







 本博客介绍了如何在Jetson Nano上配置YOLOv5,通过CUDA和TensorRTx实现25FPS的实时目标检测。首先,详细讲解了配置CUDA的过程,接着修改Nano板的显存,安装Pytorch 1.8.0。之后,搭建YOLOv5环境,解决matplotlib安装问题和非法指令错误。最后,利用tensorrtx加速推理,调用USB摄像头进行目标检测,遇到的问题及解决办法也一并给出。
本博客介绍了如何在Jetson Nano上配置YOLOv5,通过CUDA和TensorRTx实现25FPS的实时目标检测。首先,详细讲解了配置CUDA的过程,接着修改Nano板的显存,安装Pytorch 1.8.0。之后,搭建YOLOv5环境,解决matplotlib安装问题和非法指令错误。最后,利用tensorrtx加速推理,调用USB摄像头进行目标检测,遇到的问题及解决办法也一并给出。
镜像下载、域名解析、时间同步请点击 阿里云开源镜像站
一、版本说明
JetPack 4.6——2021.8 yolov5-v6.0版本 使用的为yolov5的yolov5n.pt,并利用tensorrtx进行加速推理,在调用摄像头实时检测可以达到FPS=25。
二、配置CUDA
sudo gedit ~/.bashrc在打开的文档的末尾添加如下:
export CUDA_HOME=/usr/local/cuda-10.2
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda-10.2/bin:$PATH保持并退出,终端执行
source ~/.bashrc
nvcc -V #如果配置成功可以看到CUDA的版本号三、修改Nano板显存
1.打开终端输入:
sudo gedit /etc/systemd/nvzramconfig.sh2.修改nvzramconfig.sh文件
修改mem = $((("${totalmem}"/2/"${NRDEVICES}")*1024))
为mem = $((("${totalmem}"*2/"${NRDEVICES}")*1024))3.重启Jetson Nano
4.终端中输入:
free -h可查看到swap已经变为7.7G
四、配置Pytorch1.8
1.下载torch-1.8.0-cp36-cp36m-linux_aarch64.whl
下载地址:nvidia.box.com/shared/static/p57jwntv436lfrd78inwl7iml6p13fzh.whl
说明:建议在电脑上下载后拷贝到Jetson Nano的文件夹下,因为该网站的服务器 在国外,可能下载比较慢或网页加载不出来,可以打开VPN进行下载。
2.安装所需的依赖包及pytorch
打开终端输入:
sudo apt-get update
sudo apt-get upgrade
sudo apt-get dist-upgrade
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev因为下面用pip指令安装时用默认选用的国外源,所以下载比较费时间,建议更换一下国内源,这里提供阿里源,当使用某种国内源pip无法下载某一包时可以尝试切换再下载。具体步骤如下:
打开终端输入:
mkdir ~/.pip
sudo gedit ~/.pip/pip.conf在空白文件中输入如下内容保存并退出:
以下为阿里源
[global]
index-url=http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com终端输入:
