%、83%和87%的F1分数。
4.2.3 检测模因中的宣传。
宣传是一种通信类型,它影响人们的心理,使他们对任何实体保持特定观点或执行某些行动。由于社交媒体的高使用率,它已成为社会和政治问题。包含视觉和文本内容的模因被用作互联网上重要的媒介,以引发这个问题。
Dimitrov等人[4]将这个问题视为多模态和多标签任务,通过检测宣传技巧来检测模因中的宣传。他们发布了一个新的数据集,包含950个模因(包含文本和视觉内容),并用22种不同的宣传技巧进行了注释。以前的数据集在[142]的文档级别、[143]的句子级别和片段级别上解决了宣传问题。SOTA模型在两种方法上进行了实验:(i)单模态预训练和(ii)多模态目标预训练。BERT和ResNet-152在第一种变体中分别训练并使用MMBT(多模态双变换器)通过早期、中期或晚期融合进行融合。ViLBERT和Visual BERT在多模态性质上预训练于概念字幕和MS COCO。ViLBERT和Visual BERT的结果超过了基线和其他变体。结果分析表明,基于变换器的多模态方法是实用的,并产生了有效的结果。
4.2.4 假新闻检测。
假新闻可以使用多媒体在社交媒体上引起恐慌。文本和图像内容误解了事实并操纵了人类心理,导致假新闻迅速传播[144]。多模态架构可以通过寻找模态之间的不匹配来检测假新闻[145]。
在[146]中解决了检测未见和新出现事件的假新闻问题,通过利用对抗神经网络,该网络使用事件判别器来移除事件特定特征并保留事件和模态之间的共享特征。Khattar等人[147]提出了SpotFake,它利用BERT学习文本特征,并使用预训练在ImageNet上的VGG 19来学习视觉特征。他们采用了简单的连接技术来组合从不同模态获得的特征。同样,在[147]中引入了多模态变分自编码器(MVAE),包括编码器、解码器和假新闻检测模块。变分自编码器通过优化观察数据的边际可能性的界限来使用概率潜在变量模型。通过利用从双模态变分自编码器获得的多模态表示,假新闻检测器将多模态帖子分类为真实或虚假。
最近,Wang等人[148]提出了细粒度多模态融合网络(FMFN)来检测假新闻。首先,CNN提取视觉特征,RoBERTa[70]用于获取单词的上下文化嵌入。然后,使用注意力机制在视觉和文本特征之间增强相关性,以融合特征。最后,采用二元分类器对融合特征执行检测。他们的模型在Weibo数据集[144]上通过关注仅包含文本和图像的推文实现了88%的准确率。
4.2.5 视觉常识推理。
视觉常识推理通过将认知、接地和语言推理与识别任务结合起来,执行强大的视觉理解。Zellers等人[149]引入了VCR数据集,包含290k MCQA(多项选择问题答案)问题。作者提出了认知网络,考虑接地和上下文信息进行认知级视觉理解。该模型超过了以前在VQA[25]上开发的SOTA。Song等人[150]提出了知识增强的视觉和语言BERT,利用外部常识知识。这种方法通过边际改进超过了基于BERT的方法和以前的VCR模型。
4.2.6 视觉识别的自然语言。
NLVR(自然语言视觉识别)任务检查提供的一个文本描述与多个图像之间的关系一致性。以前的预训练方法[82, 151, 152]将NLVR视为二元分类器。视觉语言导航是一个类似的任务,代理通过遵循语言指令在真实世界动态中导航。Zhu等人提出了AuxRN(辅助推理导航)[153],基于自监督,观察周围环境中的语义信息。换句话说,模型从环境中学习隐含信息,估计导航,并预测下一个位置。
