







目录
四、Mode Collapse and Mode Dropping
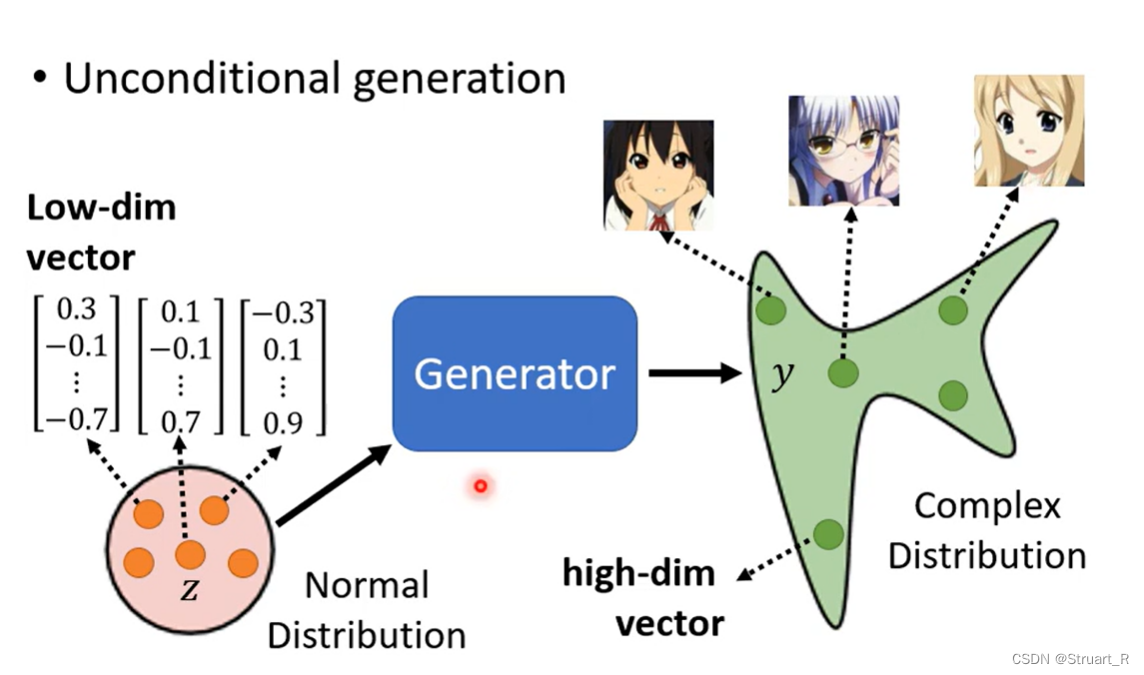
一、概述
GAN(Generative Adversial Network)生成式对抗网络,由生成器(Generator)和对抗器(Discriminator)组成,通过让生成器生成对应类别分布的网络,判别器来判别是否为真或假的概率值,不断迭代过程,使生成器能生成更为逼真的样本数据。
生成器的任务就是通过从随机噪音中生成与真实数据尽可能相似的网络,来欺骗判别器。
判别器的任务是接收生成样本和真实样本的判断生成样本和真实样本之间的区别,并通过一系列神经网络输出一个概率值,表示该样本为真的概率。
GAN已经在若干领域取得了成果,比如语音合成,图像生成等方面,但仍存在一些挑战,比如不稳定性和模式坍塌等问题。
二、算法过程
(1)首先初始化生成器和判别器参数,并通过随机噪音生成一批假样本。
(2)将假样本放入生成器,通过生成器生成图片。