pip3 install --upgrade pip #如果pip已是最新,可不执行
pip3 install Cython
pip3 install numpy
pip3 install torch-1.8.0-cp36-cp36m-linux_aarch64.whl #注意要在存放该文件下的位置打开终端并运行
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev
git clone --branch v0.9.0 https://github.com/pytorch/vision torchvision #下载torchvision,会下载一个文件夹
cd torchvision #或者进入到这个文件夹,右键打开终端
export BUILD_VERSION=0.9.0
python3 setup.py install --user #时间较久
#验证torch和torchvision这两个模块是否安装成功
python3
import torch
print(torch.__version__) #注意version前后都是有两个横杠
#如果安装成功会打印出版本号
import torchvision
print(torchvision.__version__)
#如果安装成功会打印出版本号五、搭建yolov5环境
终端中输入:
git clone https://github.com/ultralytics/yolov5.git #因为不开VPN很容易下载出错,建议在电脑中下载后拷贝到jetson nano中
python3 -m pip install --upgrade pip
cd yolov5 #如果是手动下载的,文件名称为yolov5-master.zip压缩包格式,所以要对用unzip yolov5-master.zip进行解压,然后再进入到该文件夹
pip3 install -r requirements.txt #我的问题是对matplotlib包装不上,解决办法,在下方。如果其他包安装不上,可去重新执行换源那一步,更换另一种国内源。
python3 -m pip list #可查看python中安装的包
以下指令可以用来测试yolov5
python3 detect.py --source data/images/bus.jpg --weights yolov5n.pt --img 640 #图片测试
python3 detect.py --source video.mp4 --weights yolov5n.pt --img 640 #视频测试,需要自己准备视频
python3 detect.py --source 0 --weights yolov5n.pt --img 640 #摄像头测试问题1:解决matplotlib安装不上问题
解决:下载matplotlib的whl包(下方有网盘分享)
问题2:在运行yolov5的detect.py文件时出现 “Illegal instruction(core dumped)”
解决:
sudo gedit ~/.bashrc
末尾添加
export OPENBLAS_CORETYPE=ARMV8
保持关闭
source ~/.bashrc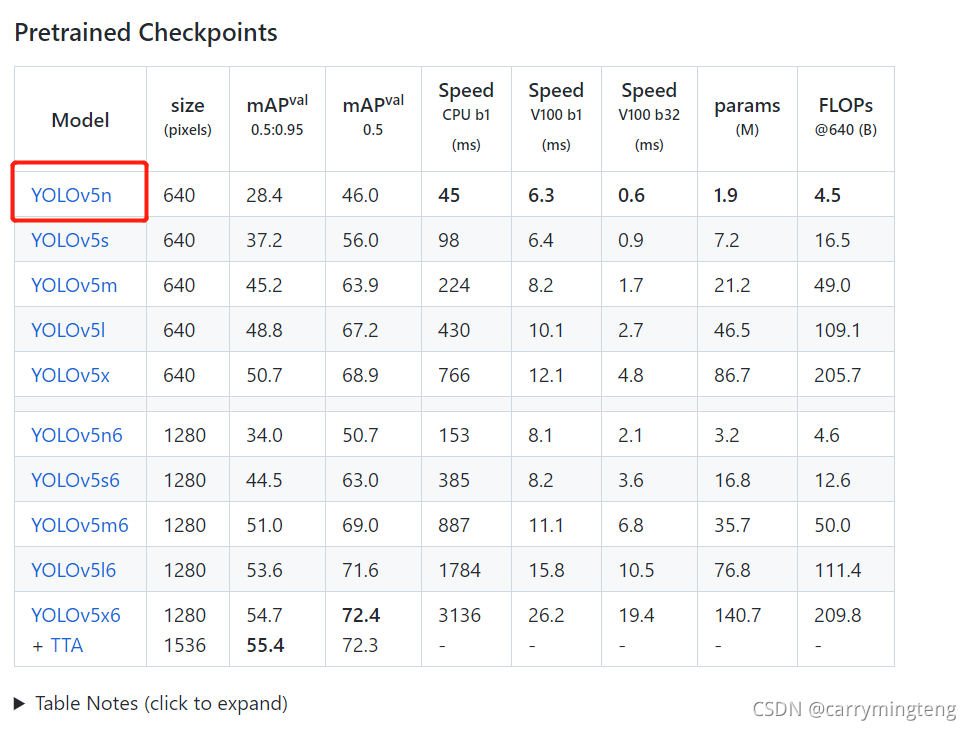
六、利用tensorrtx加速推理
1.下载tensorrtx
下载地址:https://github.com/wang-xinyu/tensorrtx.git
或者
git clone https://github.com/wang-xinyu/tensorrtx.git2.编译
