






本文主要介绍如何:
1.选好损失函数为什么要用交叉熵比用均方差损失函数好
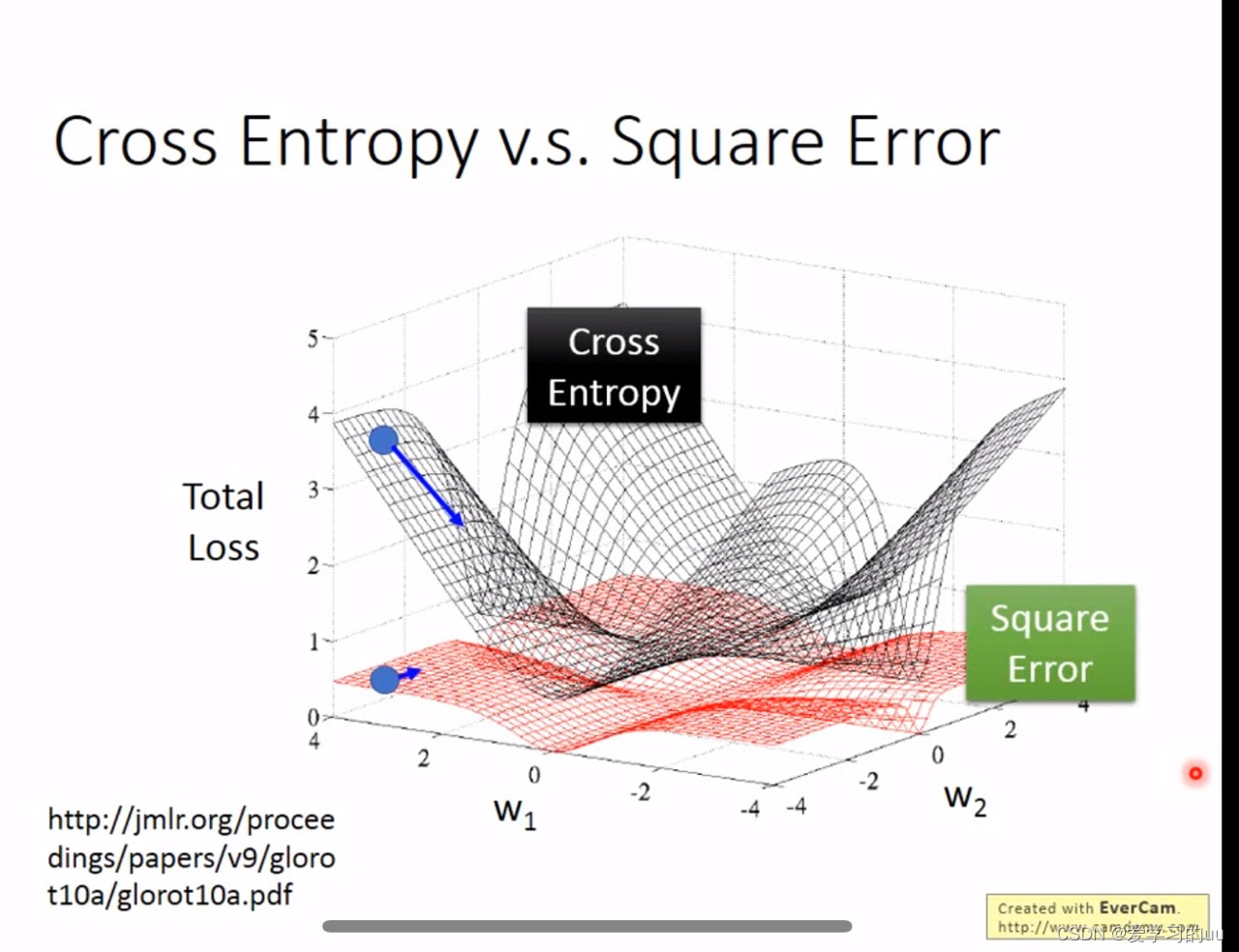
如果所示,黑色为交叉熵损失函数,可以看到以求得最小值为目标,交叉熵在远离目标值时梯度较大,可以更快的训练到目标值附近
2.在训练集和测试集上出现各种误差怎么调整
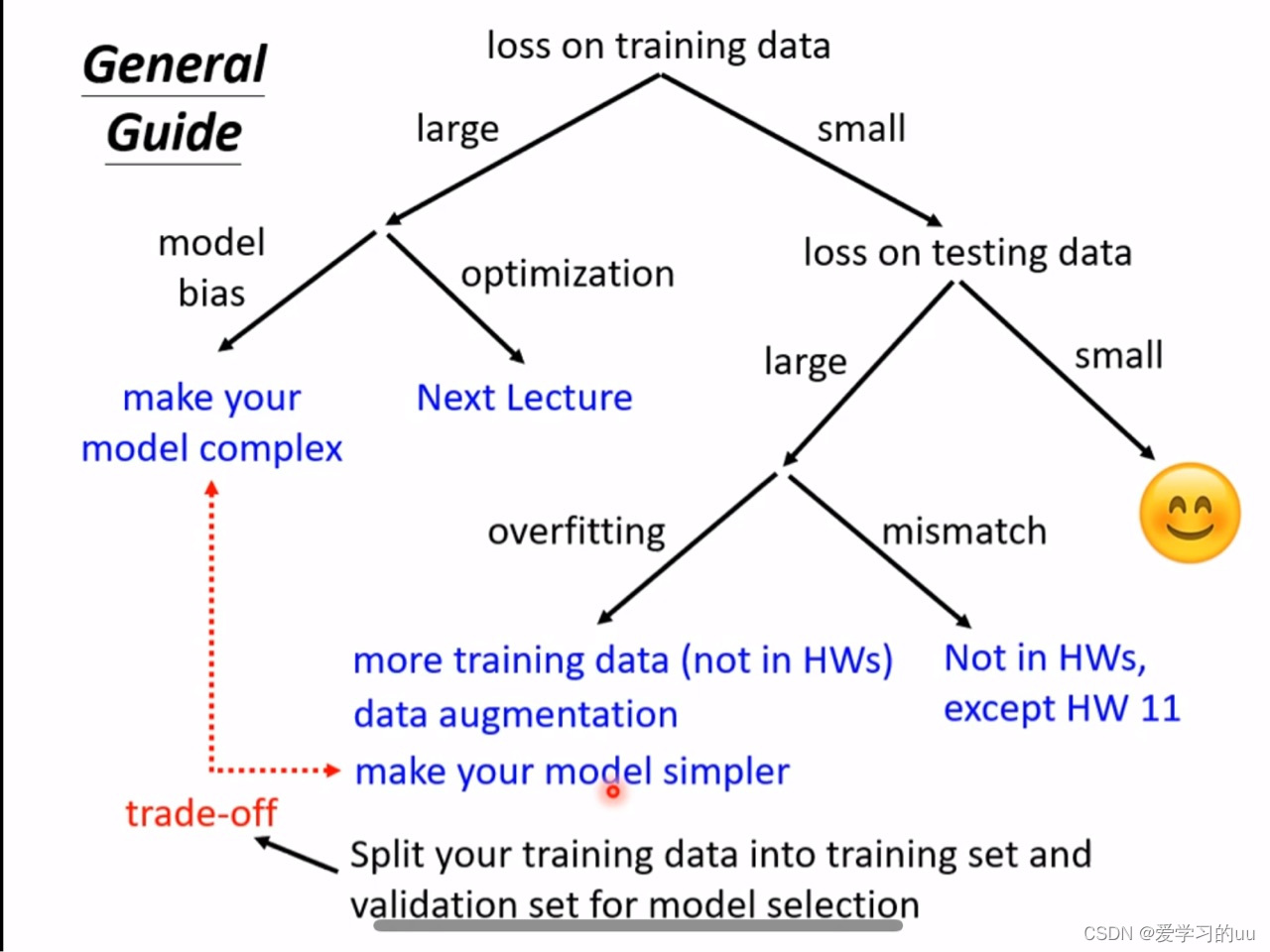
