






一句话总结:Conan-Embedding模型,旨在通过利用更多和更高质量的负样本来提升嵌入模型的能力。
论文原文: https://arxiv.org/pdf/2408.15710
一、研究方法

1、预训练阶段:
- 使用标准数据过滤方法(参考Internlm2)对数据进行预处理。
- 使用bge-large-zh-v1.5模型进行评分,丢弃评分低于0.4的数据。
- 使用InfoNCE损失函数和In-Batch Negative方法进行训练,公式如下:
其中,表示正样本的查询,表示正样本的段落,表示同一批次中其他样本的段落,视为负样本。
2、监督微调阶段:
-
将任务分为检索和语义文本相似性(STS)两类。
-
检索任务使用InfoNCE损失函数,公式如下:
其中,表示查询,表示正样本,表示负样本。 -
STS任务使用CoSENT损失函数,公式如下:
其中,是温度参数,是余弦相似度函数。 -
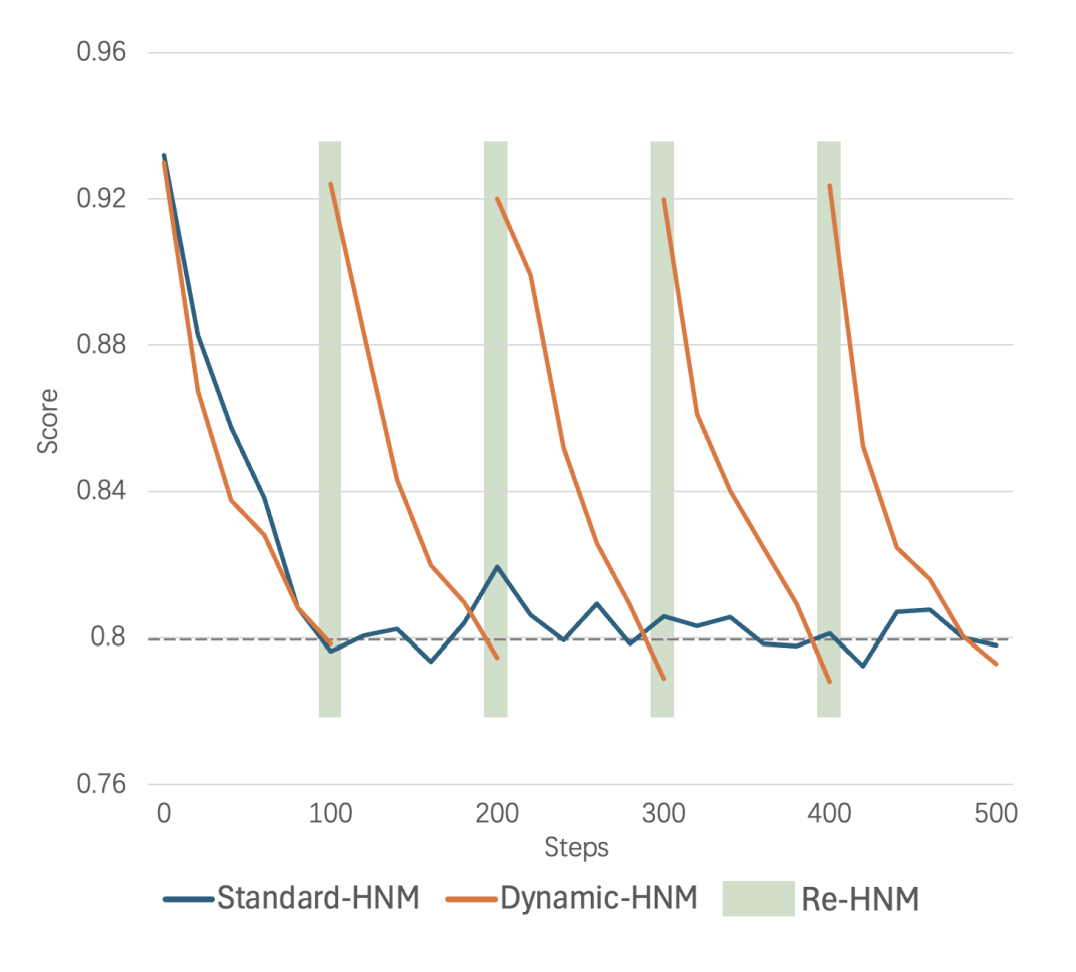
动态硬负样本挖掘:
-
记录每个数据点的当前平均负样本得分。
-
每100次迭代后,如果得分乘以1.15小于初始得分且绝对值小于0.8,则认为该负样本不再具有挑战性,并进行新一轮的硬负样本挖掘。
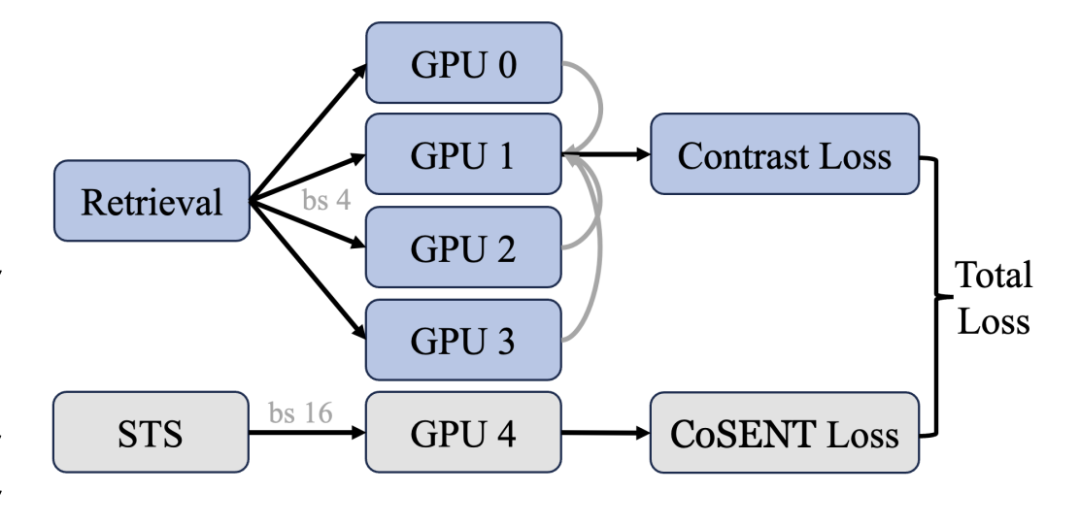
3、跨GPU平衡损失:
-
在每个前向-损失-反向-更新周期内,以平衡的方式引入每个任务,以获得稳定的搜索空间并最小化单次模型更新方向与全局最优解之间的差异。
-
对于检索任务,确保每个GPU有不同的负样本,同时共享相同的查询和正样本;对于STS任务,增加批次大小以包含更多案例进行比较。公式如下:
