






今天介绍一个基于本地知识库的问答系统 QAnything,有网易开源,同时也提供 SaaS 在线服务,有一定免费额度。特点是界面友好,简单易用,知识库管理和问答之外,也提供了 Agent、速读、AI写手等能力。
文章主要内容:
-
• QAnything概述
-
• 架构和特点
-
• 开源和商业使用
-
• 用户界面及功能示例
-
• 本地安装
-
• SaaS 服务价格
-
• 相关工具推荐
QAnything概述
什么是QAnything?
Question and Answer based on Anything(QAnything) 是一个本地知识库问答系统,旨在支持各种文件格式和数据库,允许离线安装和使用。用户只需将任何本地存储的任何格式的文件拖放到系统中,即可获得准确、快速和可靠的答案。
目前支持的格式包括(其实我们一般也不关心这块,支持常见的PDF\Word\文本即可,其他格式RAG效果也不好,不兼容的稍微转换下格式即可):
-
• PDF(pdf)
-
• Word(docx)
-
• PPT(pptx)
-
• Markdown(md)
-
• Eml(eml)
-
• TXT(txt)
-
• XLS(xlsx)
-
• CSV(csv)
-
• 图像(jpg,jpeg,png)
-
• 网页链接(html)
主要特点:
-
• 数据安全,支持在整个过程中插拔网线的安装和使用。
-
• 跨语言问答支持,可以自由切换中英文问答,不受文档语言的限制。
-
• 支持海量数据问答,两阶段向量排序,解决了大规模数据检索的性能下降问题;数据量越大,性能越好。
-
• 支持类似Kimi的快速开始模式,无文件聊天模式,仅检索模式,自定义Bot模式。
架构
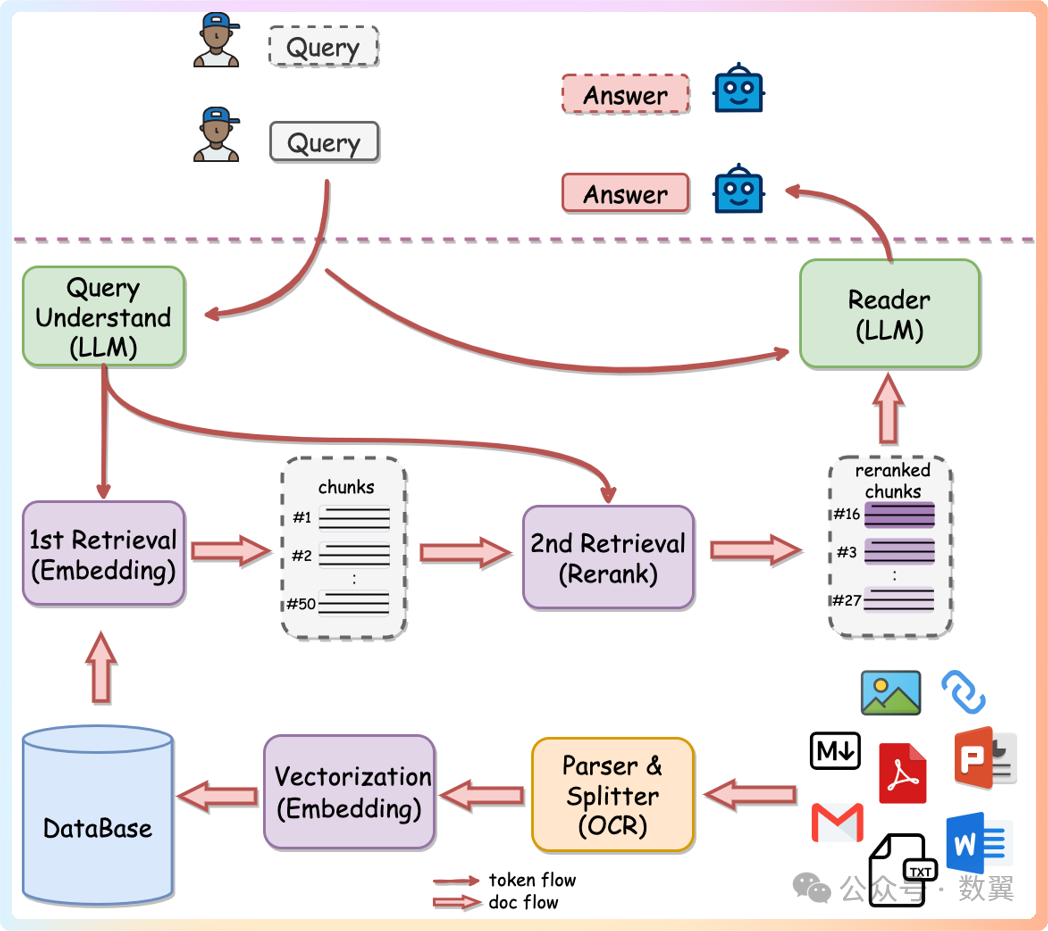
为什么使用两阶段检索
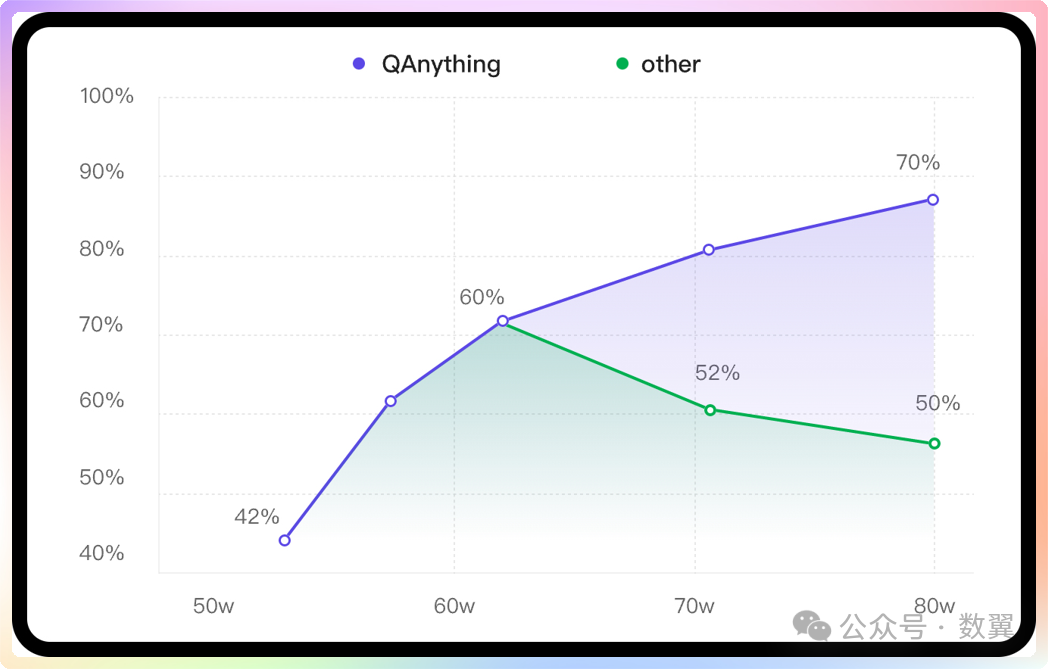
知识库数据量大的场景下两阶段优势非常明显,如果只用一阶段embedding检索, 随着数据量增大会出现检索退化的问题,如下图中绿线所示, 二阶段rerank重排后能实现准确率稳定增长,即数据越多,效果越好。
开源和生产使用
QAnything的开源版本基于QwenLM,已在大量专业问答数据集上进行了优化。它极大地增强了问答能力。如果需要用于商业目的, 请遵循QwenLM的许可协议。用户在Linux系统上使用QAnything时, 需要满足一定的先决条件,如NVIDIA GPU内存>= 4GB等。