4.3 生成
在多模态生成任务中,输入模态提供的数据被处理以生成另一种模态或以相同模态的释义。生成类别中隐藏的任务在很大程度上依赖于前面提到的理解和分类任务。图像字幕任务在对输入图像中的物体进行分类后生成文本。同样,文本到图像生成任务在理解输入文本后提出目标图像。
4.3.1 视觉字幕。
视觉字幕是将图像或视频模态转换为相关文本模态的任务。输入是图像像素,输出是语法和语义上有意义的文本。基于图像生成字幕,弥合了图像和文本模态中发现的低层次和高层次语义特征之间的差距。一些图像字幕的最新技术数据集是MS-COCO[53]和Flickr30k[92]。基于CNN和RNN的常规视觉字幕管道包括图像编码器和文本解码器。最近的工作利用了BERT的能力,如[154]中所述。BERT模型[35]最初使用大型文本语料库进行训练,然后使用正确的掩蔽预训练技术对文本和视觉模态嵌入进行微调。Vinyals等人[155]提出了一个基于神经网络的端到端系统,并结合了SOFA子网络,用于视觉和语言模型。本文提出的方法显著超过了以前的方法。2017年,陈等人[156]改进了CNN,并提出了基于图像的SCA-CNN,CNN可以提取:空间、通道和多层。SCA-CNN可以在CNN中结合空间和通道注意力,并在多层特征图中动态调节句子生成上下文。与以前的研究不同,Rennie等人[157]使用强化学习来优化图像字幕系统。他们提出,使用metricSCST(自我批评序列训练)优化CIDEr非常有效。
4.3.2 视觉问答。
视觉问答(VQA)试图通过检索视觉线索来回答语言问题[45]。VQA结合了书面问题和高维视觉图像或视频的信息。问题可能从简单的是非问题到基于知识的和开放式问题,而视觉可能从简单的草图或图像到视频不等。此外,VQA结合了NLP和CV领域的功能,如语言理解、关系提取、属性和对象分类、计数、知识库和常识推理[1]。基线VQA将问题文本和通过循环和卷积神经网络(RNN和CNN)获得的视觉嵌入映射到共同的向量空间。将嵌入表示映射到共享向量空间使VQA能够处理开放式自由形式问题。在文献中,VQA深度学习技术被分类为联合嵌入模型[158]、注意力机制[159]、组合模型[160]、图神经网络(GNN)[60]和知识库模型[161]。还有针对VQA作为研究领域的综述论文,如[45]和[5]。除了综述之外,还有基准测试,如[162]由卡内基梅隆大学(CMU)和[163]提供。基准数据集是VAQ v1.0[5]、VAQ-X[164]和VAQ-CP[165]。
4.3.3 视觉生成。
视觉生成,也称为文本到图像生成,通常使用输入文本生成图像。视觉生成是图像字幕的相反方向。2016年,Reed等人[166]首次提出了基于深度卷积生成对抗网络(GAN)根据文本描述合成图像。训练模型基于DC-GAN,但与传统GAN不同,D的输入增加了真实图像和虚假文本描述对。作者训练了一个CNN来预测风格,使用由生成器G生成的图像。预测的风格可以用于G的组合。本文使用的数据集有:Caltech-UCSD Birds[167]数据集、Oxford-102 Flowers数据集和MS COCO[53]数据集。Xu等人[168]介绍了注意力生成对抗网络(AttnGAN)进行细粒度文本到图像生成。AttnGAN由一个注意力生成网络和深度注意力多模态相似性模型(DAMSM)组成,关注相关单词以描绘特定图像子区域。DAMSM通过细粒度图像到文本匹配损失增强了生成器训练。全面的评估表明AttnGAN显著优于以前的GAN模型。这种方法在CUB[167]和COCO[53]数据集上进行了评估。
