







 本文介绍了SPEA2算法,它是SPEA的改进版,旨在解决多目标优化问题。SPEA2引入了细粒度适应度分配、密度估计和新的档案截断方法,提高了对帕累托前沿的逼近和解的多样性。通过与SPEA、PESA和NSGA-II的对比实验,SPEA2在各种测试问题上表现出色,尤其在高维度目标空间中。
本文介绍了SPEA2算法,它是SPEA的改进版,旨在解决多目标优化问题。SPEA2引入了细粒度适应度分配、密度估计和新的档案截断方法,提高了对帕累托前沿的逼近和解的多样性。通过与SPEA、PESA和NSGA-II的对比实验,SPEA2在各种测试问题上表现出色,尤其在高维度目标空间中。
文章目录
《SPEA2: Improving the Strength Pareto Evolutionary Algorithm》阅读笔记
摘要 本文提出了一种改进的SPEA2算法,它结合了细粒度适应度分配策略、密度估计技术和改进的档案截断方法。在不同的测试问题上,SPEA2与SPEA以及其他两种现代精英方法PESA和NSGA-II进行了比较,并取得了更好的结果。
1 Introduction
SPEA2与SPEA的区别主要在于:
1)对适应度分配提出了改进,不仅考虑每个个体支配哪些个体,也考虑被哪些个体支配;
2)结合了最近邻密度估计技术,能够更加精确地搜索;
3)引入了新的截断方法,能够保留边界解。
2 Background
2.1 EMO中的问题
帕累托最优集的近似本身涉及两个(可能相互冲突的)目标:最小化到最优前沿的距离和最大化所产生的解的多样性(就目标或参数值而言)。在这种背景下,设计多目标进化算法时有两个基本问题:交配选择和环境选择。第一个问题与如何引导搜索走向帕累托最优前沿的问题直接相关。在给定个体池的情况下,必须根据选择用于后代生产的个体来分配适应值。填充交配池的过程通常是随机进行的。第二个问题涉及在进化过程中保留哪些个体的问题。由于时间和存储资源的限制,只有特定世代中一定比例的个体可以复制到下一代的池中。在这里常用的选择方法是确定性选择。
在大多数EMO算法中上述两个问题都通过以下方法解决,细节不完全相同:
环境选择:除了种群本身,建立一个包含所有能表示非支配前沿解的档案,只有出现以下几种情况时才删除解:i)找到了可以支配他的其他解;ii)超过最大的档案大小并且非支配前沿过度拥挤。这样可以保证不会因为随机性而丢失非支配前沿的部分。
交配选择:每个世代的交配池中的个体通过两个阶段进行评估。首先根据帕累托支配关系对所有个体进行比较,定义了多集合上的偏序。基本上,每个个体支配哪些、受支配于哪些或与哪些个体无关的信息被用来决定在交配池中的排名。然后,通过结合密度信息对该排序进行改进。各种密度估计技术被用来测量特定个体所处的“niche”的大小。
原则上,这两种遴选方案是完全独立的。因此,第一个可以是基于帕累托的,而第二个可以使用加权方法来计算适合度的值。
