








 本文介绍了算力平台AutoDL及其相关的人工智能模型,如OpenGVLab和InternVL的人工智能应用,包括LLM性能排行榜,以及OpenAI、HuggingFace等公司的模型如ChatGPT、GPT-4等在文本生成、视频生成、图像识别等方面的最新进展。文章还涵盖了多模态模型、社区资源和实时应用案例,展示了AI技术在各个领域的广泛应用。
本文介绍了算力平台AutoDL及其相关的人工智能模型,如OpenGVLab和InternVL的人工智能应用,包括LLM性能排行榜,以及OpenAI、HuggingFace等公司的模型如ChatGPT、GPT-4等在文本生成、视频生成、图像识别等方面的最新进展。文章还涵盖了多模态模型、社区资源和实时应用案例,展示了AI技术在各个领域的广泛应用。
meta / llama3-70b-instruct NVIDIA测试
一、外网官网地址
1、 GitHub 官网
OpenGVLab 开放GV实验室社区
InternVL 官网
YOLO 官网
Qwen 大模型存储地址
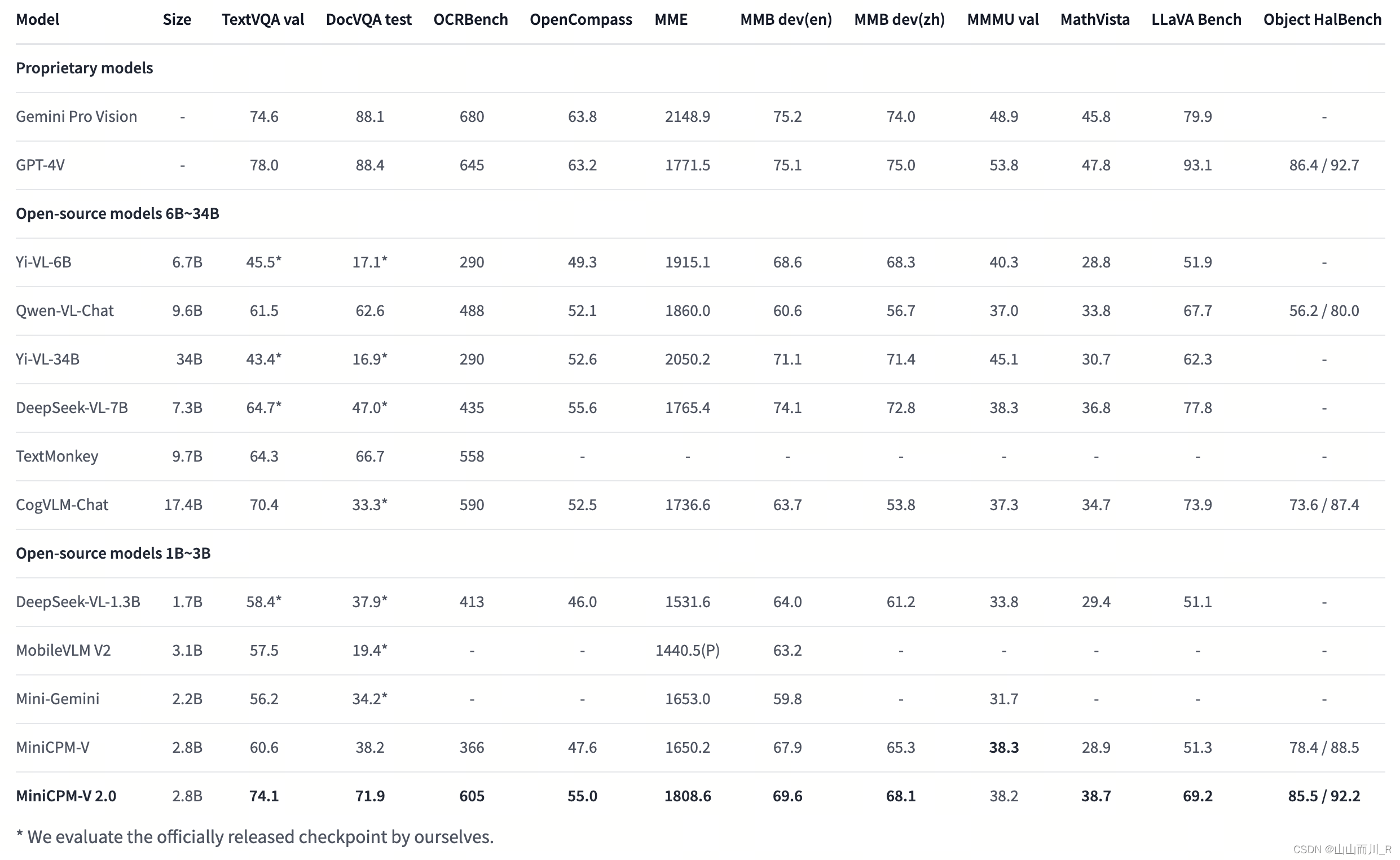
openbmb 如:MiniCPM-Llama3-V-2_5
THUDM 例如:glm-4-9b-chat
meta-llama 魔塔社区 对应的模型文件
microsoft 如:Phi-3-mini-128k-instruct
2、数据集下载
kaggle 数据集官网
极市数据集 官网
二、大模型官网
openai
sora 视频生成模型
百川 聊天页面
智谱清言 聊天页面
3、 MiniCPM-Llama3-V-2_5 图像描述 示
glm-4v-9b 图像描述
chatglm2-6b-int4 文本生成
cogvlm2-llama3-chinese-chat-19B-int4 图像描述 示
*********************************************************************************************
4、
端口
/anaconda3/envs/chatglm2/lib/python3.8/site-packages/gradio$
networking.py
对于如下命令,你将完全删除环境和环境中的所有软件包
conda remove -n env_name --all 5、
/ 文本生成 ZhipuAI/ChatGLM-6B-Int4
/ 图像描述 OpenBMB/MiniCPM-V-2
三、外网大模型存储地址
a1 Hugging Face
a3 ByteDance/Hyper-SD 图像生成 示
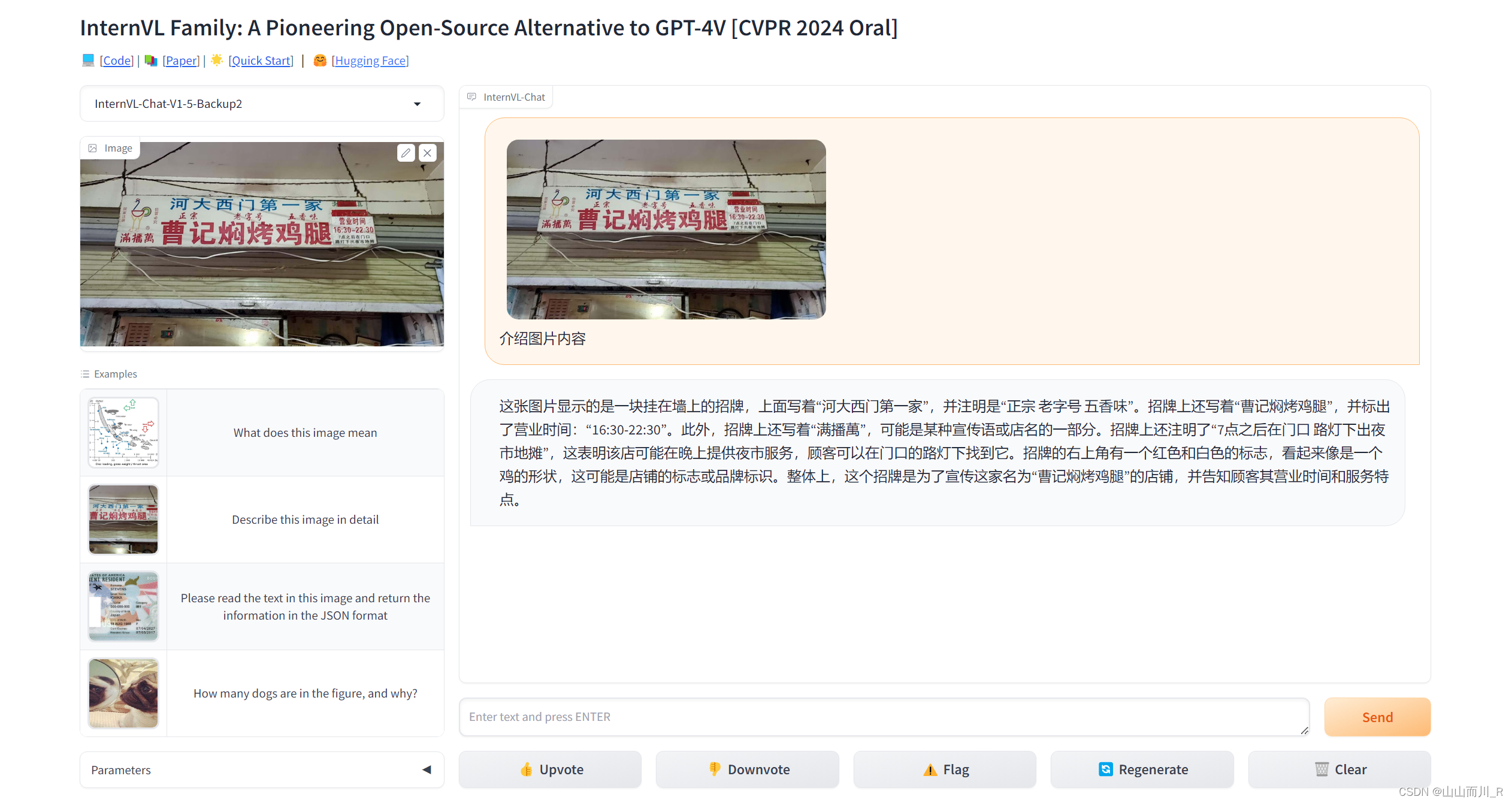
a4 OpenGVLab/InternVL-Chat-V1-5 场景识别(照片) 示
a5 coqui/XTTS-v2 文字转语音 无
a6 openbmb/MiniCPM-V-2 场景识别(照片) 可 示
