






一句话总结:Conan-Embedding模型,旨在通过利用更多和更高质量的负样本来提升嵌入模型的能力。
论文原文: https://arxiv.org/pdf/2408.15710
研究方法

预训练阶段:
-
使用标准数据过滤方法(参考Internlm2)对数据进行预处理。
-
使用bge-large-zh-v1.5模型进行评分,丢弃评分低于0.4的数据。
-
使用InfoNCE损失函数和In-Batch Negative方法进行训练,公式如下:
其中,表示正样本的查询,表示正样本的段落,表示同一批次中其他样本的段落,视为负样本。
监督微调阶段:
-
将任务分为检索和语义文本相似性(STS)两类。
-
检索任务使用InfoNCE损失函数,公式如下:
其中,表示查询,表示正样本,表示负样本。
-
STS任务使用CoSENT损失函数,公式如下:
其中,是温度参数,是余弦相似度函数。
-
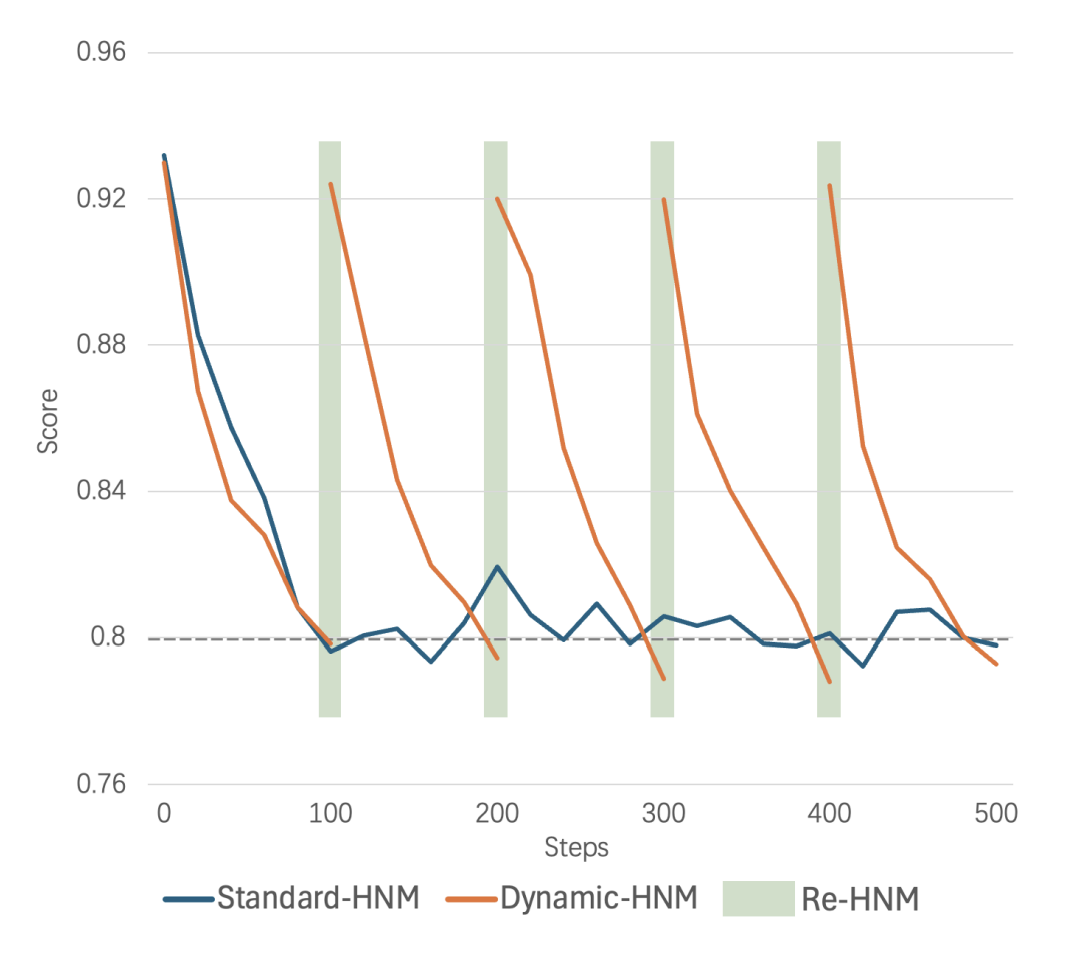
动态硬负样本挖掘:
-
记录每个数据点的当前平均负样本得分。
-
每100次迭代后,如果得分乘以1.15小于初始得分且绝对值小于0.8,则认为该负样本不再具有挑战性,并进行新一轮的硬负样本挖掘。
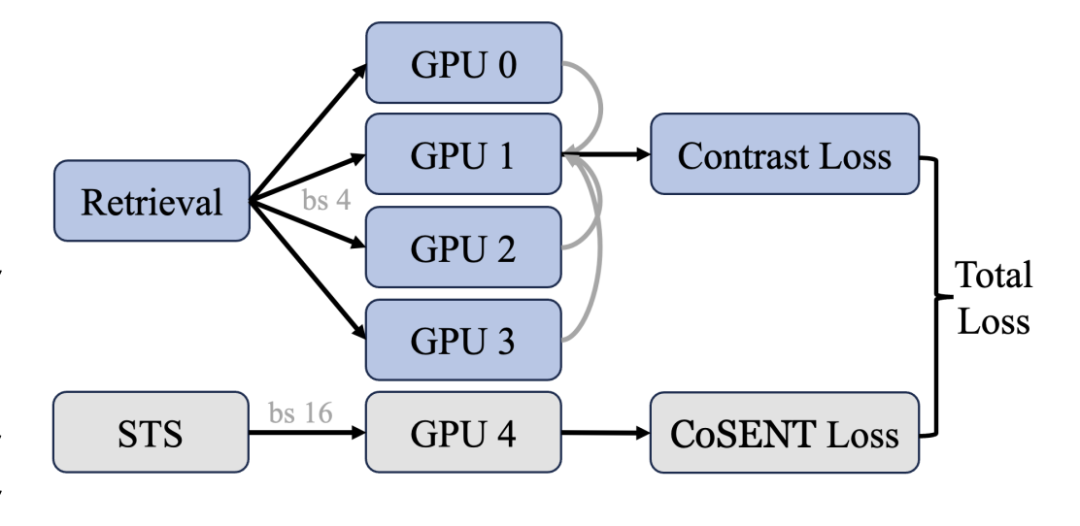
跨GPU平衡损失:
-
在每个前向-损失-反向-更新周期内,以平衡的方式引入每个任务,以获得稳定的搜索空间并最小化单次模型更新方向与全局最优解之间的差异。
-