4.3.4 音频-视觉语音合成。
Prajwal等人[129]提出了一个模型,该模型在存在噪音的情况下从唇部运动合成语音。作者发布了Lip2Wav数据集,因为以前的工作[169]在小的和有限词汇数据集上进行了评估[127, 170, 171]。设计的数据集使模型能够从未受限制的唇部运动中合成语音。
使用受Tacotron[173]启发的解码器生成高质量语音,该解码器从文本输入产生mel频谱图。它以前一表示中编码的面部嵌入为条件,并且在TIMIT[171]数据集上所有客观指标上都优于以前的工作[174–176]。
4.4 检索
检索系统采用用户输入作为查询,并考虑上下文信息提供最相关结果。多媒体增强的发展形式是已经建立的跨模态任务。
4.4.1 指代表达理解。
在指代表达理解(REC)应用中,表达式用于引用并定位图像中的目标对象。指代表达是特定的,详细描述了对象属性及其与周围环境的关系。因此,需要解决视觉属性、关系和上下文信息。在[50]中,REC监督深度学习架构被分类为一个或两个阶段。在两阶段流程中,第一阶段基于图像生成并列出提议的对象。第二阶段对指代表达进行编码,并计算提议对象与编码指代表达之间的匹配分数。在单阶段流程中,图像和语言特征被连接,并在一步中更快地输入模型。一些用于REC的预训练模型是VL-BERT[177]和ViLBERT[9]。
4.4.2 视觉语言检索。
索引、查询制定、检索和评估是构建信息检索(IR)应用所需的步骤[178]。在索引和查询制定中,文档和用户界面查询分别由其特征表示[178]。然后检索系统映射这两个表示以检索或提取所需信息。检索任务的性能基于召回率和精确度进行评估。在多模态信息检索中,系统搜索具有不同模态的文档,如文本、图像、视频或生理信号和图像。使用超过一种模态可以丰富信息检索过程。多模态信息检索的一个例子是电子健康记录。
4.4.3 电子健康记录。
患者的健康记录包含各种模态,如分类数据、文本、图像,如MRI扫描,或信号,如心电图(ECG)[178]。信息检索系统可以从不同模态提取信息,以报告、呈现和/或预测患者健康状况。例如,监督深度患者表示学习框架(SDPRL)利用不同模态的信息来学习患者表示[179]。SDPRL是在基准数据集MIMIC-III上构建和测试的。陈等人[180]通过提出一种新颖的基于图神经网络(GNN)的多模态融合策略,即“模态共享模态特定GNN”,来解决重大抑郁症(MDD)检测问题。这种方法考虑了心理生理模态之间的异质性/同质性以及模态间/内模态特征,并使用重构网络和注意力机制获得紧凑的多模态表示。同样,引入了多模态图神经网络框架,使用多模态数据(如基因表达、拷贝数变异和临床数据)预测癌症生存[181]。
4.5 多模态翻译(MMT)
由于图像中缺乏足够的特征,视觉模态在机器翻译中被认为只有边缘效益。Caglan等人[182]提出,当源句子缺乏语言上下文时,视觉信息对机器翻译(MT)有益。作者利用退化技术,以颜色剥夺、实体掩蔽和渐进掩蔽的形式,来退化源句子。此外,还提供了不相关的图像(违反语义兼容性),以评估方法对视觉的敏感性。使用基于ResNet-50 CNN的编码器[24]提取视觉特征。多模态注意力神经机器翻译(NMT)受到[183]的启发,从文本和视觉特征中获得上下文向量。Multi30K和flickr30用于训练。MMT的表现优于NMT。作者提出了一种新颖的NMT编码器[60],它采用基于图的方法结合多种模态。这种方法利用这些不同数据类型之间的详细语义连接来增强联合表示的学习。
