






 本文详细解释了在YOLO目标检测过程中,如何区分正样本(TT,TN)和负样本(NT,NN),并阐述了精确率和召回率的概念,以及它们在评估模型性能时的作用。此外,还提到了map50和map0.25、0.5、0.75这些评价指标。
本文详细解释了在YOLO目标检测过程中,如何区分正样本(TT,TN)和负样本(NT,NN),并阐述了精确率和召回率的概念,以及它们在评估模型性能时的作用。此外,还提到了map50和map0.25、0.5、0.75这些评价指标。
前面没啥,重点是要你先关注,才能看后面,再看看,马上不能看了吧,坚持坚持,点个关注就可以都看到了,哈哈哈
注:对于其中一个目标来说,只有他是正样本,其他所有均为负样本
首先说明yolo检测过程中,会将结果分为四类,
T检测为正确(1、TP(P的意思是检测为正样本,T的意思是指上一句话(P的意思是检测为正样本)是正确的),2、TN(N:检测为负样本,T的意思是指上一句话(N:检测为负样本)是正确的但))
F检测为错误(3、FP(P:检测为正样本样本,F:(P:检测为正样本样本)这句话是错误的),4、FN(N:检测为负样本,F:(N:检测为负样本)这句话是错误的))
精确率,简单来说就是预测为正样本的样本中正确的所占比例(P检测为正样本)中的正确率=TP/(TP+FP)或=TP/P
换一句话来说精确率就是在反映yolo看到(检测)的结果对不对
召回率,简单来说就是检测到的正样本占所有正样本的比例(TP检测为正样本,FN表示预测为负样本但是预测是错误的,因此指的还是正样本)=TP/(TP+FN)
换一句话来说召回率就是在反映yolo能不能看到(检测)到标签
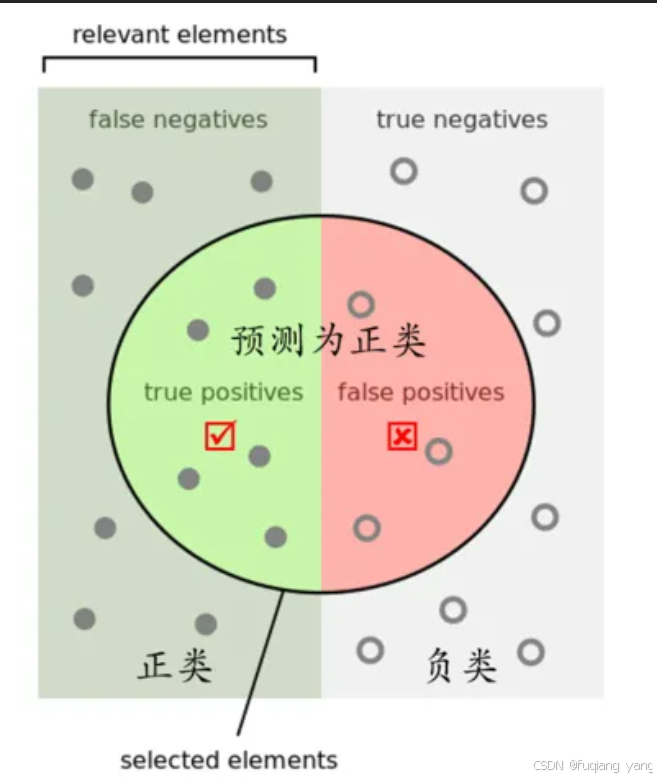
注:yolo中底层算法会每个目标如此都计算,然后通过算法计算出总结果map50和map0.25、0.5、0.75

















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