对于检索任务,确保每个GPU有不同的负样本,同时共享相同的查询和正样本;对于STS任务,增加批次大小以包含更多案例进行比较。公式如下:
其中,是查询和正文本之间的评分函数,通常定义为余弦相似度,是共享查询和正文本的GPU数量,是温度参数,设置为0.8。
实验设计
数据集:
-
在预训练阶段,收集了0.75亿对文本数据,分为标题-内容对、输入-输出对和问答对等类别。
-
在微调阶段,选择了常见的检索、分类和STS任务的数据集。
实现细节:
-
使用BERT作为基础模型,并通过线性层将维度从1024扩展到1792。
-
使用AdamW优化器和学习率1e-5进行预训练,批量大小为8,使用64个Ascend 910B GPU进行训练,总时长为138小时。
-
微调阶段使用相同的优化器参数和学习率,批量大小为4(检索任务)和32(STS任务),使用16个Ascend 910B GPU进行训练,总时长为13小时。
结果与分析
-
CMTEB结果:
-
Conan-Embedding模型在CMTEB基准测试中的平均性能为72.62,超过了之前的最先进模型。
-
在检索和重排序任务中,Conan-Embedding模型表现出显著的性能提升,表明增加的负样本数量和质量使模型能够看到更具挑战性的负样本,从而增强了其召回能力。
-
消融研究:
-
动态硬负样本挖掘和跨GPU平衡损失显著优于直接使用标准InfoNCE损失和CoSENT损失进行微调的方法。
-
Conan-Embedding模型在检索和重排序任务中的表现尤为突出,进一步验证了该方法的有效性。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}