(3)生成图片传给判别器,判别器输出与真实值相比为真的概率,将相关数值传输给生成器。
(4)生成器通过修改超参数,生成新的图片传给判别器。
(5)不断迭代以上过程,知道达到某一个阈值,或者迭代次数上限。
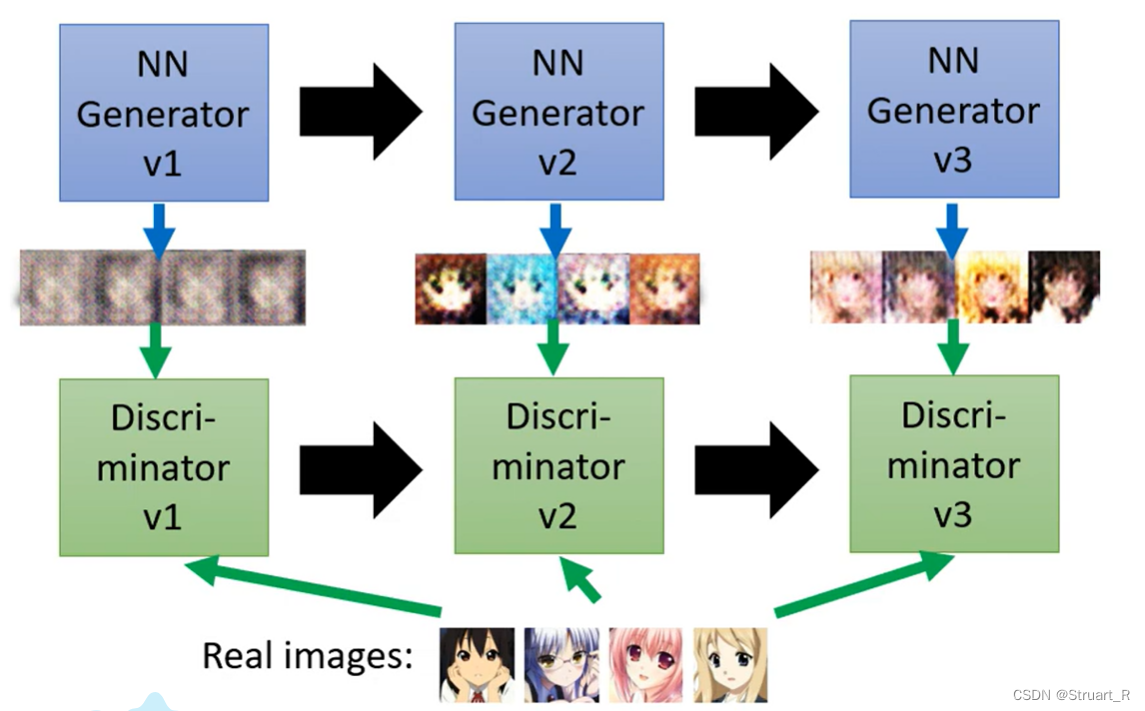
三、WGAN
1、GAN的不足
(1)模式崩溃问题,在生成器中可能生成特定类型的样本,忽略了其他不同类型的训练样本,没有达到多样性,从而出现模式崩溃的问题。
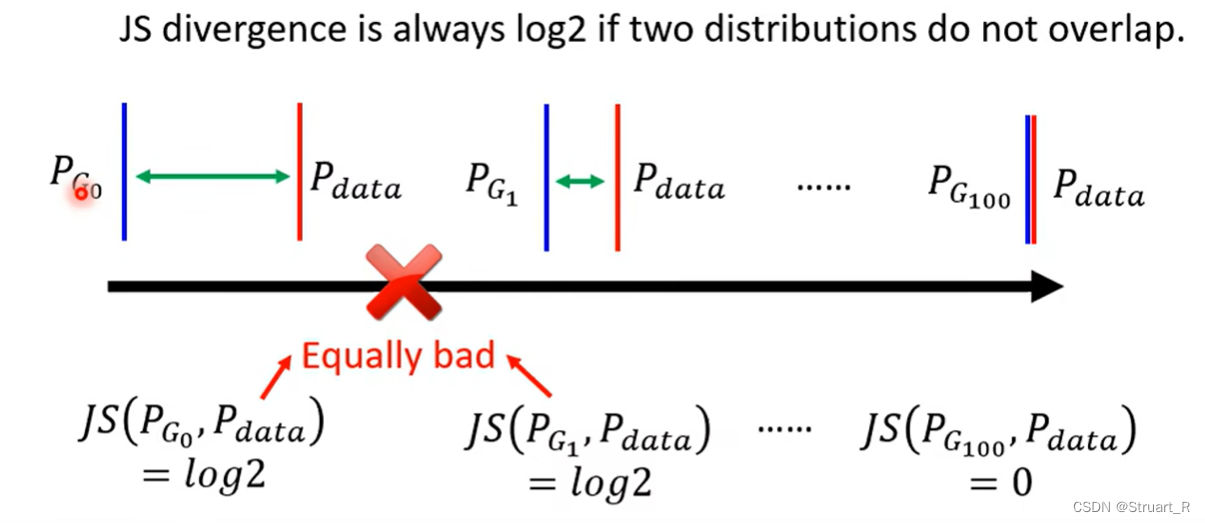
(2)没有指标可以告知收敛的程度的问题,我们只能人为的通过监控训练的图像,来知道收敛的程度,这大大降低的训练的效果,浪费了训练的时间。(例如下面这个图,在迭代到两者overlap之前,测量js散度都是一成不变的log2。)
2、JS散度、KL散度、Wasserstein距离
(1)散度:表征空间各点矢量场发散的强弱程度,表示场的有源性。