例如,在PESA(基于Pareto包络的选择算法)中,仅在存储当前非支配集(其子集)的档案上执行交配选择。采用一种类似于直方图的特定密度度量,即根据拥挤程度对档案成员进行不同的采样。生成的子代加入种群,并检查其是否包含在档案中(如上所述)。那些没有进入档案的个体在下一次迭代开始之前被删除。在这种方法下,交配和环境选择在选择标准(当前非支配前沿的成员的拥挤程度)方面是相同的,只是在选择过程(随机和确定性)方面不同。NSGA也类似,先根据帕累托支配的概念将池中的个体分为不同的前沿面,在每个前沿面中根据拥挤度对个体进行排名,在此基础上再进行环境选择和交配选择。将父代与子代共同参与排序并删除较差的一半个体,之后对剩余个体进行二进制锦标赛选择,产生后代种群。注意,与PESA不同,档案不仅可以包含非支配个体,也可以包含支配个体;使用NSGA-II,档案总是完全填满的,而使用PESA,档案可能只填满部分。
2.2 SPEA
由于SPEA是SPEA2的基础,SPEA的简要步骤如下:生成初始种群和空的外部非支配解集(本文中称为档案)后,每个迭代执行以下步骤。首先,所有非支配种群成员被复制到档案中;在此更新操作期间,所有被支配个体或副本(关于目标值)被从档案中移除。如果更新的档案的大小超过预定义的限制,则通过保留非主导前沿的特征的集群技术删除更多的档案成员。然后,将适应度值分配给存档成员和群体成员:
-在档案中的个体
i
i
i的适应度值
F
(
i
)
F(i)
F(i)等于强度值
S
(
i
)
∈
[
0
,
1
)
S(i)\in[0,1)
S(i)∈[0,1),计算方法是用在种群中被
i
i
i支配的个体数除以种群个体总数加1;
-在种群中的个体
j
j
j的适应度值
F
(
j
)
F(j)
F(j)等于所有支配
j
j
j的档案中的个体的强度值
S
(
i
)
S(i)
S(i)之和再加1。
下一步代表交配选择阶段,通过二进制锦标赛从种群和档案的并集中选择个体。这里适应度目标是最小化,因此档案中的个体比种群中的个体有更高的机会被选中。最后,在重组和突变后,旧种群被由此产生的后代种群所取代。
尽管SPEA在很多问题中表现良好,但仍有改进空间,我们将其弱点罗列如下:
1)适应度分配:由相同档案成员主导的个体具有相同的适应度。这意味着在档案只包含一个个体的情况下,所有群体成员都具有相同的排名。结果,选择压力大大降低,SPEA的行为类似于随机搜索算法。
2)密度估计:如果当前世代的许多个体是不相关的,即不相互支配,则根据由支配关系定义的偏序很少或几乎没有。存在两个以上目标函数就很可能发生这种情况,为了更有效地指导搜索,必须使用密度信息,注意只需要在对档案的聚类时使用此信息。
3)存档截断:虽然SPEA中使用的聚类技术能够在不破坏非支配集特征的情况下减少非支配集,但它可能会丢失外部解。因此,这些解决方案应该继续保存在档案中,以便获得良好的非支配解决方案的传播
在下一节中我们将解决这些问题并详细描述改进后的算法——SPEA2。
3 The SPEA2 Algorithm
SPEA2是为了克服上述问题而设计,总体算法如下:
算法1(SPEA主循环)
输入:种群大小
N
N
N、档案大小
N
ˉ
\bar{N}
Nˉ、最大迭代次数
T
T
T
输出:非支配集
A
A
A
Step 1) 初始化:生成初始种群
P
0
P_0
P0,并建立一个空的档案(外部非支配解集)
P
ˉ
=
∅
\bar{P}=\emptyset
Pˉ=∅,记
t
=