a.如果在训练集上误差就较大,则有两种可能:
模型深度不足或者没有找到最优解,如何判断是哪种情况:给模型加深度看误差是否减小,如果减小就说明是深度不足(不存在模型深度增加但是误差上升的模型,因为只要把后几层模型置空就可以保证效果至少和浅层模型一致)
b.训练集上误差小但测试集上误差大:过拟合或是
训练与验证集不匹配
针对过拟合:模型的复杂度高于数据的复杂度,解决方法有两个:增加训练数据量(收集更多的数据或是做数据增广)/增加对网络的限制(共享参数,CNN,减少特征,丢弃法,正则化)
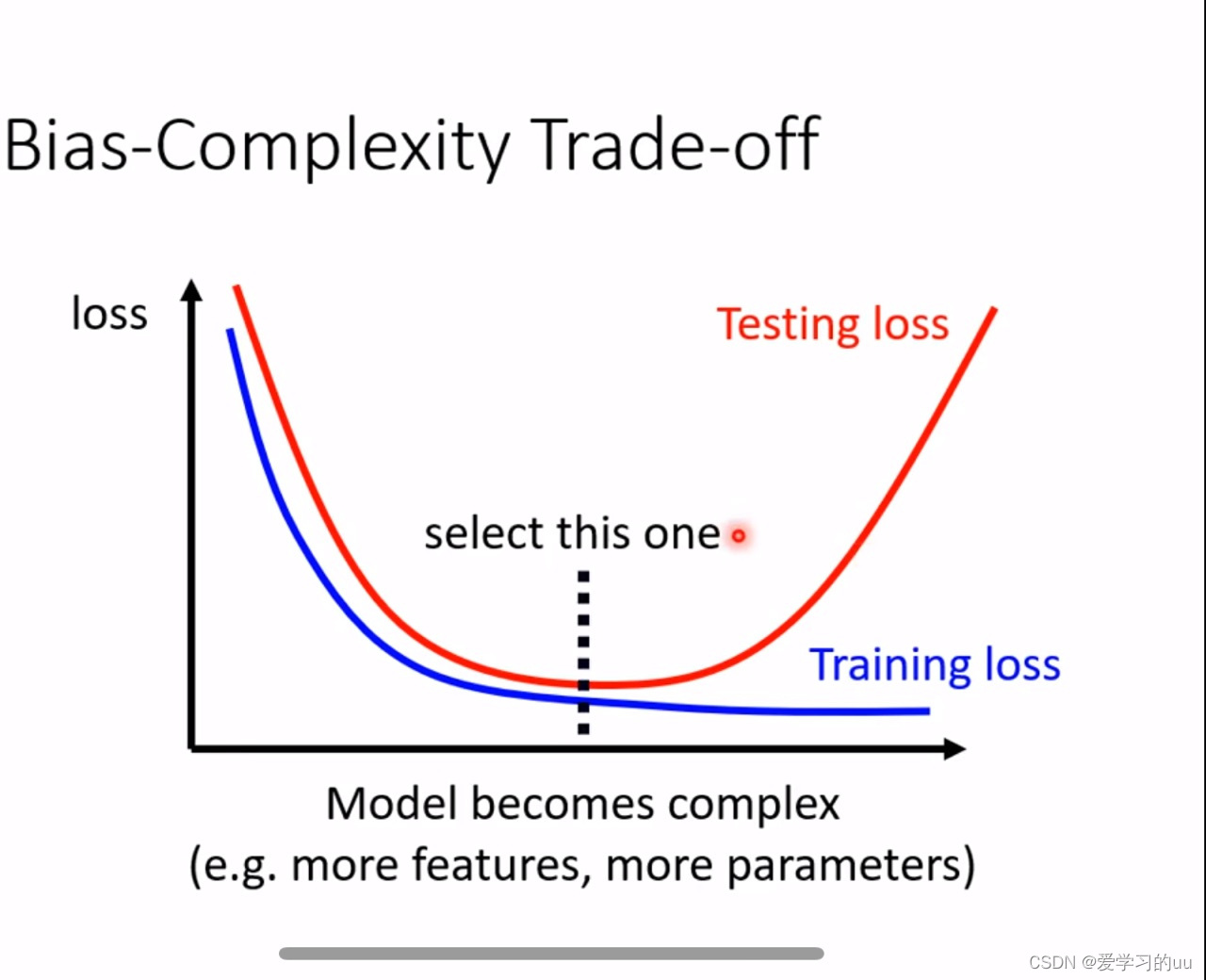
但是模型也不能过于简单,模型损失与复杂度关系如上图,我们尽量要找到黑线处
如果是第二种情况就无解了,因此要关注数据质量,推荐使用n折交叉法建立训练和验证数据库
3.神经网络训练不动怎么办
