






本篇介绍Langchain相关面试题。
- 什么是 LangChain?
- LangChain 包含哪些部分?
- LangChain 中 Chat Message History 是什么?
- 介绍一下LangChain Agent?
- LangChain 如何Embedding & vector store?
- LangChain 存在哪些问题及方法方案

一、什么是 LangChain?
LangChain 是一个基于语言模型的框架,用于构建聊天机器人、生成式问答(GQA)、摘要等功能。它的核心思想是将不同的组件“链”在一起,以创建更高级的语言模型应用。LangChain 的起源可以追溯到 2022 年 10 月,由创造者 Harrison Chase 在那时提交了第一个版本。
二、LangChain 包含哪些部分?
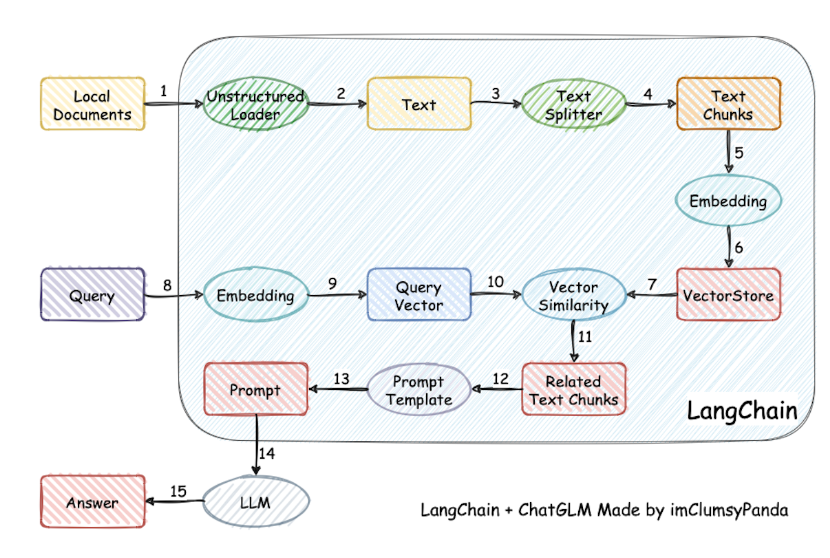
为了能够帮助大家理解,附上LangChain的流程图,如上所示。从上图可知,主要包括以下部分:
-
**模型(Models):**这指的是各种不同的语言模型以及它们的集成版本,例如GPT-4等大型语言模型。LangChain对这些来自不同公司的高级模型进行了概括,并封装了通用的API接口。利用这些API,用户能够方便地调用和控制各个公司的大模型。
-
提示(Prompts): 涉及到提示的管理、优化和序列化过程。在大语言模型的应用中,提示词发挥着至关重要的作用,无论是构建聊天机器人还是进行AI绘画,有效的提示词都是不可或缺的元素。
-
记忆(Memory): 它负责存储与模型交互时的上下文状态信息。由于模型本身不具备保存上下文的能力,因此在与模型交流时,传递相关的对话内容上下文变得十分必要。
-
索引(Indexes): 用于将文档结构化,以便更加高效地与模型进行互动。
-
链(Chains): 代表了对各种组件进行的一系列调用操作。
-
代理(Agents): 确定模型应当执行哪些操作,它们会管理执行流程并监控整个过程直至任务完成。
三、LangChain 中 Chat Message History 是什么?
Chat Message History 是 Langchain 框架中的一个组件,用于存储和管理聊天消息的历史记录。它可以跟踪和保存用户与AI之间的对话,以便在需要时进行检索和分析。Langchain 提供了不同的Chat Message History 实现方式,包括以下:
-
StreamlitChatMessageHistory: 用于在 Streamlit 应用程序中存储和使用聊天消息历史记录。它使用 Streamlit 会话状态来存储消息,并可以与 ConversationBufferMemory 以及链或代理一起使用。
-
CassandraChatMessageHistory: 使用 Apache Cassandra 数据库来存储聊天消息历史记录。Cassandra 是一种高度可扩展和高可用的 NoSQL 数据库,适用于存储大量数据。
-
MongoDBChatMessageHistory: 使用 MongoDB 数据库来存储聊天消息历史记录。MongoDB 是一种面向文档的 NoSQL 数据库,使用类似 JSON 的文档进行存储。
四、介绍一下LangChain Agent?
-