Su等人[184]引入了一种方法,利用跨模态的语义表示之间的交互,从问答和命名实体识别领域获得灵感。提出了两种基于注意力的模型:一种使用双向注意力机制从文本和视觉特征的交互中学习,另一种结合了共同注意力机制,从文本表示中生成上下文向量,然后使用它来更新文本上下文向量,以获得更多交互信息。这些模型在扩展的Multi30K数据集上进行了评估,显示出比以前的基线更好,无论是否进行预训练。
5 数据集
本节总结了用于多模态模型预训练、微调和评估的基准。据我们所知,我们涵盖了包含图像、文本、视频和音频模态的所有基准。目的是为新研究人员提供有关基准的性质、每个基准中的样本数量、不同任务的可用性以及比较信息的即用信息,如表4所示。MS COCO数据集[53]用于图像识别、图像检测、图像分割和图像字幕。对于数据集中的每张图像,提供了五种不同的描述。该数据集包含91种可轻松识别的对象类型。该数据集包含超过300,000张图像和250万个标记实例。
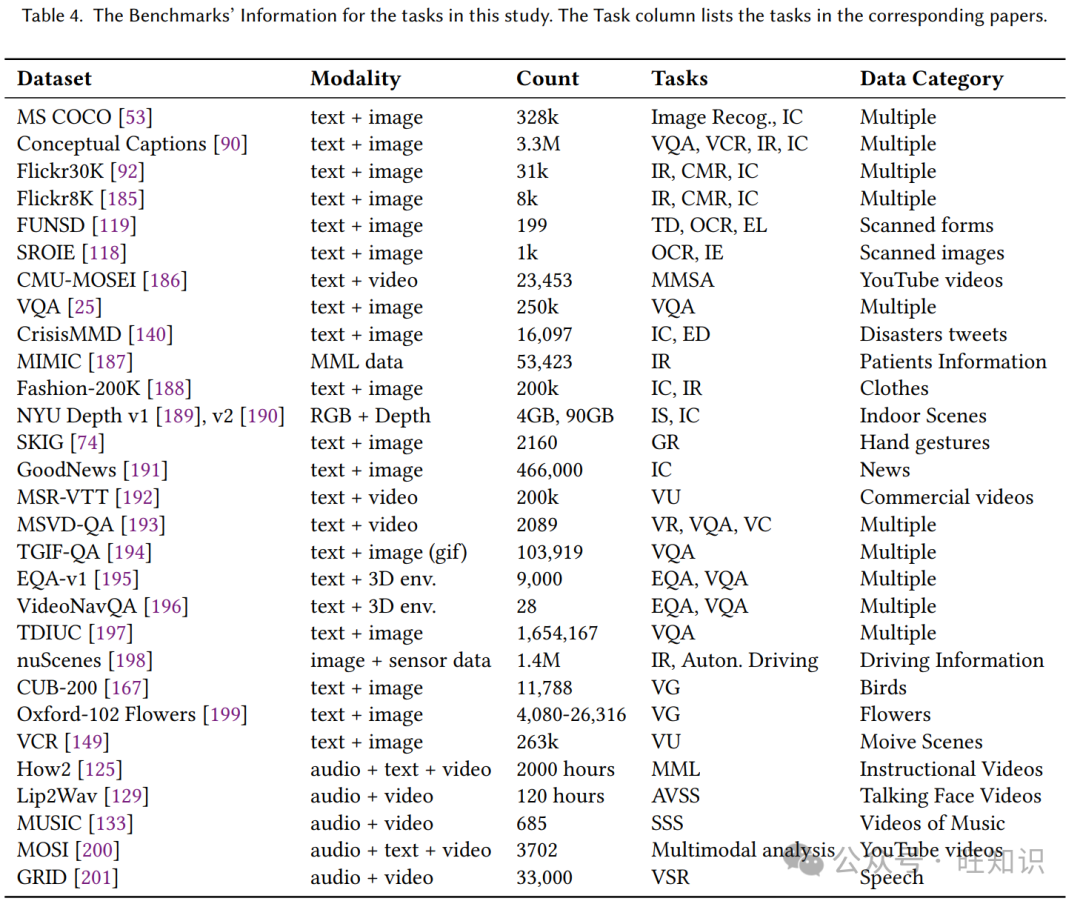
Flickr30K[92]从Flickr收集,每张图像都附有人类注释者提供的5个图像描述。Flickr8k[185]是最小的版本,也从Flickr收集,可以更容易、更快地训练模型。FUNSD[119]是一个小型数据集,包含199份完全注释的扫描表格。FUNSD包含31485个单词、9707个语义实体和5304个关系,旨在提取和结构化表格的文本内容。SROIE[118]包含1000张完整扫描收据图像和注释,用于扫描收据OCR和关键信息提取(SROIE)竞赛。CMU多模态情感和情感强度(CMU-MOSEI)数据集[186]是迄今为止最大的多模态情感分析和情感识别数据集。2018年创建的CMU-MOSEI数据集包含23453个注释视频剪辑。这些剪辑来自1000个独特的YouTube视频,涵盖了250个不同主题。
VQA(视觉问答)[25]是一个大型数据集,包含超过250,000张图像,每张图像至少有3个问题,每个问题有10个正确答案。VQA v1提供了6,141,630个正确答案和1,842,489个合理答案,使模型更难正确回答问题。VAQ-cp(视觉问答变化先验)是VQA v1和VQA v2数据集的拆分。CrisisMMD[140]是一个大型多模态数据集,包含从2017年世界各地发生的自然灾害(如地震、飓风、野火和洪水)中收集的Twitter数据。它具有三种类型的注释。第一种是“信息性”或“非信息性”,以确定它是否有助于人道主义援助。第二种类型是“人道主义类别”,如基础设施和公用事业损害、车辆损害等。最后一种是“损害严重程度评估”,描述损害的严重程度。
MIMIC(医疗信息市场)[187]是一个公开可用的数据集,由计算生理学实验室开发,包含与数千次重症监护病房入院相关的去识别健康数据。目前,它有三个版本:MIMIC-II、MIMIC-III和MIMIC-IV。MIMIC-III包含2001年至2012年间53,423名成人在重症监护室入院的信息,如患者的性别、身高等基本信息,以及血液常规、肝功能等其他重要医院测试数据,以及药物信息。
表4。本研究任务的基准信息。任务列列出了相应论文中的任务。