友好的用户界面
QAnything的用户界面设计友好且易于操作,无需繁琐的配置。用户可以轻松选择多个知识库进行问答,满足不同需求。
我下面使用 SaaS 版本做展示,大家有兴趣的可以本地部署。
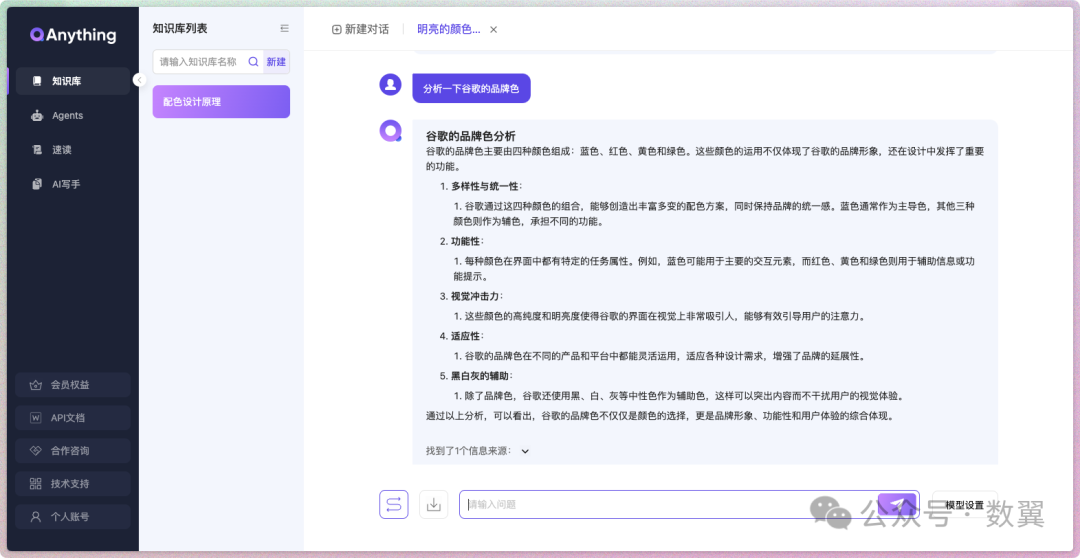
知识库问答
登录之后界面非常简洁,不需要文档都可以直接使用:
填入知识库名称,点击「新建」,拖入本地知识库的文档(可以是PDF、Docx等),然后点击确定即可。
我这里上传了一个色彩设计的文档,然后快速进行提问,回答速度和效果都不错,末尾还会给出数据来源。
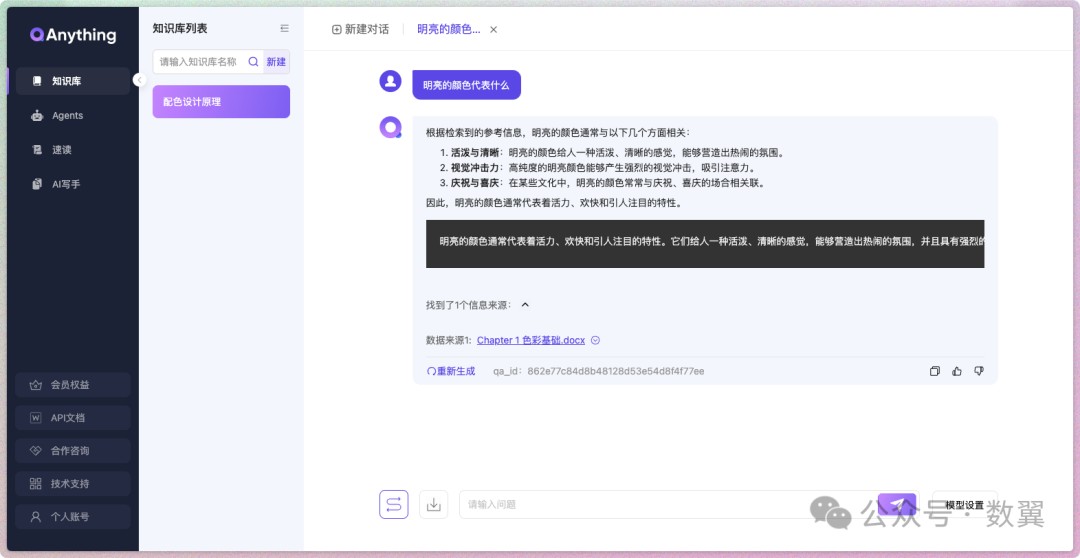
再问一个其他问题:
简单的使用和设置由于使用简单,我们可以的设置项也非常有限,只有区区几个设置项:
-
• 大模型的选择
-
• 回复上限(默认是 512 Token,最多 1024 Token)
-
• 是否使用混合检索
Agent