a.如果走进了第2点中说的没有训练到最好的点,如何判断它是局部最优值点还是鞍点(也就是沿某些方向训练,损失还会减少,但目前你没走这个方向的点)
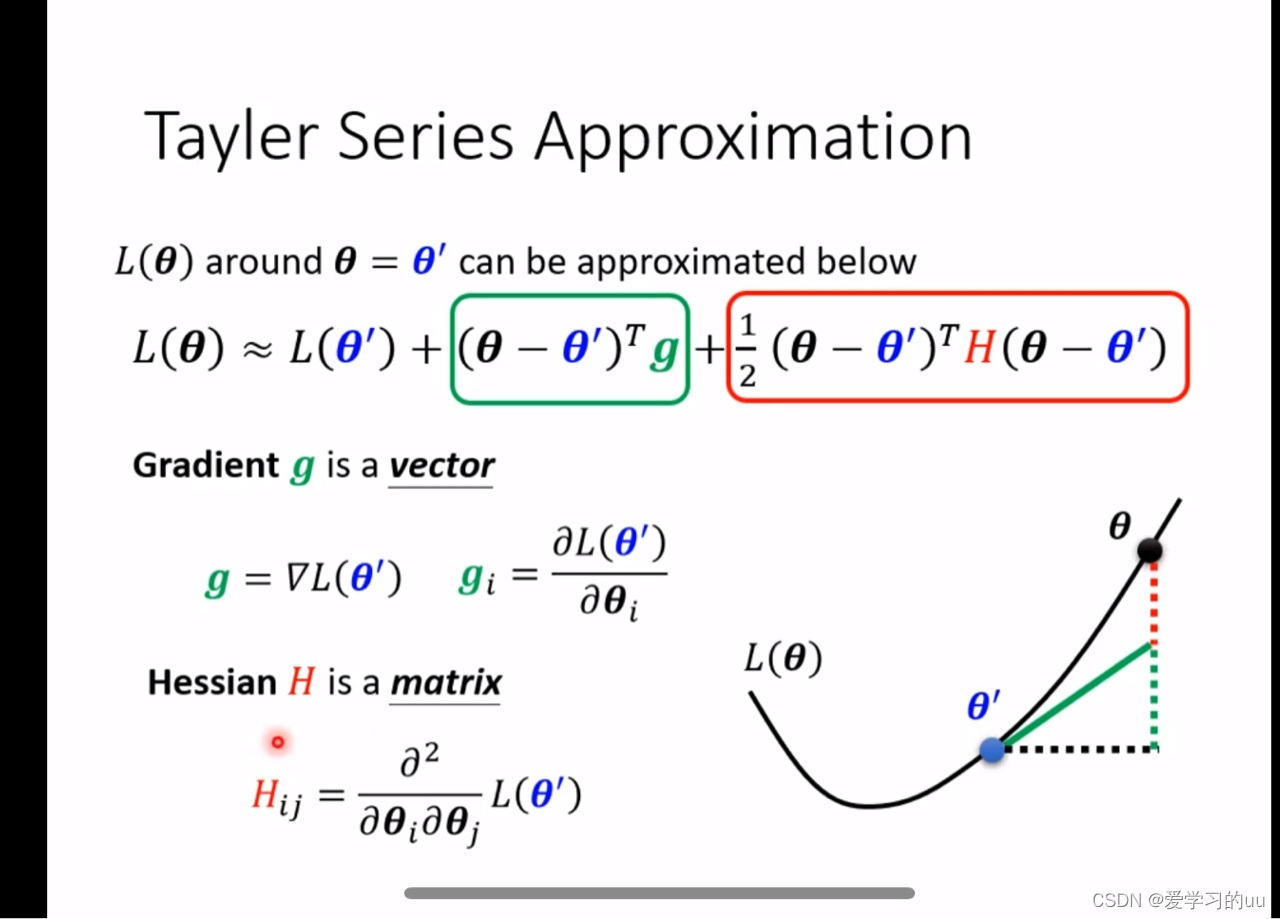
做泰勒展开可知, 当我们在鞍点时绿色这项为0,因此当第二项有时大于0,有时小于0时这是个鞍点,而这等价于看H(海森堡矩阵)的特征值有正也有负,如果全为正或者全为负则为最值点。