







residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
### 二、CBAM模块(Convolutional Block Attention Module)

该注意力模块( CBAM ),可以在**通道和空间维度上进行 Attention** 。其包含两个子模块 **Channel Attention Module(CAM)** 和 **Spartial Attention Module(SAM)**。
##### 1、CAM的结构是怎样的?与SE有何区别?

其结构如上图所示,相比SE,只是多了一个并行的Max Pooling层。那为什么加个并行的呢?结果导向,作者通过实验说明这样的效果好一些,我感觉其好一些的原因应该是多一种信息编码方式,使得获得的信息更加全面了吧,可能再加一些其他并行操作效果会更好?
##### 2、SAM的结构

将CAM模块输出的特征图作为本模块的输入特征图。首先做一个基于channel的**global max pooling** 和**global average pooling**,然后将这2个结果基于channel 做concat操作。然后经过一个卷积操作,降维为1个channel。再经过**sigmoid生成spatial attention feature**。最后将**该feature和该模块的输入feature做乘**法,得到最终生成的特征。下图是原文描述:

##### 3、组合方式
通道注意力和空间注意力这两个模块可以以并行或者顺序的方式组合在一起,但是作者发现顺序组合并且将通道注意力放在前面可以取得更好的效果。而且是先CAM再SAM效果会更好。论文还将结果可视化,对比发现添加了 CBAM 后,模型会更加关注识别物体:

##### 4、CBAM的代码实现
CBAM的 **Pytorch** 实现:
class Channel_Attention(nn.Module):
def \_\_init\_\_(self, channel, r):
super(Channel_Attention, self).__init__()
self.__avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.__max_pool = nn.AdaptiveMaxPool2d((1, 1))
self.__fc = nn.Sequential(
nn.Conv2d(channel, channel//r, 1, bias=False),
nn.ReLU(True),
nn.Conv2d(channel//r, channel, 1, bias=False),
)
self.__sigmoid = nn.Sigmoid()
def forward(self, x):
y1 = self.__avg_pool(x)
y1 = self.__fc(y1)
y2 = self.__max_pool(x)
y2 = self.__fc(y2)
y = self.__sigmoid(y1+y2)
return x \* y
class Spartial_Attention(nn.Module):
def \_\_init\_\_(self, kernel_size):
super(Spartial_Attention, self).__init__()
assert kernel_size % 2 == 1, "kernel\_size = {}".format(kernel_size)
padding = (kernel_size - 1) // 2
self.__layer = nn.Sequential(
nn.Conv2d(2, 1, kernel_size=kernel_size, padding=padding),
nn.Sigmoid(),
)
def forward(self, x):
avg_mask = torch.mean(x, dim=1, keepdim=True)
max_mask, _ = torch.max(x, dim=1, keepdim=True)
mask = torch.cat([avg_mask, max_mask], dim=1)
mask = self.__layer(mask)
return x \* mask
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

