







目录
一、如何改进神经网络?
1、改变激活函数
当使用sigmoid函数进行迭代,迭代次数增加时,可能会出现梯度消失,即比较靠近输入的几层梯度值十分小,靠近输出层的几层梯度值会很大,当你设定相同的学习率时,靠近输入层的参数收敛缓慢,而输出层的参数已经收敛完全。
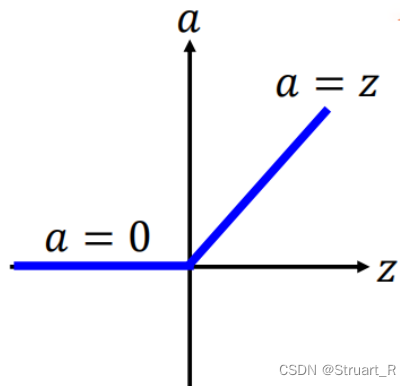
通过用ReLU函数来改善梯度消失,由于ReLU函数的梯度不会随x的变化而变化,所以不会出现梯度消失的问题。
2、变化学习率
常用的变化学习率的算法有RMSprop、SGD、Adam、Adagrad、Momentum
RMSprop是一种自适应学习率方法。Adagrad会累加之前所有的梯度平方,而RMSprop仅仅是计算对应的平均值,因此可缓解Adagrad算法学习率下降较快的问题。
Adam是另一种自适应学习率的方法。它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
Adagrad能够在训练中自动的对α进行调整,对于出现频率较低参数采用较大的α更新;相反,对于出现频率较高的参数采用较小的α更新。因此,Adagrad非常适合处理稀疏数据。
3、batchsize和趋势项
batchsize:选取一次训练的样本数,一个epoch读取一次所有的batchsize,通常来说batchsize越小训练出来的模型越好,但计算时间越长,batchsize越大计算速度更快,越容易欠拟合。
趋势项:通过在梯度下降过程中加入趋势项来避免局部最优解。
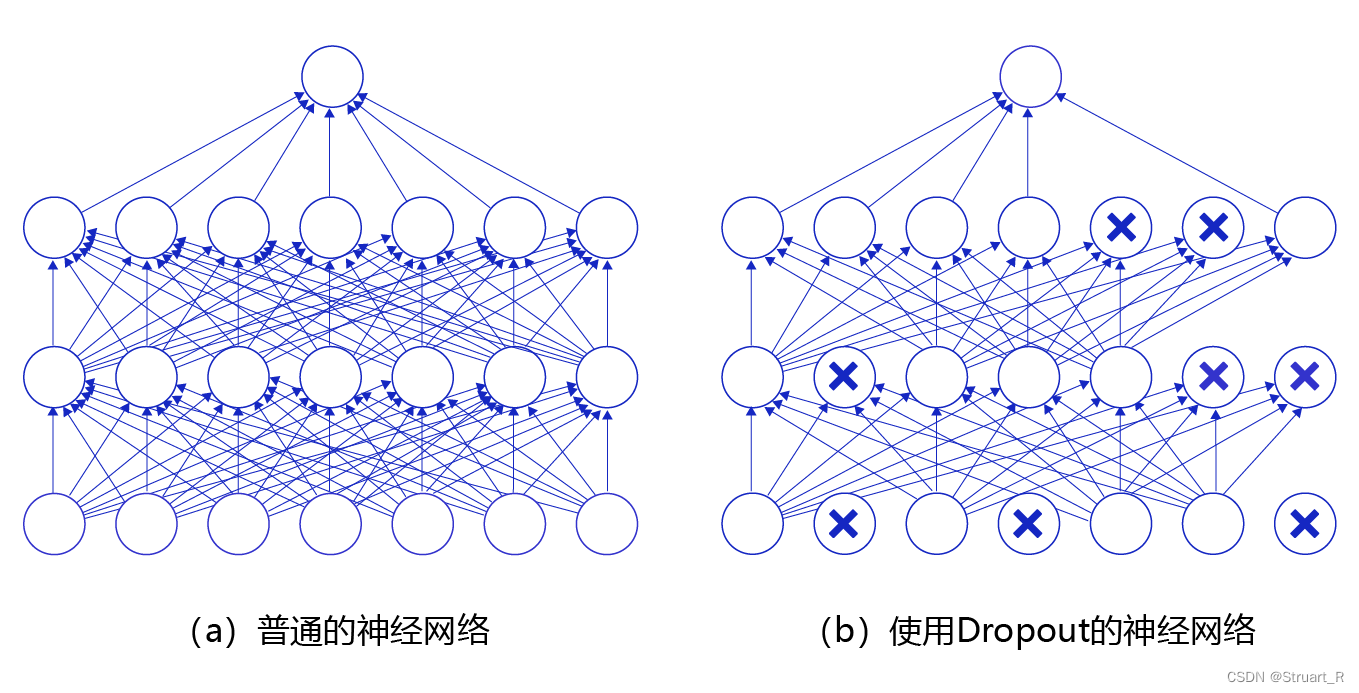
4、dropout
在神经网络前向传播时,通过让神经元以一定概率p来停止工作,提高泛化程度,降低对特征的依赖程度,从而优化模型。














 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