0
t=0
t=0
Step 2) 适应度值分配:计算
P
t
P_t
Pt和
P
ˉ
t
\bar{P}_t
Pˉt中个体的适应度值
Step 3) 环境选择:将
P
t
P_t
Pt和
P
ˉ
t
\bar{P}_t
Pˉt中所有非支配解复制到
P
ˉ
t
+
1
\bar{P}_{t+1}
Pˉt+1中,如果此时
P
ˉ
t
+
1
\bar{P}_{t+1}
Pˉt+1的大小已经超过了
N
ˉ
\bar{N}
Nˉ,则利用截断算子减小
P
ˉ
t
+
1
\bar{P}_{t+1}
Pˉt+1的大小;如果
P
ˉ
t
+
1
\bar{P}_{t+1}
Pˉt+1的大小小于
N
ˉ
\bar{N}
Nˉ,用
P
t
P_t
Pt和
P
ˉ
t
\bar{P}_t
Pˉt被支配的解补充
Step 4) 判断终止条件:当
t
≥
T
t\ge T
t≥T,输出
P
ˉ
t
+
1
\bar{P}_{t+1}
Pˉt+1中的非支配解作为
A
A
A
Step 5) 交配限制:在
P
ˉ
t
+
1
\bar{P}_{t+1}
Pˉt+1上用替换的二进制锦标赛选择个体填满交配池
Step 6) 交叉变异:在交配池中应用重组和突变算子生成新的种群
P
t
+
1
P_{t+1}
Pt+1,并将迭代数递增
t
=
t
+
1
t=t+1
t=t+1,转到Step 2。
与SPEA不同,SPEA2使用细粒度的适应度分配策略,该策略结合了密度信息,将在3.1节中描述。此外,档案大小是固定的,即当非支配个体的数量小于预定档案大小
N
ˉ
\bar{N}
Nˉ时,归档由被支配个体填充;而使用SPEA,档案大小可能会随时间而变化。此外,当非支配前沿解的数量超过极限时不再使用聚类方法,而是用类似但不松散边界点的替代截断方法。有关环境选择程序的详细信息将在第3.2节中给出。最后,与SPEA的另一个不同之处在于,只有档案的成员才参与交配选择过程。
3.1 适应度值分配
为了避免被相同的档案中个体支配的个体具有相同的适应值的情况,对每个个体同时考虑支配它的解和被它支配的解。具体来说,
P
t
P_t
Pt和
P
ˉ
t
\bar{P}_t
Pˉt中的每个个体
i
i
i都被分配一个强值
S
(
i
)
S(i)
S(i),表示它支配的解的数目:
S
(
i
)
=
∣
{
j
∣
j
∈
P
t
+
P
ˉ
t
∧
i
≻
j
}
∣
S\left( i \right) =\left| \left\{ j|j\in P_t+\bar{P}_t\land i\succ j \right\} \right|
S(i)=∣∣{j∣j∈Pt+Pˉt∧i≻j}∣∣这里
∣
⋅
∣
\left| \cdot \right|
∣⋅∣表示集合的大小,
+
+
+表示并集,于是每个个体的原始适应度(raw fitness)被定义为:
R
(
i
)
=
∑
j
∈
P
t
+
P
ˉ
t
,
j
≻
i
S
(
j
)
R\left( i \right) =\sum_{j\in P_t+\bar{P}_t,j\succ i}{S\left( j \right)}