(2)KL散度:相对熵、信息增益,表征两个概率分布P和Q差别的非对称性度量,对P和Q的距离的收敛没有判别性,在没有完全重叠时,KL散度都将没有价值。
KL散度是非对称的,即KL(A,B)≠KL(B,A),由于对数函数是凸函数,KL散度为非负数。
(3)JS散度:度量两个概率的分布相似度,解决KL散度的非对称问题,JS散度是对称的。但仍然没有解决KL散度中的收敛没有判别性的问题。
其中上式, 。
(4)Wasserstein距离
Wasserstein距离也是度量两个概率分布之间的距离,改进了两个分布之间没有重叠部分或重叠部分较少,难以反映两个分布远近的问题,而此时KL散度没有意义,JS散度反映的是常量。
反映P和Q的所有联合分布,对于每一个可能的联合分布γ,可以从中取得一个(x,y),并计算这对样本距离||x-y||,在这种情况下计算距离的期望值
,并在所有可能的联合分布下对期望值取下界。
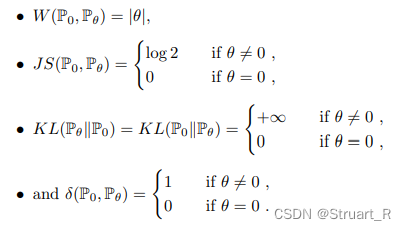
3、WGAN设计
(1)将目标函数原来的JS散度替换为Wasserstein距离