Fashion200K[188]包含200K时尚图像,每张图像都附有紧凑的属性类产品描述。MIT-Stata Center[202]是一个多模态数据集,包含视觉(立体和RGB-D)、激光和专有数据。该数据集包含超过2.3 TB、38小时和42公里的数据。该数据集还包括机器人在每个实例的地面真实位置估计。这是机器人映射和CV研究的有用数据集。NYU-Depth数据集由RGB和深度相机从Microsoft Kinect记录的视频序列组成。NYU-Depth v1[189]提供约4GB的标记数据和约90GB的原始数据。NYU-Depth v1包括64个不同的室内场景和7种场景类型。NYU-Depth v2[190]包括464个不同的室内场景和26种场景类型。
Sheffield Kinect Gesture(SKIG)[74]是一个手势数据集,包含2160个手势序列。这些手势可以分为10个类别:顺时针圆圈、逆时针三角形、上下、左右、挥手、“Z”、十字、来这里、转过身和轻拍。序列在3种不同的背景和2种照明条件下录制,提供了多样性。GoodNews[191]是一个大型数据集,包含466,000张图像,每张图像都有标题、标题和文本文章。然而,与MSCOCO或Flickr8k等数据集不同,GoodNews包含每个图像的单个真实标题。由专家记者撰写的GoodNews标题比一般字幕数据集的平均长度更长,意味着这些标题更具描述性。
MSR-VTT[192]是一个大规模视频描述数据集:10K个网络视频剪辑,38.7小时和200K个剪辑-句子对。MSR-VTT是从商业视频搜索引擎的257个热门查询中创建的。MSR-VTT中的每个剪辑都注释了大约20个自然句子。该数据集用于视频理解。Microsoft Research Video Description Corpus (MSVD)数据集MSVD-QA包含2089个短视频剪辑的122K个描述(通常少于10秒)。MSVD数据集包含不同语言的描述,如英语、印地语、罗马尼亚语、斯洛文尼亚语等。MSVD-QA是视频检索、视觉问答和视频字幕的基准。
TGIF-QA[194]是一个包含103,919个QA对的大型数据集,这些QA对来自56,720个动画GIF。这些GIF来自TGIF数据集。TGIF数据集基于GIF数据,因为GIF具有简洁的格式和连贯的叙事。TGIF-QA可以用于视觉问答研究。EQA(具体现世问题回答)v1.0[195]包含9,000个问题,来自774个环境。这个数据集中的视觉问题和答案都基于House3D。EQA-v1包含位置、颜色和位置介词问题。
VideoNavQA[196]也是一个用于研究EQA任务的数据集。VideoNavQA包含28个问题,属于8个类别,有70个可能的答案。VideoNavQA中的问题的复杂性远远超过了使用生成方法从视频中提取地面真实信息以生成问题的类似任务。任务指导图像理解挑战(TDIUC)[197]是一个包含167,437张图像和1,654,167个问题-答案对的数据集。TDIUC将VQA划分为12个组成任务,这使得测量和比较VQA算法的性能变得更加容易。这12种不同的问题类型根据这些任务进行分组。