另外 QAnything 也提供了一个自定义 Agent 的功能,可以快速创建自己的知识库问答系统。
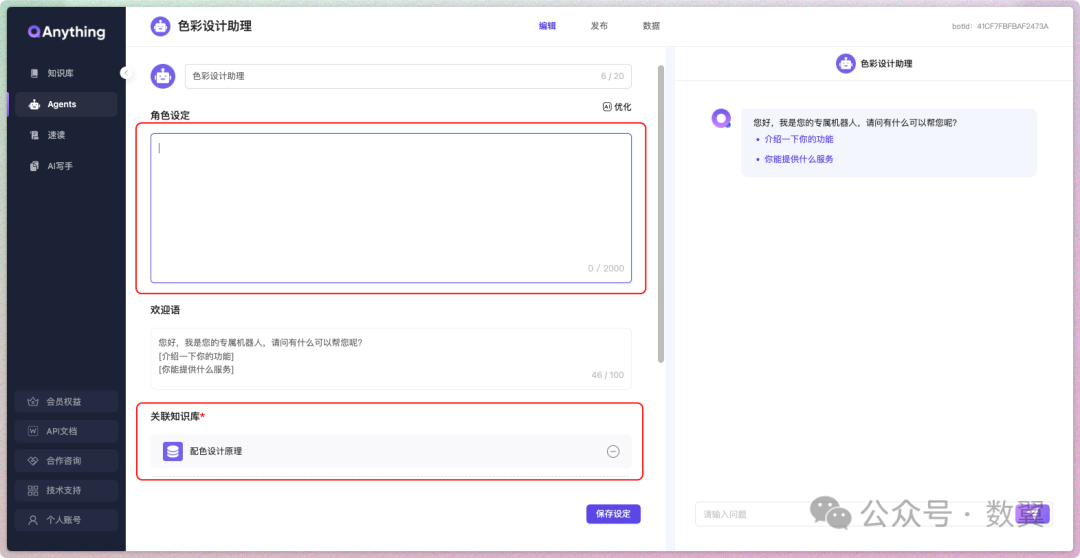
Agent 就是你给他设置一个角色,也就是我们常常提到的 System Prompt。系统提示语 我们一般设置如下内容:
-
• 角色定义,比如:你是一个聪明的研究助理。
-
• 任务的描述。比如:请回答用户关于产品的常见问题。
-
• 上下文信息。比如:用户正在查找有关2024年新产品的信息。
-
• 语言风格和语气。比如:使用专业术语,保持正式语气。
-
• 回答示例或格式。你期望机器人能够回答的内容格式,这里可以使用少样本提示,或者直接指定格式。
-
• 限制和注意事项。告诉机器人哪些能说,哪些不能说。
然后选择知识库(可以选择多个):
值得一提的是:除了常规的直接使用 Agent 对话,QAnything 还提供了发布功能,
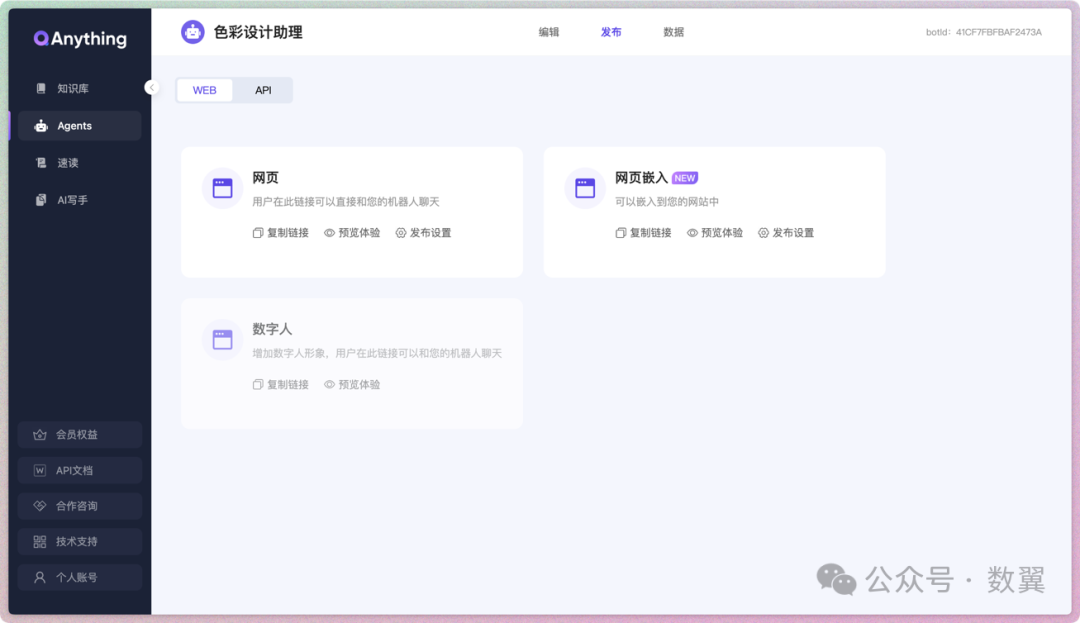
可以快速嵌入到网页中,比如我们把这个色彩设计的机器人放到知识图谱中:
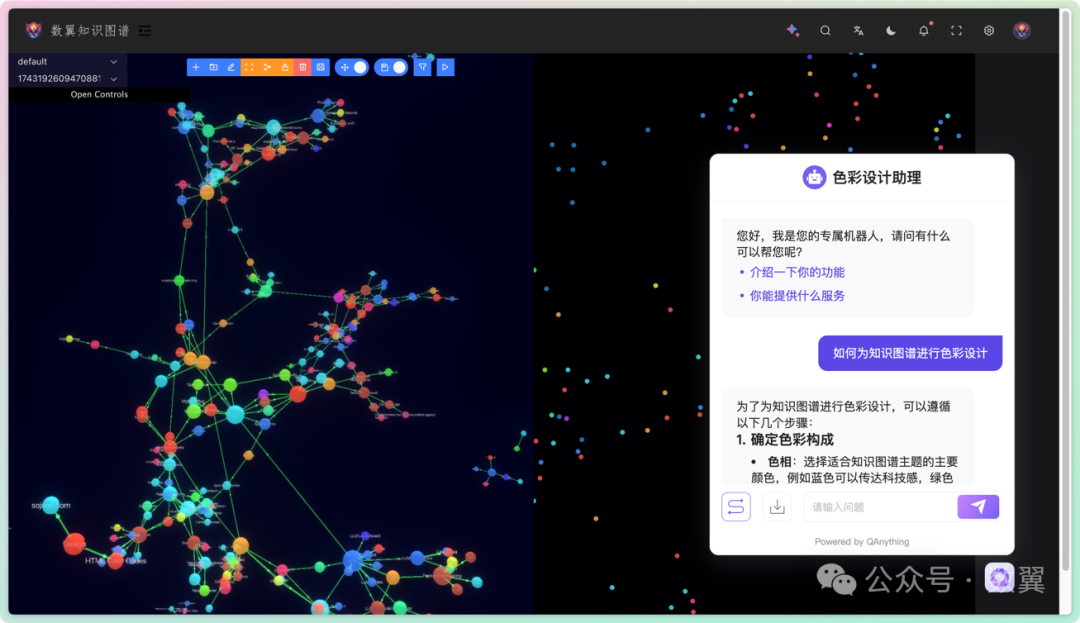