在求出特征值后,对于负值求出特征向量即得可以走出鞍点的方向
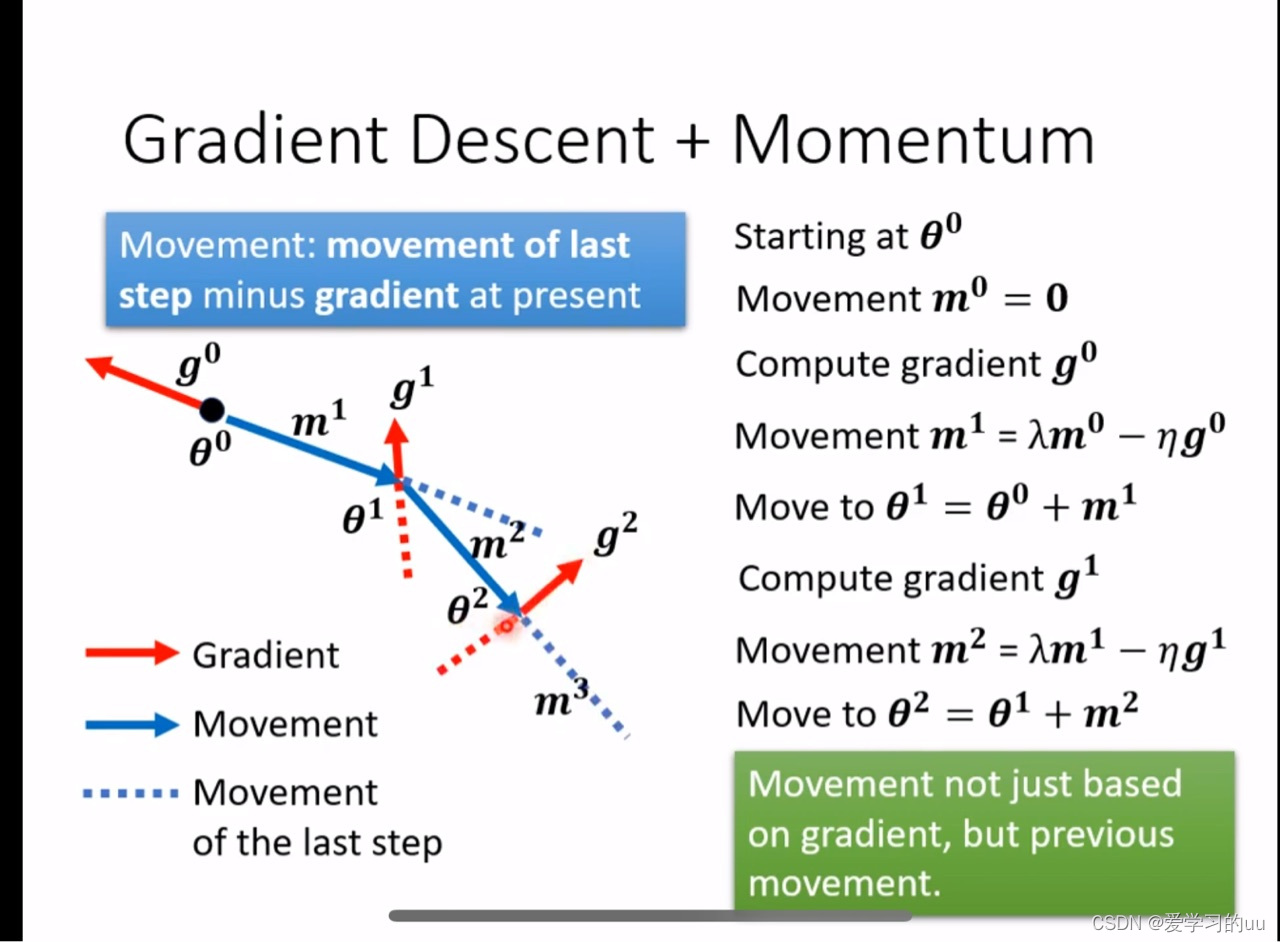
另外一种走出最小值点的方法:动量法
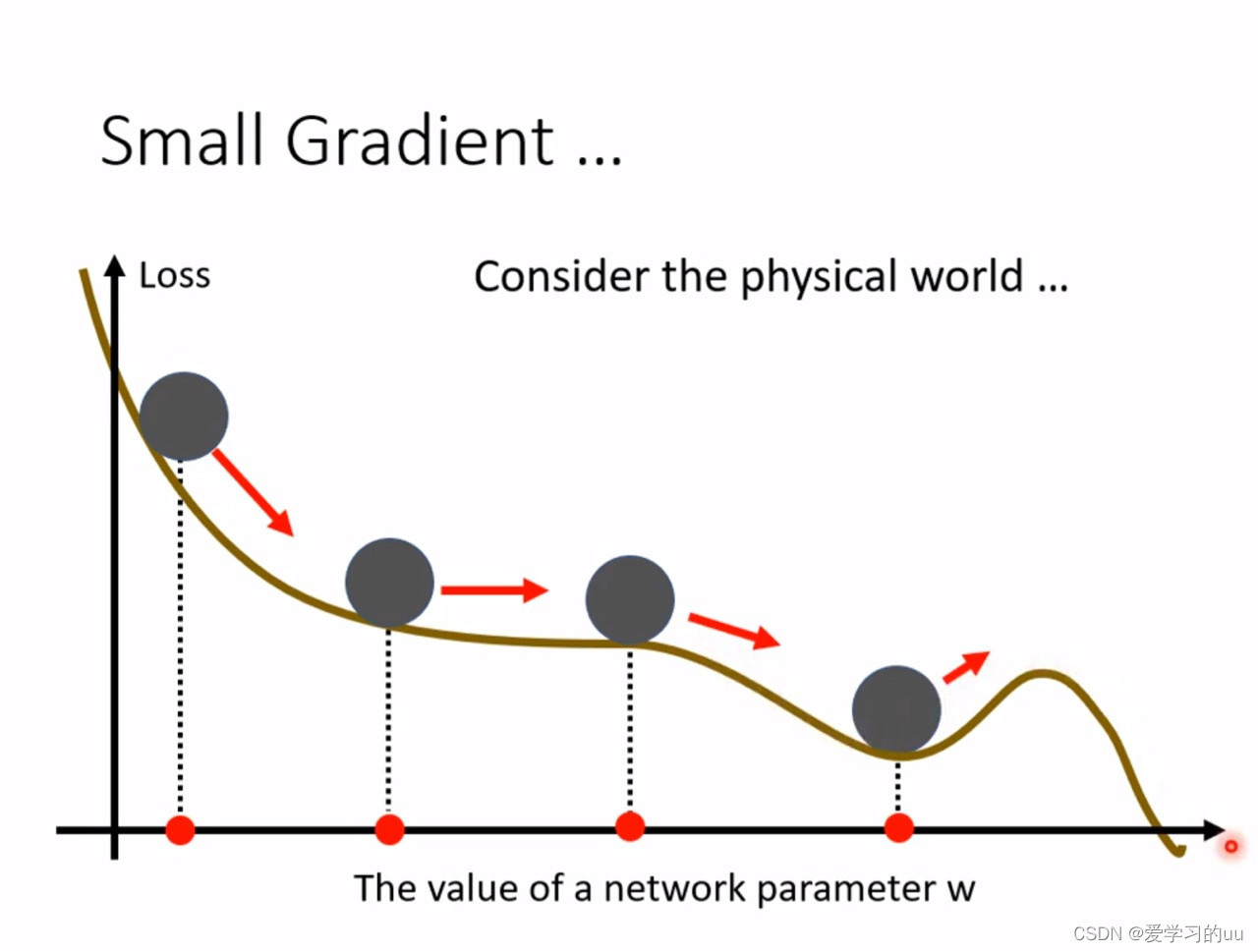
先从物理上理解一下:如果每次更新的方向不是只根据当次梯度下降的方向去更新,而是结合前一次的方向去更新,那图中第四个小球就可能走出局部 最小值点,计算公式如下:
b.如何选择用小批次还是大批次
首先纠正之前博文中的一个问题,在运行速度上,每个批次的样本量大的并不会比样本量小的运行速度慢很多,原因是gpu会做并行运算;而由于小批次训练的批次量更多,因此在并行计算下小批次反而训练时间长
其次,小批次比大批次的训练效果要好,原因如下:
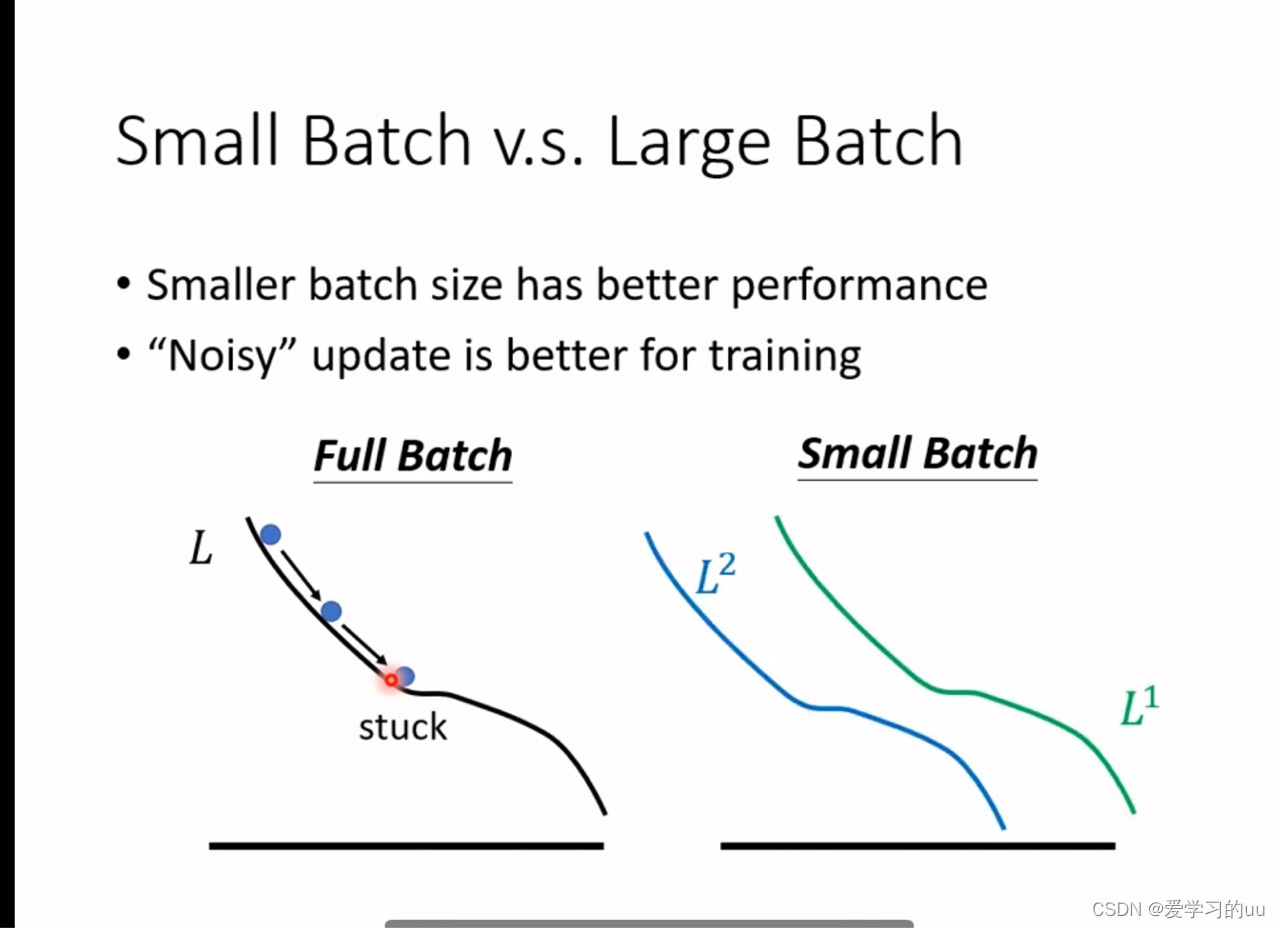
如果你拿整个数据集去训练,可能走到左图中的点就走不下去了,但如果有很多小批次,多做几次尝试后可能在另一个批次的曲线上能够走出这个局部最小值点,另外实验表明,小批次在测试集上的效果也更好
第三:小批次的训练效果会更不稳定














 786
786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