nuScenes[198]是一个大规模的自动驾驶数据集,包含3D对象注释。它也是一个多模态数据集。nuScenes提供140万个摄像头图像,1500小时的驾驶数据,来自波士顿、匹兹堡、拉斯维加斯和新加坡4个城市,发布了150小时的传感器数据(5个激光雷达、8个摄像头、IMU、GPS),详细的地图信息,140万个3D边界框手动注释了23个对象类别等。nuScenes可以用于智能代理研究。nuImages是一个大规模的自动驾驶数据集,具有图像级2D注释。它有93k个视频片段,每个片段6秒,93k个注释和110万个未注释的图像。Caltech-UCSD鸟类数据集(CUB-200)[167]包括200种不同鸟类的11,788张图像。该数据集中的每张图像都有注释,包括围绕鸟类的边界框、鸟类的基本分割以及各种属性的标签。Oxford-102 Flowers数据集展示了102个鸟类类别的图像,每个类别包含40到258张图像。这些图像显示了各种大小、姿势和照明条件。
视觉常识推理(VCR)[149]包含超过212K(训练)、26K(验证)和25K(测试)问题、答案和理由,这些是从110K电影场景中提取的。它广泛用于认知级视觉理解。How2[125]是一个多模态数据集,包含带有英文字幕和众包葡萄牙语翻译的教学视频。How2涵盖了80,000个剪辑(约2,000小时)的广泛主题。Lip2Wav[129]数据集包含120小时的说话面孔视频,涵盖5个说话者。该数据集每个说话者有大约20小时的自然语音,并且每个词汇量超过5000个单词。MUSIC(多模态乐器组合源)数据集[133]包含685个未修剪的音乐独奏和二重奏视频。该数据集跨越11个乐器类别:手风琴、吉他、大提琴、单簧管、二胡、长笛、萨克斯管、小号、大号、小提琴和木琴。MOSI[200](多模态情感水平)数据集包含93个视频和3702个视频片段。该数据集不仅提供情感注释,还提供手动手势注释。GRID[201]包含54名说话者的视频记录,每个说话者有100个话语,总共33,000个话语。
6 未来预测
本节描述了研究人员从以往的研究中观察到的一些技术,这些技术在未来的研究中值得采纳和考虑,以期获得更好的结果并减少计算成本。此外,尽管这些方法在相关研究中已经显示出高效的性能,但它们在最近的研究所中还没有得到充分的考虑或探索。
构建统一模型。先前的研究证明了变换器(transformers)在自然语言处理(NLP)、计算机视觉(CV)和多模态任务中的有效性。最近,研究人员提出了一个统一的架构,其中单一的代理变换器作为主干,能够处理所有模态的多种任务[203]。尽管在下游任务上取得了令人印象深刻的结果,但这些模型在某些任务上仍然无法超越特定任务的模型[204]。对于零样本学习,性能在很大程度上取决于指令。更优化的指令可以带来更满意的结果。研究人员正在尝试解决模型对提示和参数微小变化的敏感性问题。
利用图神经网络(GNNs)进行多模态预训练。Ektefai等人[205]提出了多模态图学习(MGL),以管理多模态数据输入,并为各种下游任务生成一个通用的输出表示。这种方法最初识别跨数据模态的相关实体,将它们投影到一个共享的命名空间中,然后将这些不同的模态结合起来。该过程应用了一个消息传递模块,基于模态内和模态间的邻接矩阵来学习节点表示。最后,通过聚合过程,它生成了适合下游任务的节点、子图或图级表示。
预训练策略。为多模态任务开发一个最佳的预训练目标集合是值得探索的。前文任务直接影响下游任务的性能。在选择预训练目标时,我们需要考虑模态、数据集、网络架构和下游任务。有可能应用有效的阶段性预训练于多模态方法,正如Bao等人[33]成功地为单一模态采用的那样。
用多语言特征增强预训练。多语言预训练的多模态系统较少被检验,因为英语单模态基准被大量实验。UC2[84]、M3P[206]和MURAL[207]通过添加一个单独的编码器来处理多语言或翻译数据,从而利用了多语言特征。基于ALBEF[209]的CCLM[208]提出了一种方法,在零样本跨语言设置中超过了最新技术。简而言之,多语言视角对于增强多模态预训练框架的扩展成功至关重要[210]。