我只是做一个示例,一般来说我们嵌入到文档相关的网页中更为合适, 或者为每个知识图谱定制一个专属知识库和 Agent,这样的话才让知识文档更有实际意义。
关于知识库图谱和知识库大部分时候,我们构建知识图谱更偏向于从知识库中提取信息,这样的场景适合你有了知识库的场景,这种方式更适合问答系统。同时也可以把图谱的能力嵌入到原有的很多系统中。另外一种图谱的构建方式是,专有的更偏向结构化的数据,比如我上面截图展示的知识图谱,他没有很多的文本数据, 所以也不太适合这种基于RAG的数据问答。更适合基于图的数据问答
速读
速读功能我觉得比较鸡肋,就是上传文件帮你总结,实验下来比起 Kimi 等大模型来说效果差了不少。
先上传文件,系统会进行解析,解析的速读说实话有点儿慢(和其他大模型文档解读相比)。
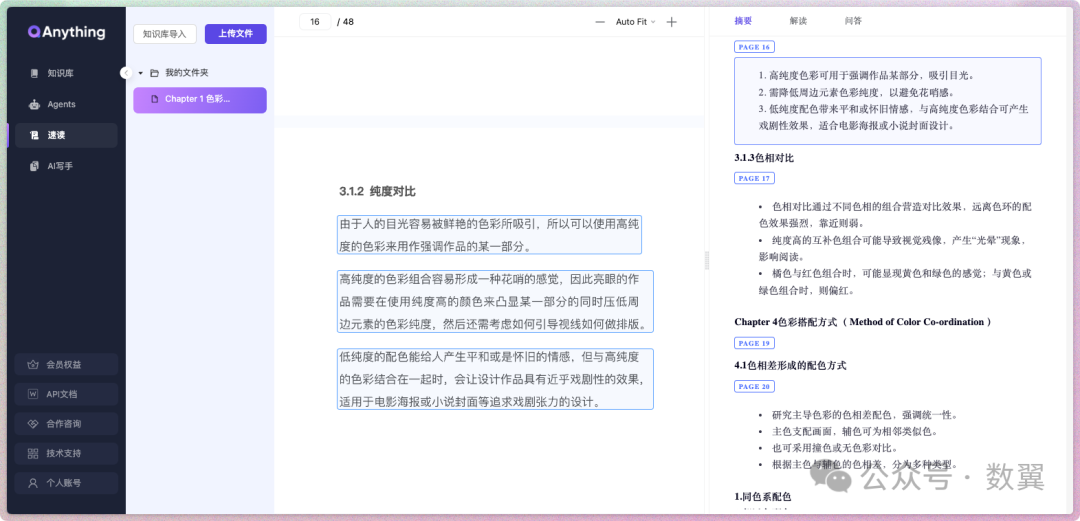
解析完成,就会左边原文,右边速读 的形式来呈现。鼠标放在原文或速读上可以查看对应的信息。
AI 写手
QAnything 也提供了一个 AI 写手的功能,可以让用户通过 QAnything 来写文章。
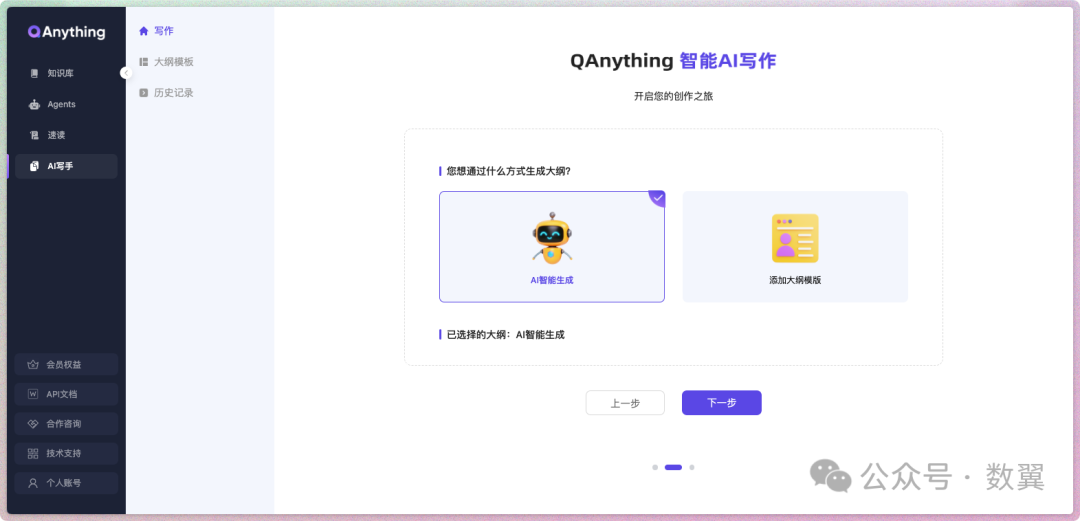