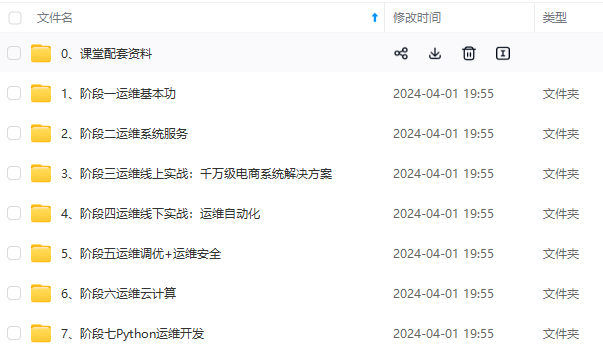
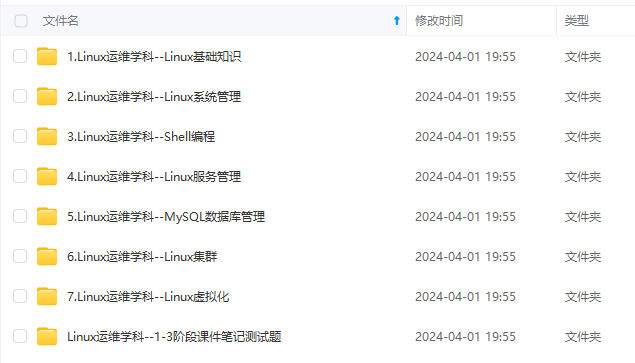
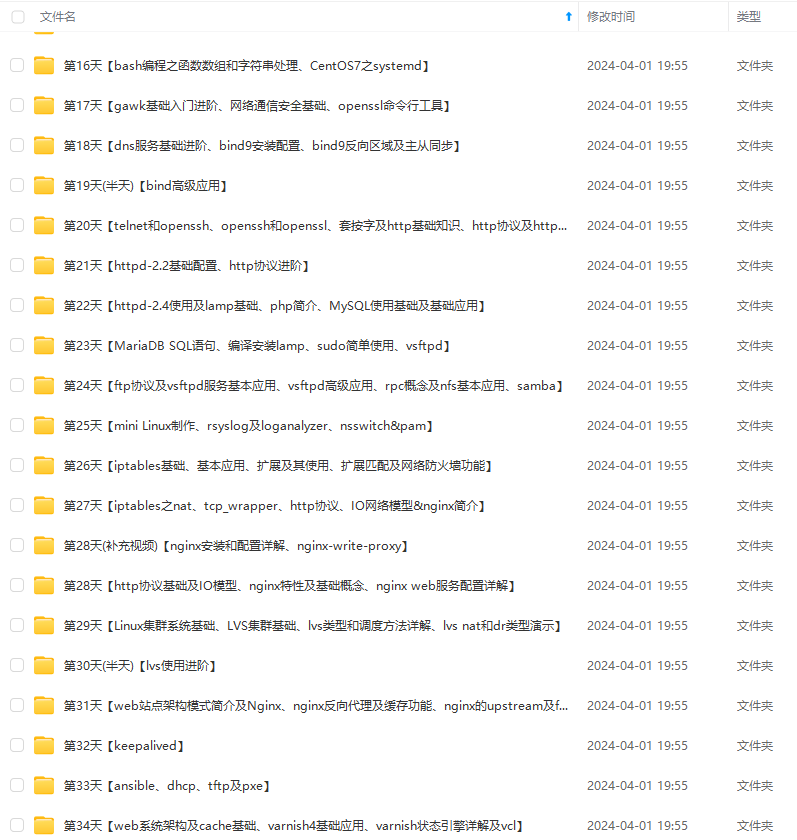
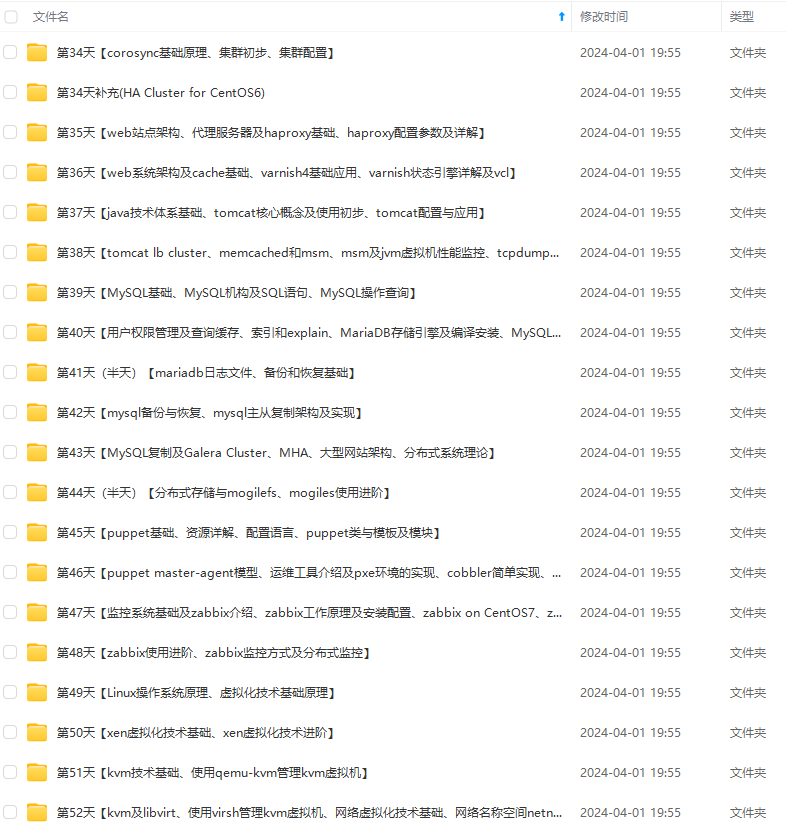
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)

最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
资料预览
给大家整理的视频资料:
给大家整理的电子书资料:

如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算
Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算**















 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