R(i)=j∈Pt+Pˉt,j≻i∑S(j)也就是说,原始适应度取决于支配该个体的个体强度值。非支配个体原始适应度为0,如果一个个体的原始适应度很高,说明他被很多个体支配(而支配它的个体又支配很多其他个体)。
下图是SPEA2的
R
(
i
)
R(i)
R(i)的计算示例:

但是这样的适应度分配机制仍存在缺陷,当个体间没有互相支配关系时,该机制失效。因此结合密度信息区分具有相同原始适应度的个体。在SPEA中用到的密度估计是k-近邻法的改编版,这里我们取到第k个近邻的距离的倒数作为密度估计,准确来说,是将每个个体
i
i
i在目标空间中到
P
t
P_t
Pt和
P
ˉ
t
\bar{P}_t
Pˉt中其他个体
j
j
j的距离都计算出并储存在列表中,按升序排列后取第k个对应的距离为
σ
i
k
\sigma _{i}^{k}
σik。这里取
k
=
N
+
N
ˉ
k=\sqrt{N+\bar{N}}
k=N+Nˉ,对于个体
i
i
i密度的定义如下:
D
(
i
)
=
1
σ
i
k
+
2
D\left( i \right) =\frac{1}{\sigma _{i}^{k}+2}
D(i)=σik+21最后将密度与原始适应度值相加即个体的适应度
F
(
i
)
F(i)
F(i):
F
(
i
)
=
R
(
i
)
+
D
(
i
)
F(i)=R(i)+D(i)
F(i)=R(i)+D(i) 适应度分配的运行时间由密度估计(
O
(
M
2
log
M
)
\mathscr{O}\left( M^2\log M \right)
O(M2logM))控制,其中
M
=
N
+
N
ˉ
M=N+\bar{N}
M=N+Nˉ。
3.2 环境选择
SPEA2中的档案更新操作(算法1中的步骤3)与SPEA中的操作在两个方面不同:i)档案中包含的个体数量随着时间的推移是恒定的,以及ii)截断方法防止了边界解被移除。
在环境选择过程中,第一步是将所有非支配个体,即适应度值小于1的个体,从
P
t
P_t
Pt和
P
ˉ
t
\bar{P}_t
Pˉt复制到下一代
P
ˉ
t
+
1
\bar{P}_{t+1}
Pˉt+1中:
P
ˉ
t
+
1
=
{
i
∣
i
∈
P
t
+
P
ˉ
t
∧
F
(
i
)
<
1
}
\bar{P}_{t+1}=\left\{ i|i\in P_t+\bar{P}_t\land F\left( i \right) <1 \right\}
Pˉt+1={i∣i∈Pt+Pˉt∧F(i)<1}如果此时
P
ˉ
t
+
1
\bar{P}_{t+1}
Pˉt+1的大小刚好等于
N
ˉ
\bar{N}
Nˉ,环境选择完成,否则有以下两种情况:
P
ˉ
t
+
1
\bar{P}_{t+1}
Pˉt+1的大小小于
N
ˉ
\bar{N}
Nˉ时,则从
P
t
P_t
Pt和
P
ˉ
t
\bar{P}_t
Pˉt中选择
N
ˉ
−
∣
P
ˉ
t
+
1
∣
\bar{N}-|\bar{P}_{t+1}|
Nˉ−∣Pˉt+1∣个被支配个体复制到
P
ˉ
t
+
1
\bar{P}_{t+1}
Pˉt+1中,选择的方法是:对
P
t
P_t
Pt和
P
ˉ
t
\bar{P}_t
Pˉt中个体的适应度进行排序,选择