a7 yisol/IDM-VTON 图像到图像(换衣) 示
a8 Farmers are growing crops 图像生成(仅支英文) 示
*****************************************************************************************************
字节跳动
ByteDance/AnimateDiff-Lightning Text-to-Video 文本转视频(动漫) 运行内存较小
腾讯
multimodalart/HunyuanDiT 文本生成 模型文件及安装地址 示
混元助手 示例 hunyuan
自己语音音色合成
示例 fish-speech
ChatGPT4 示例 ChatGPT4
GPT-4o 示例 GPT-4o
文本转语音
a9
源代码 fishaudio / fish-speech (中英日) 示 模型文件 fishaudio/fish-speech-1
聊天机器人
(文本输出语音,可以中文输入,但是只能英文输出) 聊天机器人
输入图像和素材
合成新的图像 图像和素材合成
光线变换和背景替换
示例 IC-Light
*****************************************************************************************************
图像
OpenGVLab/InternVL-Chat-V1-5-Int8 图像描述(可中文) 示
openai-vision 代码仓库(OpenGVLab/InternVL-Chat-V1-5-Int8仓库可用)
a9 stabilityai/stable-video-diffusion-img2vid-xt 图像到视频(安装教程)
stabilityai/stable-diffusion-xl-refiner-1.0 图像到图像
stabilityai/stable-diffusion-xl-base-1.0 文本转图像
Stability-AI / generative-models (总的)
stabilityai/sd-turbo 文本转图像(5.2G)
stabilityai/sdxl-turbo 文本转图像(质量更好需要硬件更高13.9G、6.9G)
*****************************************************************************************************
b1 ModelScope 社区
b2 chatglm2-6b-int4 模型文件
b3 cogvlm-chat 模型文件 智谱多模态 示
b4 Cogagent—vqa 模型文件 视频问答
b5 cogvlm-base-490 模型文件 智谱图像描述 示
b6 通义千问-Audio-Chat 模型文件 多模态对话 示