将下载的tensorrtx项目中的yolov5/gen_wts.py复制到上述的yolov5(注意:不是tensorrtx下的yolov5!!!)下,然后在此处打开终端
打开终端输入:
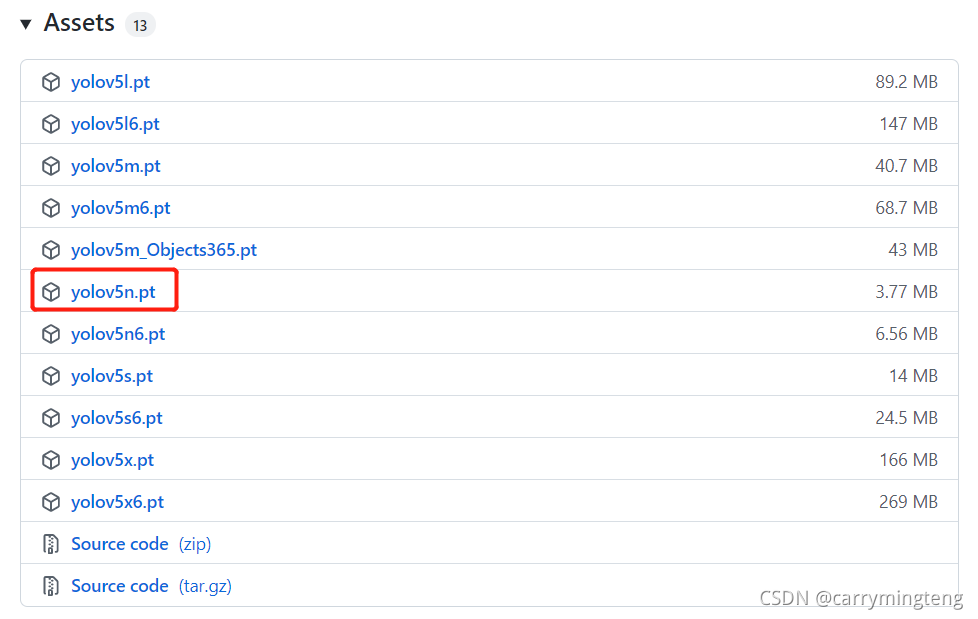
python3 gen_wts.py -w yolov5n.pt -o yolov5n.wts #生成wts文件,要先把yolov5n.pt文件放在此处再去执行
cd ~/tensorrtx/yolov5/ #如果是手动下载的名称可能是tensorrtx-master
mkdir build
cd build
将生成的wts文件复制到build下 #手动下载的,名称为yolov5-master
cmake ..
make -j4
sudo ./yolov5 -s yolov5n.wts yolov5n.engine n #生成engine文件
sudo ./yolov5 -d yolov5n.engine ../samples/ #测试图片查看效果,发现在检测zidane.jpg时漏检,这时可以返回上一层文件夹找到yolov5.cpp中的CONF_THRESH=0.25再进入到build中重新make -j4,再重新运行该指令即可 3.调用USB摄像头
参考了该文章https://blog.csdn.net/weixin_54603153/article/details/120079220
(1)在tensorrtx/yolov5下备份yolov5.cpp文件,因为如果更换模型时重新推理加速时需要用到该文件。
(2)然后对yolov5.cpp文件修改为如下内容
修改了12行和342行
#include <iostream>
#include <chrono>
#include "cuda_utils.h"
#include "logging.h"
#include "common.hpp"
#include "utils.h"
#include "calibrator.h"
#define USE_FP32 // set USE_INT8 or USE_FP16 or USE_FP32
#define DEVICE 0 // GPU id
#define NMS_THRESH 0.4 //0.4
#define CONF_THRESH 0.25 //置信度,默认值为0.5,由于效果不好修改为0.25取得了较好的效果
#define BATCH_SIZE 1
// stuff we know about the network and the input/output blobs
static const int INPUT_H = Yolo::INPUT_H;
static const int INPUT_W = Yolo::INPUT_W;
static const int CLASS_NUM = Yolo::CLASS_NUM;
static const int OUTPUT_SIZE = Yolo::MAX_OUTPUT_BBOX_COUNT * sizeof(Yolo::Detection) / sizeof(float) + 1; // we assume the yololayer outputs no more than MAX_OUTPUT_BBOX_COUNT boxes that conf >= 0.1
const char* INPUT_BLOB_NAME = "da 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









