






前言
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、实验目的
- 掌握TF-IDF的分析与计算过程
- 掌握使用TF-IDF实现向量空间模型的两种方法
(1) 调用gensim实现TF-IDF的计算
(2) 使用numpy,pandas,math实现TF-IDF的计算
二、实验内容
- 配置环境,安装anaconda,PyCharm或Spyder
- 调用gensim实现TF-IDF的计算
- 使用numpy,pandas,math实现TF-IDF的计算
1.代码
代码如下(示例):
三、实验步骤及编码
2.
from gensim import corpora, models, similarities
D1 = 'Shipment of gold damaged in a fire'
D2 = 'Delivery of silver arrived in a silver truck'
D3 = 'Shipment of gold arrived in a truck'
q = 'gold silver truck'
split1 = D1.split(' ')
split2 = D2.split(' ')
split3 = D3.split(' ')
splitq = q.split(' ')
listall = [split1, split2, split3]
dictionary = corpora.Dictionary(listall)
corpus = [dictionary.doc2bow(i) for i in listall]
tfidf = models.TfidfModel(corpus)
featureNUM = len(dictionary.token2id.keys())
index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features=featureNUM)
new_vec = dictionary.doc2bow(splitq)
sim = index[tfidf[new_vec]]
print(sim)
3.
import numpy as np
import pandas as pd
import math
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 1000)
D1 = 'Shipment of gold damaged in a fire'
D2 = 'Delivery of silver arrived in a silver truck'
D3 = 'Shipment of gold arrived in a truck'
split1 = D1.split(' ')
split2 = D2.split(' ')
split3 = D3.split(' ')
wordSet = set(split1).union(split2, split3)
。
def computeTF(wordSet, split):
tf = dict.fromkeys(wordSet, 0)
for word in split:
tf[word] += 1
return tf
tf1 = computeTF(wordSet, split1)
tf2 = computeTF(wordSet, split2)
tf3 = computeTF(wordSet, split3)
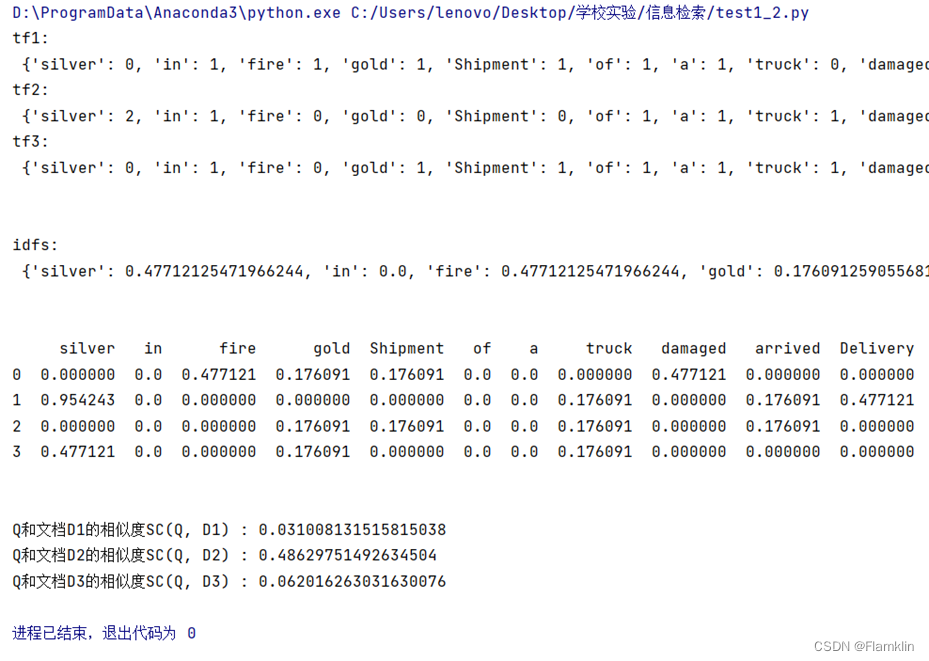
print('tf1:\n', tf1)
print('tf2:\n', tf2)
print('tf3:\n', tf3)
print("\n")
def computeIDF(tfList):
idfDict = dict.fromkeys(tfList[0], 0)
N = len(tfList)
for tf in tfList:
for word, count in tf.items():
if count > 0: idfDict[word] += 1 for word, Ni in idfDict.items(): idfDict[word] = math.log10(N / Ni) return idfDict
idfs = computeIDF([tf1, tf2, tf3])
print('idfs:\n', idfs)
print("\n")
def computeTFIDF(tf, idfs):
tfidf = {}
for word, tfval in tf.items():
tfidf[word] = tfval * idfs[word]
return tfidf
tfidf1 = computeTFIDF(tf1, idfs)
tfidf2 = computeTFIDF(tf2, idfs)
tfidf3 = computeTFIDF(tf3, idfs)
tfidf = pd.DataFrame([tfidf1, tfidf2, tfidf3])
q = 'gold silver truck'
split_q = q.split(' ')
tf_q = computeTF(wordSet, split_q)
tfidf_q = computeTFIDF(tf_q, idfs) ans = pd.DataFrame([tfidf1, tfidf2, tfidf3, tfidf_q])
print(ans)
print("\n")
print('Q和文档D1的相似度SC(Q, D1) :', (ans.loc[0, :] * ans.loc[3, :]).sum())
print('Q和文档D2的相似度SC(Q, D2) :', (ans.loc[1, :] * ans.loc[3, :]).sum())
print('Q和文档D3的相似度SC(Q, D3) :', (ans.loc[2, :] * ans.loc[3, :]).sum())
2.输出结果


总结
稀疏向量.dictionary.doc2bow(doc)是把文档doc变成一个稀疏向量,[(0, 1), (1, 1)],表明id为0,1的词汇出现了1次,至于其他词汇,没有出现。















 796
796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