其中,是查询和正文本之间的评分函数,通常定义为余弦相似度,是共享查询和正文本的GPU数量,是温度参数,设置为0.8。
二、实验设计
1、数据集:
-
在预训练阶段,收集了0.75亿对文本数据,分为标题-内容对、输入-输出对和问答对等类别。
-
在微调阶段,选择了常见的检索、分类和STS任务的数据集。
2、实现细节:
-
使用BERT作为基础模型,并通过线性层将维度从1024扩展到1792。
-
使用AdamW优化器和学习率1e-5进行预训练,批量大小为8,使用64个Ascend 910B GPU进行训练,总时长为138小时。
-
微调阶段使用相同的优化器参数和学习率,批量大小为4(检索任务)和32(STS任务),使用16个Ascend 910B GPU进行训练,总时长为13小时。
三、结果与分析
1、CMTEB结果:
-
Conan-Embedding模型在CMTEB基准测试中的平均性能为72.62,超过了之前的最先进模型。
-
在检索和重排序任务中,Conan-Embedding模型表现出显著的性能提升,表明增加的负样本数量和质量使模型能够看到更具挑战性的负样本,从而增强了其召回能力。
2、消融研究:
-
动态硬负样本挖掘和跨GPU平衡损失显著优于直接使用标准InfoNCE损失和CoSENT损失进行微调的方法。
-
Conan-Embedding模型在检索和重排序任务中的表现尤为突出,进一步验证了该方法的有效性。
四、如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方CSDN官方认证二维码,免费领取【
保证100%免费】


















 990
990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