(2)去掉了判别器最后输出层的sigmoid激活函数。由于样本之间一般是不重叠的,使用sigmoid函数会更容易训练出一个判别器,而导致生成器不在移动,而使用一般的线性模型会是生成器和判别器一直以很小的方向移动,但总归是移动的。
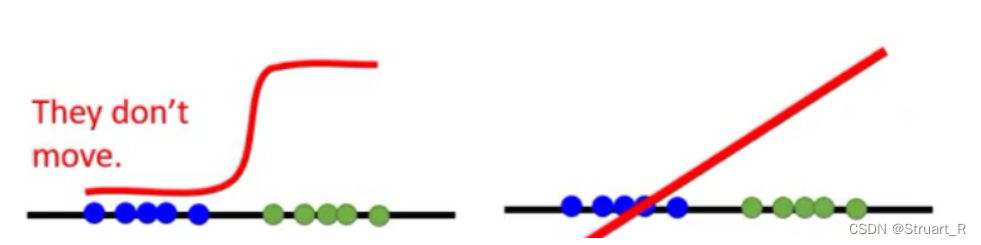
(3)将优化器Adam换成RMSProp,实验得出的经验结论罢了
(4) 权重修剪方面,通过每次更新判别器的参数,将权重限制在预先设定好的范围内,避免判别器权重过大或过小,可以使Wasserstein距离更加稳定可靠。
四、Mode Collapse and Mode Dropping
1、Mode Collapse
模式崩溃:生成图像出现多个相同图片,缺乏多样性,就是出现了模式崩溃。

2、Mode Dropping
模式丢失,生成模式在训练中无法有效生成所有真实数据分布中的模式或样本,使得生成的图片不能捕捉真实数据的分布特征,类似下面图片中在迭代之后,人脸没有变化只有肤色发生了变化。