qwen/Qwen-7B-Chat-Int4 模型文件 文本对话 示
直播商品类目识别模型-中文-电商领域
b7 iic/cv_resnet50_live-category 直播商品类目识别模型-中文-电商领域
多模态表征
iic/multi-modal_clip-vit-large-patch14_zh CLIP模型-中文-通用领域-large 示
b8 iic/cv_gpen_image-portrait-enhancement 人像修复增强(通义实验室)
b9 iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k 热词语音识别 (通义实验室)
b10 iic/nlp_csanmt_translation_zh2en 语义增强机器翻译-中翻英 (通义实验室)
b11 zh-cn-16k-common-vocab8404-pytorch 语音识别-中文-16k-长音频版(通义实验室)
b12 iic/cv_unet_image-colorization 图像上色(通义实验室)
b13 iic/cv_convnextTiny_ocr-recognition 文字识别-中英-通用(通义实验室) 示
b14 iic/cv_unet_image-matting BSHM人像抠图(通义实验室)
b15 iic/cv_unet_universal-matting BSHM通用抠图(通义实验室)
b16 iic/cv_effnetv2_video-human-matting 视频人像抠图-通用(通义实验室)
b17 iic/cv_hrnetocr_skychange 图像天空替换模型(通义实验室)
b18 iic/cv_resnet34_face 图片、性别、年龄范围(通义实验室)
b19 iic/cv_fft_inpainting_lama LaMa图像(2K)修复、填充和编辑(通义实验室)
b20 iic/cv_unet_skin-retouching ABPN人像美肤(通义实验室)
b21 iic/cv_resnest101_animal_recognition 动物识别-中文-通用(8k类)
b22 iic/person-image-cartoon DCT-Net人像卡通化模型(通义实验室)
文字识别
b23 iic/cv_convnextTiny_ocr 读光-文字识别中英-文档印刷体(通义实验室)
b24 ConvNextViT-通用场景
b25 ConvNextViT-自然场景
b26 ConvNextViT-车牌场景
b27 整图OCR-多场景
b28 iic/cv_raft_video-frame VFI-RAFT视频插帧(通义实验室)
b29 iic/cv_ddcolor_image-colorization DDColor图像上色
b30 iic/cv_dla34_table-structure 表格结构识别
文本生成视频
b31 iic/text-to-video-synthesis 文本生成视频大模型-英文-通用 示