提示调整。提示调整在GPT-2和GPT-3之后受到了关注。这种技术将隐含信息转换为问题或描述性文本,有助于利用语言模型的文本概率。提示学习与预训练目标(MLM)结合,可以解决微调的两个挑战:(i)通过避免为每个下游任务使用不同的参数,减少计算复杂性;(ii)减少预训练任务的表示学习和下游任务之间的差距[211]。这项技术尚未探索用于多模态方法。从技术上讲,提示调整可能会将统一架构转变为更规范化和更通用的版本。
掩蔽阶段。不同模态之间的交互面临着对齐挑战。掩蔽是用于解决对齐问题的有效策略,通过生成文本和图像。掩蔽可以应用于不同阶段,例如输入级别、任务级别,但根据Zhuge等人[212],嵌入级别掩蔽是实现不同模态表示对齐的最有效阶段。如果我们关注音频、视频和文本模态之间的最佳对齐,我们可以学习到更细粒度的表示。
知识注入。有必要将外部知识融合到视觉、语言和音频的多模态表示中,以使模型更加知识渊博,如Chen等人[213]为视觉和语言利用了说明性知识。需要更智能的架构,整合知识库特征,用于多模态预训练和下游任务。知识蒸馏增强了ViT-BERT在所有任务上的性能,提供了比其他变体更有效的学习表示。对于SST-2和IN-1K,准确率分别提高了10%和5%。因此,在设计预训练目标和认知架构时,必须考虑常识、情境知识、层次结构、结构或网络信息。
考虑预期评估。深度学习架构需要高计算资源进行实验。当前的评估方法在广泛的实验后提供了模型的有效性信息。对于大规模多模态方法,必须有评估策略来更早地检查模型[42],以验证模型在支付计算成本之前是否与下游任务兼容。
加速和扩展多模态架构。除了知识蒸馏[214]之外,剪枝和量化尚未探索用于压缩和加速模型,提高跨模态推理速度。受到大型预训练语言模型性能的启发,努力通过广泛的训练和复杂架构在多模态任务上取得成功。然而,需要开发良好的基准和模型,以更高效地处理大规模多模态任务[215, 216]。
包括音频流。最近的多模态预训练研究[41, 42]特别没有考虑音频流。音频可以像文本一样语义丰富,并且可以提供有关说话者的情感和补充信息,包括在多个说话者的情况下的边界数据。对于统一架构,使用音频进行预训练极其重要,因为它使模型能够执行包含音频流的下游任务[217]。然而,随着多种模态的增加,对齐和对应关系的挑战也随之增加。
7 结论
本综述涵盖了深度多模态学习的作用和架构,以有效处理高级多模态任务。我们从基于编码器-解码器、注意力和强化学习的深度学习任务特定多模态架构开始。然后,我们讨论了硬件、大规模计算资源和预训练方法的进步。预训练和微调缓解了多模态和跨模态任务的各种挑战,包括多任务处理。因此,我们讨论了预训练的类型和任务,使训练过程更有效,并总结了最近产生重大影响的SOTA基于变换器的预训练方法。我们进一步展示了研究社区专注于大规模预训练,创建使用变换器作为主干的统一和通用架构,以相同的参数执行更复杂的任务。我们涵盖了不同多模态应用的SOTA多模态架构及其在基准上的性能。应用显示了多模态系统的实用性和实际应用。多模态的可能性是巨大的,但到目前为止,能力只探索了英语。建议未来研究的轨迹是构建其他语言的多模态数据集并构建多语言框架。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