使用起来也很简单,主要提供了下面能力:
-
• 写文章时可以绑定知识库
-
• 可以手写大纲,也可以指定大纲
如果是自动生成大纲,可以对生成的大纲进行调整:
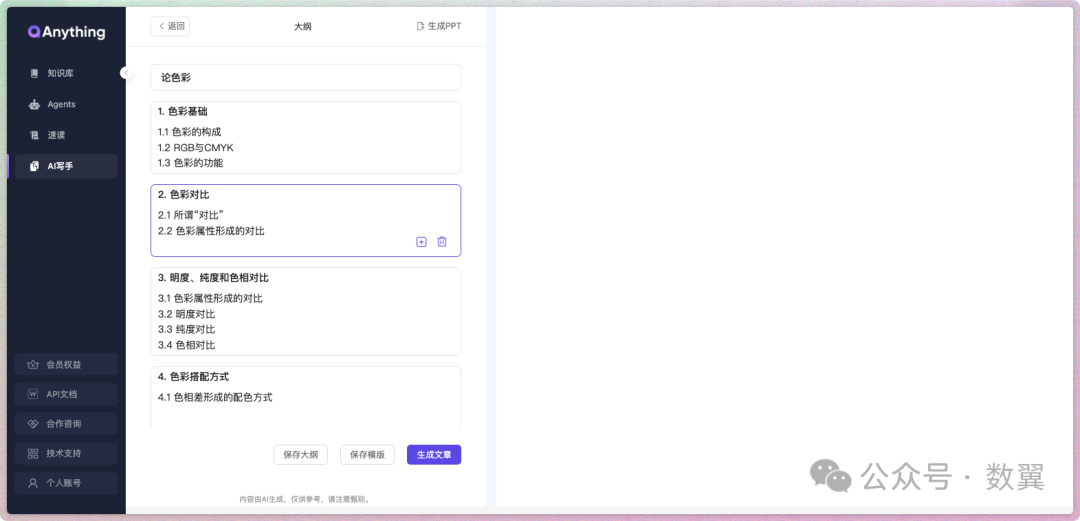
然后就可以点击生成文章了:
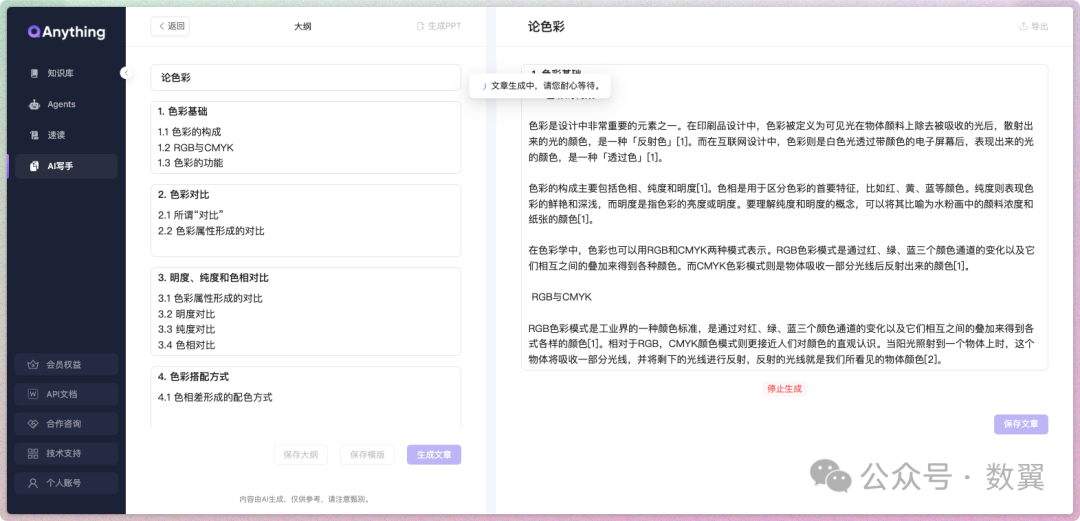
使用下来,如果是知识库内容很多,下过会好一点。如果知识库内容不多,会生成超级多的重复内容。
安装和部署
安装QAnything系统需要一些基本的Linux系统命令。首先,需要安装NVIDIA驱动,可以通过以下命令来检查驱动版本:
nvidia-smi | grep Version
接着,安装Docker,通过以下命令来检查Docker版本:
docker --version
安装Docker Composer,检查 Docker Composer版本:
docker-compose --version
最后,安装必要的Linux系统命令,可以通过以下命令完成:
sudo apt-get update
sudo apt-get install git-lfs unzip jq bc