LangChain Agent 是 LangChain 框架中的一个关键组件,专门用于构建和管理对话代理。这些代理负责根据当前的对话情况来确定接下来的操作步骤。LangChain 提供了一系列创建代理的方式,例如 OpenAI Function Calling、Plan-and-execute Agent、Baby AGI 和 Auto GPT 等。每种方式都拥有不同级别的自定义能力和功能,以便于开发者根据需求构建相应的代理。
-
代理能够借助工具包来执行特定的任务或动作。工具包实际上是一组供代理使用的工具集合,旨在执行特定的功能,比如语言处理、数据处理以及外部 API 的集成。这些工具既可以是定制开发的,也可以是预先定义好的,覆盖了多种功能。以下为代码中集成的工具包:
五、LangChain 如何Embedding & vector store?
LangChain 框架提供了一种名为 “Embedding & vector store” 的方法,用于将文本数据转换为向量表示形式,并将其存储在向量数据库中。这种方法可以有效地处理自然语言处理任务,如文本分类、情感分析、命名实体识别等。以下是 LangChain 中 Embedding & vector store 的基本步骤:
-
文本预处理: 首先,对输入的文本进行预处理,包括去除停用词、标点符号、数字等,并进行分词或标记化操作。
-
嵌入模型选择: 选择合适的嵌入模型,例如 Word2Vec、GloVe、BERT 等。这些模型可以将单词或短语转换为固定长度的向量表示。
-
嵌入计算: 使用选定的嵌入模型,将预处理后的文本转换为向量表示。每个单词或短语都会被映射到一个向量空间中的点。
-
向量存储: 将生成的向量表示存储在一个向量数据库中,例如 Elasticsearch、Milvus 等。这样可以方便地查询和检索相似性较高的文本片段。
-
相似性搜索: 当需要根据给定的查询文本找到相似的文本时,可以使用向量数据库提供的相似性搜索功能。通过计算查询文本与数据库中已有向量的相似度,可以找到最相关的文本。
六、LangChain 存在哪些问题及方法方案
-
LangChain 缺乏标准的可互操作数据类型问题。 LangChain为开发人员提供了一个标准化接口,以便利用大型语言模型(LLM)来执行自然语言处理任务。尽管LangChain能够处理较复杂的数据结构,它当前并不支持标准可互操作的数据类型。因此,在使用LangChain处理数据时,可能需要执行一些额外的处理和转换步骤。
-
LangChain 太多概念容易混淆,过多的“辅助”函数问题。 LangChain包含了许多不同的模块和组件,每个模块都有其特定的功能。例如,有一些模块专门用于文本预处理、词嵌入、序列标注等任务。这些模块之间可能存在重叠的功能。LangChain提供了许多辅助函数,这些函数可以帮助用户更方便地实现各种功能。然而,过多的辅助函数可能会导致混淆,因为有些函数可能具有相似的名称或功能,但在不同的上下文中使用方式不同。此外,一些辅助函数可能需要额外的参数或配置,这可能会增加学习曲线。
-
复杂性。 从实际使用体验来看,LangChain框架并不完美。例如,LangChain中的提示词模板基本上只是对字符串的封装,但该框架提供了多种类型的提示词模板,它们之间的差异并不明显,这带来了一定的冗余。此外,这些模板缺乏安全性控制,并且存在较多的冗余。有些提示词默认是预先设定的,若要进行修改,用户需要查阅源代码以确定修改位置,这增加了使用的复杂性。
有需要全套的AI大模型面试题及答案解析资料的小伙伴,可以微信扫描下方CSDN官方认证二维码,免费领取【
保证100%免费】


















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