3、FID
FID (Frechet inception distance),能够计算生成图像和真实图像的特征向量之间的度量,分数越低,生成图像和真实图像越相似。
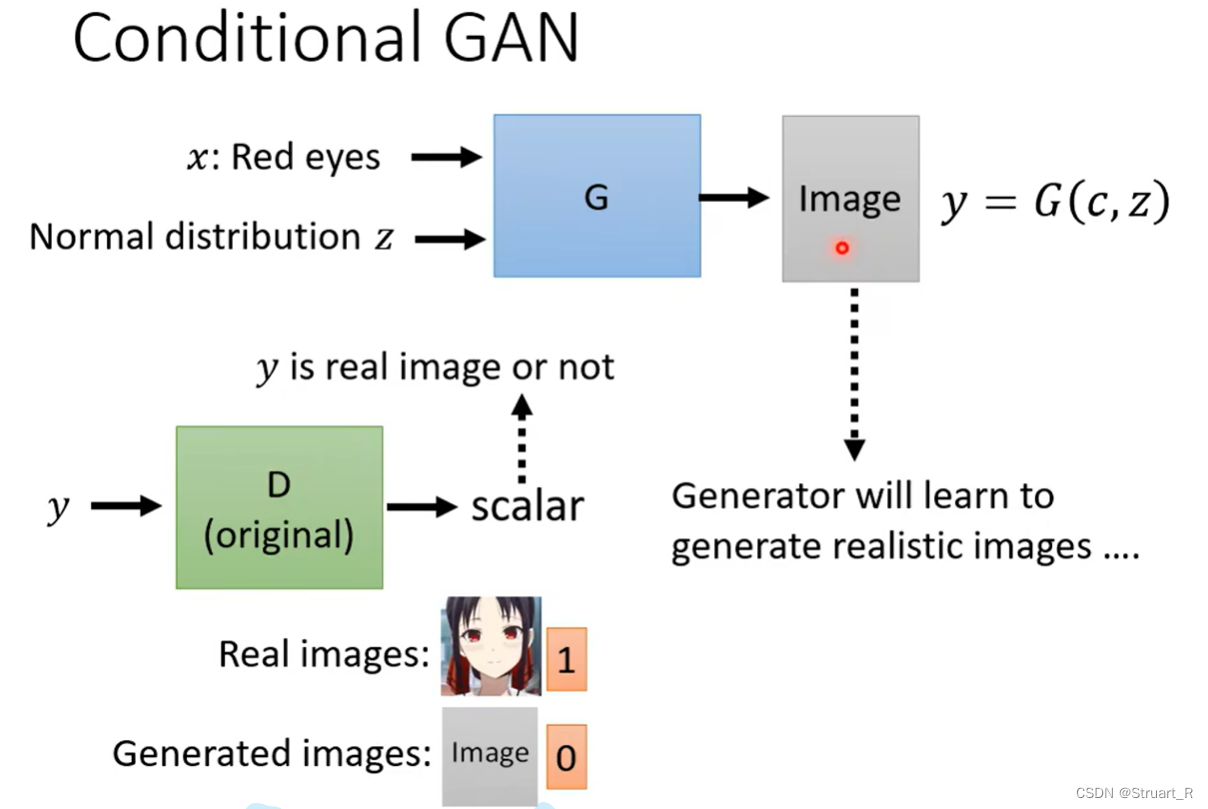
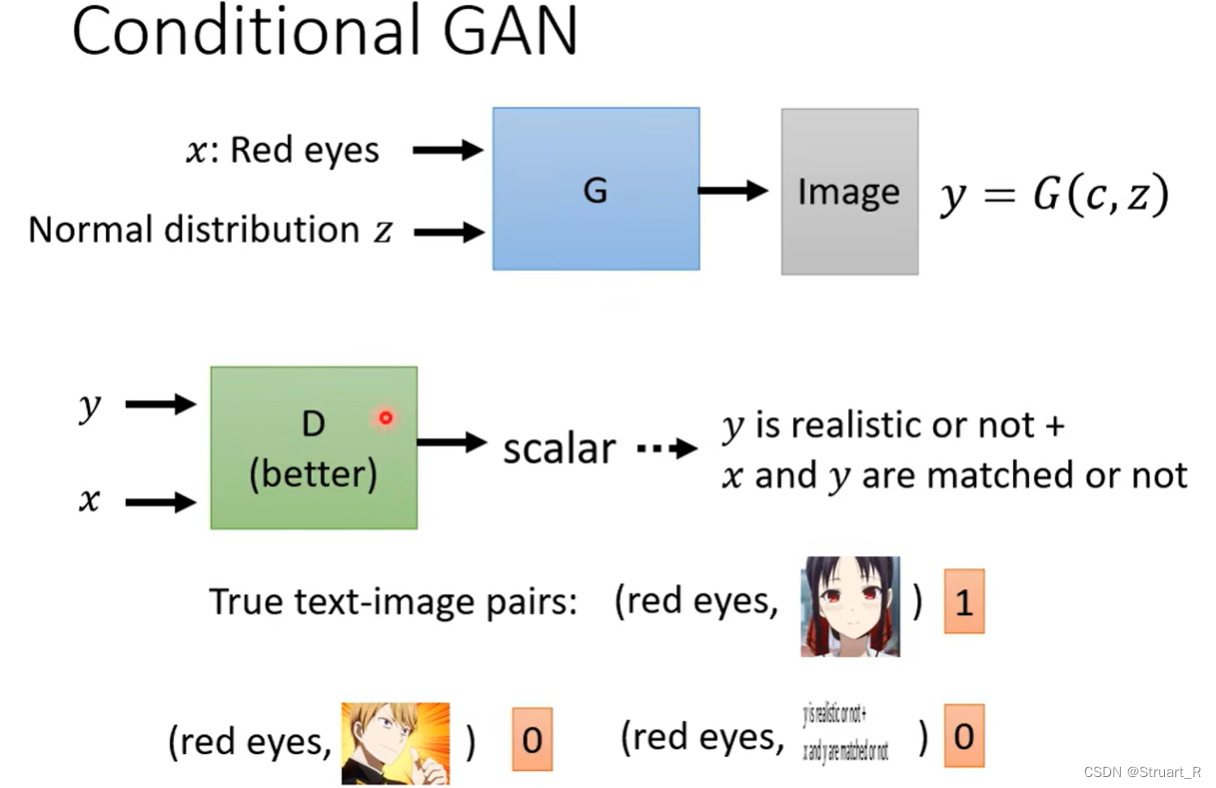
四、Conditional GAN
Conditional GAN就是条件GAN,添加一定的文字信息(或者是音讯信息)与输入的图像一同进入生成器,一般来说文字信息是要与相关信息的图片匹配,这样可以保证生成器能够利用到文字信息。
其余的过程和GAN一样,在G和D之间不断迭代。
另外在实际的应用中,在D的输入中也要加入一些噪音,可以保证不会出现D快速拟合训练集的效果。















 1713
1713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