F
(
i
)
>
1
F(i)>1
F(i)>1的前
N
ˉ
−
∣
P
ˉ
t
+
1
∣
\bar{N}-|\bar{P}_{t+1}|
Nˉ−∣Pˉt+1∣个个体。
P
ˉ
t
+
1
\bar{P}_{t+1}
Pˉt+1的大小大于
N
ˉ
\bar{N}
Nˉ时,使用档案截断法移除个体,直至
N
ˉ
=
∣
P
ˉ
t
+
1
∣
\bar{N}=|\bar{P}_{t+1}|
Nˉ=∣Pˉt+1∣:如果对所有个体
j
∈
P
j\in P
j∈P,个体
i
i
i都有:
i
≤
d
j
i\le_{d}j
i≤dj,则将个体
i
i
i从
P
ˉ
t
+
1
\bar{P}_{t+1}
Pˉt+1中移除。
i
≤
d
j
:
⇔
∀
0
<
k
<
∣
P
ˉ
t
+
1
∣
:
σ
i
k
=
σ
j
k
∨
∃
0
<
k
<
∣
P
ˉ
t
+
1
∣
:
[
(
∀
0
<
l
<
k
:
σ
i
l
=
σ
j
l
)
∧
σ
i
k
<
σ
j
k
]
\begin{aligned} i\le _dj:\Leftrightarrow \forall 0<k<\left| \bar{P}_{t+1} \right|\ &:\ \sigma _{i}^{k}=\sigma _{j}^{k} \ \lor \ \\ \exists 0<k<\left| \bar{P}_{t+1} \right|\ &:\ \left[ \left( \forall 0<l<k\ :\ \sigma _{i}^{l}=\sigma _{j}^{l} \right) \land \sigma _{i}^{k}<\sigma _{j}^{k} \right] \end{aligned}
i≤dj:⇔∀0<k<∣∣Pˉt+1∣∣ ∃0<k<∣∣Pˉt+1∣∣ : σik=σjk ∨ : [(∀0<l<k : σil=σjl)∧σik<σjk]这里
σ
i
k
\sigma_{i}^k
σik表示个体
i
i
i在
P
ˉ
t
+
1
\bar{P}_{t+1}
Pˉt+1中与其第
k
k
k个最近邻的距离。换句话说,就是依次找出
P
ˉ
t
+
1
\bar{P}_{t+1}
Pˉt+1中距离别的个体最近的个体,如果两个个体距离其他个体的最小距离相等,则考虑次近距离(即
k
=
2
k=2
k=2时),以此类推。如下图所示:
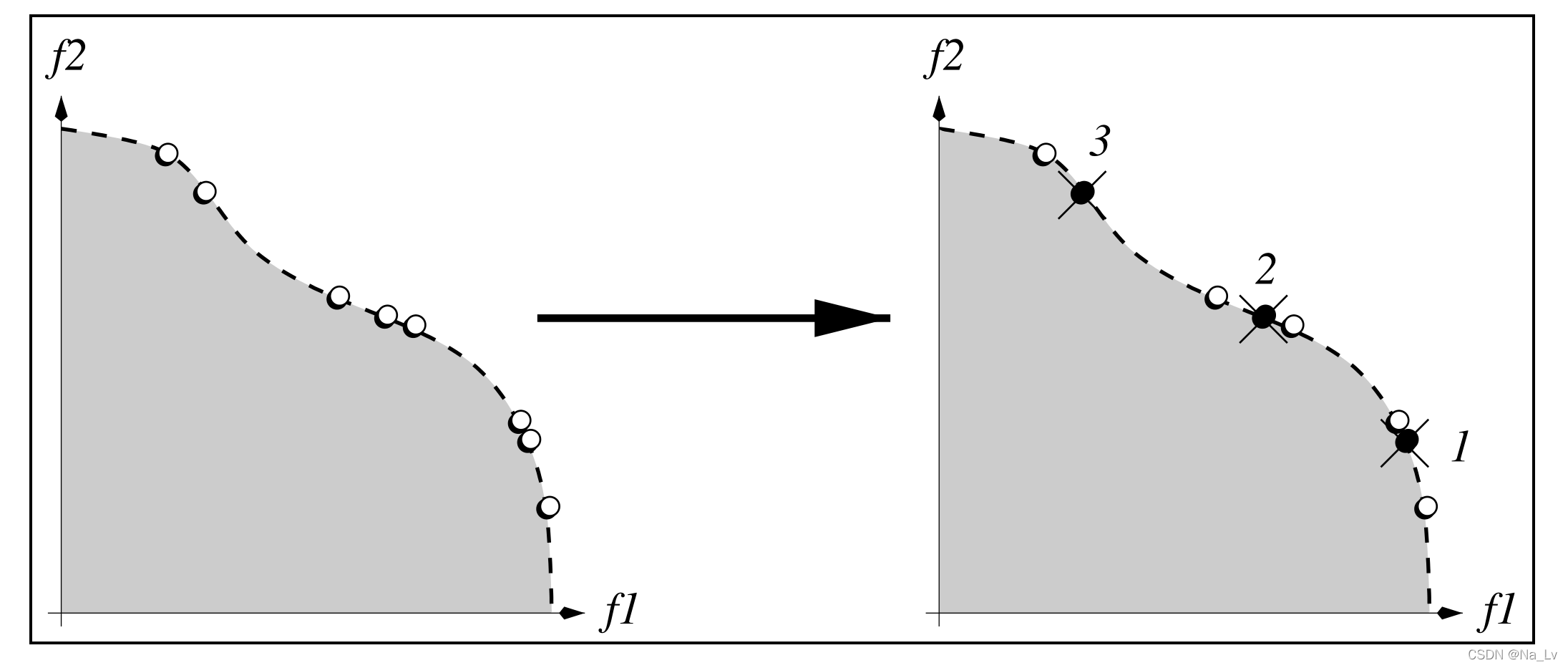
尽管截断算子运行复杂度在最差的情况下可以达到
O
(
M
3
)
\mathscr{O}\left( M^3 \right)
O(M3),但正常情况下个体的第二第三近邻距离不会相同,所以复杂度都低于
O
(
M
2
log
M
)
\mathscr{O}\left( M^2\log M \right)
O(M2logM)。
4 Experimental Design
主要对比的算法是:SPEA2、SPEA、NSGA2、PESA
4.1 测试问题
测试函数包括组合问题和连续问题,如下表所示:

组合问题取自于(Zitzler and Thiele 1999)中的背包问题,一共有750个物品,分别有2、3、4个背包。突变概率为0.06,背包数量分别为2、3、4时,种群大小和档案大小分别为250、300和400。
4.2 性能评估
对于每个算法和每个问题,使用不同的随机种子进行了30次运行。对性能的衡量评估,我们采用基于体积的方法。这里,考虑将原点和乌托邦点之间的部分作为参考–其定义是每个目标中所有项目的利润总和。我们的目标是最小化不被最后一代档案中的任何成员支配的空间。我们认为这是最合适的衡量指标,因为它考虑到了解之间的距离和解的传播(?spread of solution )对于每一次运行,我们测量非支配目标空间随时间的(归一化)大小,这导致每个实验中每个时间步长的样本为30个值。(没懂)
5 Results and Discussion
5.1 连续的测试问题
5.2 复合的测试问题
5.3 总结
在所有测试用例中,SPEA2都比其前身SPEA有了显著的改进,因为它在所有考虑的问题上都取得了更好的结果。SPEA2和NSGA-II似乎在不同的问题上表现得非常相似。在某些情况下,NSGAII有更好的传播,从而在性能评估中表现更好,而SPEA2得到的解有更好的分布,特别是在目标数量增加的情况下。而PESA在某些测试函数上往往难以保留外部解。
然而,看看性能是如何随着时间的推移而发展的,例如随着函数评估的数量而发展,这是非常有启发意义的。对于许多问题,PESA在开始时似乎收敛得更快,这可能是因为它的隐含精英主义强度更高。NSGA-II和SPEA2由于将被支配个体维持在最小的档案大小,在运行后期利用了此增加了解的多样性,从而获得了更广泛的分布和更好的性能。
6 Conclusion
本文我们提出了一种改进的精英多目标进化算法SPEA2,与其前身SPEA相比,它采用了更好的适应度分配策略,并采用了新的存档截断和基于密度的选择技术。将SPEA2算法与SPEA算法以及最近提出的PESA和NSGA-II算法进行了大量的数值比较,并对各种16个连续和组合测试问题进行了验证。
几种算法比较的关键结果是:
1)SPEA2在所有问题上都比SPEA表现得更好;
2)PESA算法收敛速度最快,这可能是因为它的精英主义强度较高,但因为它不总是保持边界解,所以在一些问题上结果较差。
3)SPEA2和NSGA-II的整体性能最好。
4)在更高维的客观空间,SPEA2比PESA和NSGA-II更有优势。
对比研究强调,许多差异只有在目标多于两个的情况下才能显现出来。在高维客观空间中,非支配解的数量迅速增加。这提出了更大的挑战,例如对于存档策略、保持算法应有的收敛特性以及保持解的良好分布。这就是SPEA2设计精确的密度估计的原因。虽然PESA和NSGA-II在最坏情况下的复杂性方面要快一些,但背包问题的结果表明,目标越多,密度估计问题就越重要。
此外,我们显然有必要跟踪随时间推移算法的性能变化,以及跟踪算法的动态行为。具体地说,算法可能在收敛速度上有所不同,或者显示出过早收敛或停滞等影响,这些影响在经过一段时间后的静态分析中是看不到的。


















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