b32 iic/Video-to-Video 高清视频生成视频大模型 示
iic/cv_dut-raft_video-stabilization DUT-RAFT视频稳像
iic/cv_clip-it_video-summarization 自然语言引导的视频摘要-英文
iic/cv_dro-resnet18_video-depth 视频流深度和相机轨迹估计
多模态
b33 iic/multi-clip-vit-patch16_zh CLIP模型-中文-通用领域(文生图可中文)
b34 iic/mplug_visual-question-answering mPLUG视觉问答模型
b35 iic/ofa_image-caption_coco_large_en OFA图像描述-英文
iic/multi-modal_hitea_video mPLUG-HiTeA-视频描述-英文
iic/cv_resnet50_video 短视频内容分类模型-中文
iic/blsp_lslm_7b BLSP-大规模语音语言模型-7B(支持语音文本交互)
日常动作检测
b36 iic/cv_ResNetC3D_detection2d 日常动作检测(如跌倒)
b36 iic/cv_vitb_video-single-object OSTrack视频单目标跟踪
iic/cv_yolov5_video-multi-object-tracking 视频多目标跟踪-行人
b37 iic/cv_aams_style-transfer AAMS图像风格迁移
b38 iic/cv_nafnet_image-deblur_reds NAFNet图像去模糊压缩
b39 iic/cv_flow-based-body-reshaping FBBR人体美型
b40 iic/cv_uhdm_image-demoireing uhdm图像去摩尔纹
b41 iic/cv_yolopv2_driving-perception YOLOPV2车辆检测车道线分割-自动驾驶
iic/cv_cspnet_video-object-detection LongShortNet实时视频目标检测-自动驾驶
行人结构化属性识别
b42 iic/cv_resnet50_pedestrian ResNet50行人结构化属性识别
b43 iic/mplug_image-text-retrieval_flickr30k mPLUG图文检索模型-英文
快速三维重建模型
b44 iic/cv_nerf-3d-reconstruction-accelerate_damo NeRF快速三维重建模型
实时烟火检测-通用
b45 iic/cv_tinynas_object-detection 实时烟火检测-通用
c1 AIStudio 社区
d1 始智AI 社区



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