在完成以上步骤后,用户可以拉取QAnything代码库并运行服务器。具体操作如下:
git clone it@gitlab.corp.youdao.com:ai/qanything.git
cd QAnything
bash run.sh # 用默认参数启动服务
用户可以通过以上步骤进行一键安装和部署QAnything系统,并进行服务参数设置。
系统要求
QAnything系统的运行需要符合一定的系统要求。对于Linux系统,需要满足以下最低配置:
-
• 操作系统:Linux amd64
-
• NVIDIA显卡内存:至少4GB(使用OpenAI API)
-
• NVIDIA驱动版本:不低于525.105.17
-
• Docker版本:不低于20.10.5
-
• Docker Compose版本:不低于2.23.3
用户可以通过以下步骤来安装必要的组件:
- 1. 安装NVIDIA驱动:
- • 运行命令
nvidia-smi | grep Version来检查驱动版本
- 1. 安装Docker:
- • 运行命令
docker --version来检查Docker版本
- 1. 安装Docker Compose:
- • 运行命令
docker-compose --version来检查Docker Compose版本
SaaS 服务
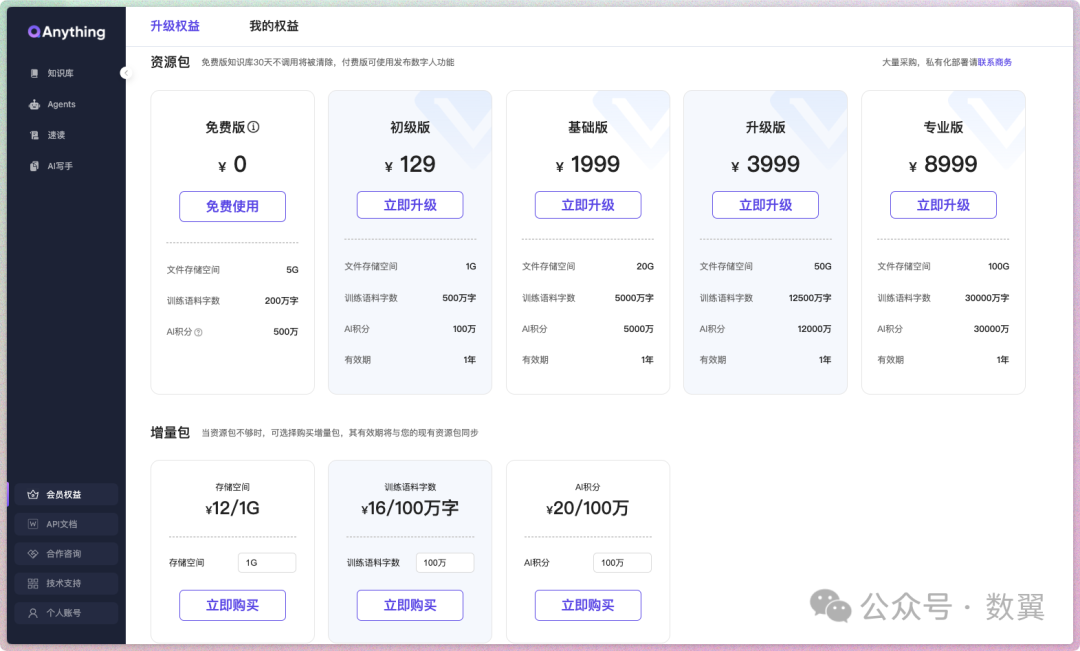
最后看一下 SaaS 服务,如果自用和拿来测试的话,可以直接用一下免费的云服务:
-
• 支持两百万的训练语料库
-
• 500万的赠送积分
-
• 知识库 30 天不用的话会被自动清除
最后
再回顾一下 QAnything 的优势,界面简洁、用户友好,提供了专门的微调模型,但是支持的模型和配置扩展能力比较少, 属于开箱即用,不需要也不太容易折腾的工具。
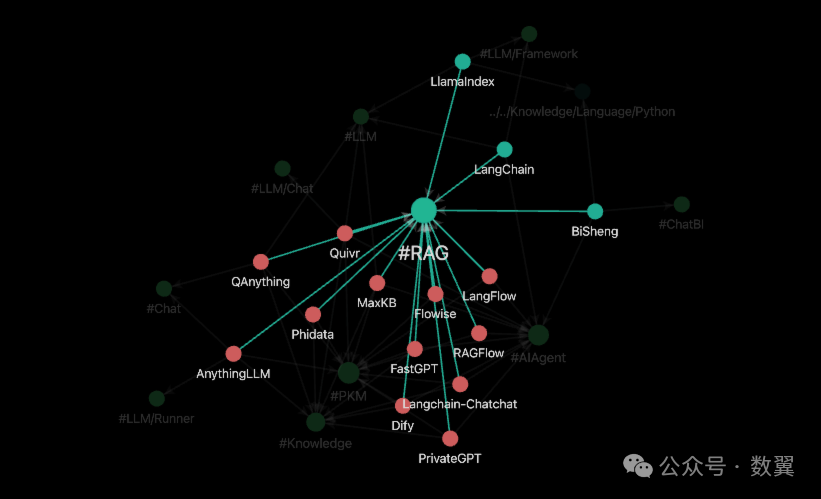
除了这个工具,我本地知识库里面也记录了一些相关工具,部分工具在之前也介绍过,大家可以参考对比下。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 967
967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









