







一、研究背景和意义
在当今数字化和媒体饱和的时代,电影产业不仅是文化的重要组成部分,也是全球经济的一大推动力。电影不仅能够反映社会现实和文化趋势,还能预示和塑造公众的兴趣与期待。因此,深入分析电影数据集具有重要的实践和理论意义。通过对电影数据进行描述性统计分析,在电影数据集的分析过程中,描述性统计分析提供了一个宏观的视角,揭示了电影行业的基本运行模式和市场表现。进一步地,而在机器学习领域,随机森林模型的应用则开启了预测电影市场行为的新篇章。。。
二、数据集介绍
淘票票平台的电影数据集提供了一个独特的视角,让我们能够深入探究中国电影市场的复杂性与动态变化。这份数据集汇集了从2000年至2020年间上映的250部影片的详尽信息
三、描述性统计分析与可视化
首先导入基本的画图的包
# 导入基本的画图的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文读取 CSV 文件并且展示数据前五行:
# 读取 CSV 文件
movies_data = pd.read_csv('movies.csv')
movies_data.head()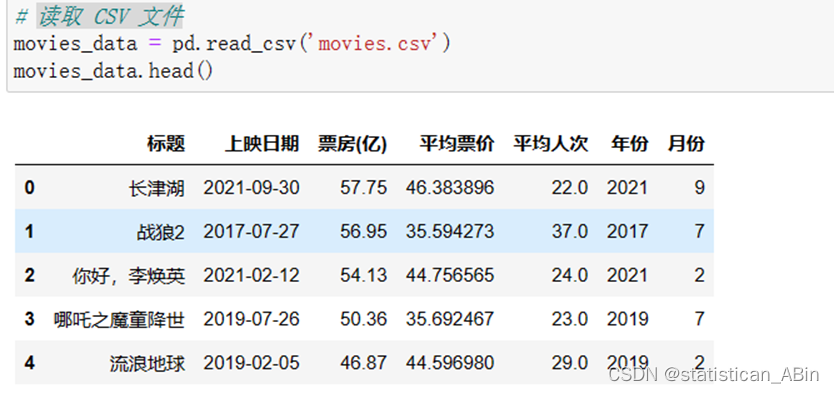 随后对数据进行描述性统计分析:
随后对数据进行描述性统计分析:

统计分析覆盖了五个不同的数值变量:票房(亿)、平均票价、平均人次、年份和月份。对于每个变量,提供了以下统计指标:count:每个变量的观测值数量,此处每个变量均为250个观测值。mean:平均值,反映了中心趋势。
查看数据基础信息:
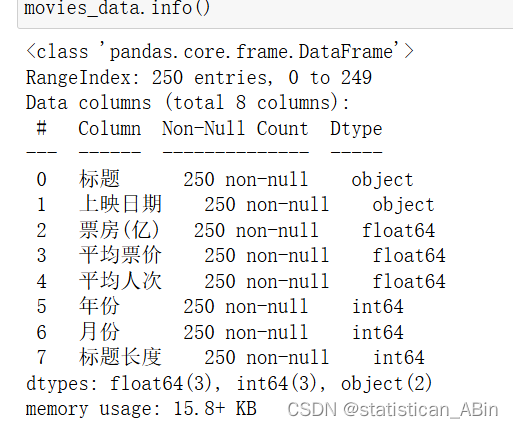
接下来查看缺失值:
###数据预处理
#观察缺失值
import missingno as msno
msno.matrix(movies_data)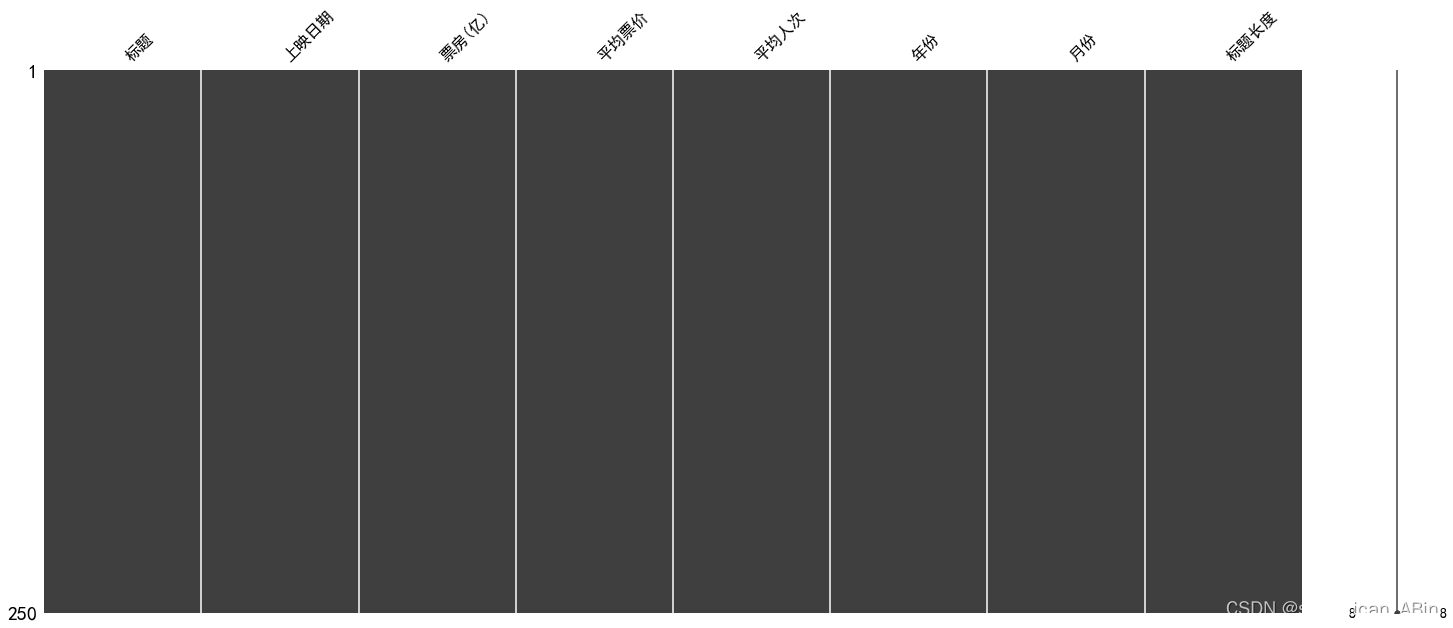
从上面可以看出,数据集比较完整,数据没有缺失值。
接下来对数据进行可视化分析部分:
# 散点图:票房与平均票价的关系
sns.scatterplot(data=movies_data, x='平均票价', y='票房(亿)', ax=axes[0, 0])
axes[0, 0].set_title('票房与平均票价的关系')
axes[0, 0].set_xlabel('平均票价')
axes[0, 0].set_ylabel('票房(亿)')
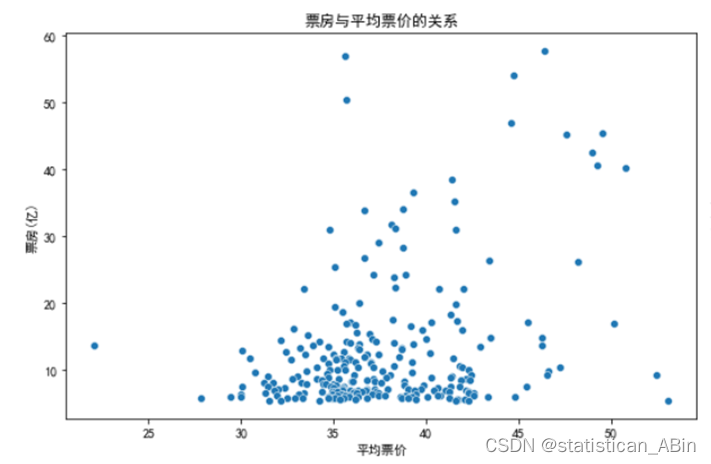
在上图所示的票房与平均票价的散点图中,我们可以观察到平均票价与票房之间的一种关联模式:随着平均票价的上升,票房也显示出增长趋势。这样的电影往往伴随着大规模的宣传和营销活动,能够吸引大量观众进电影院,从而推动高票房收入的产生。
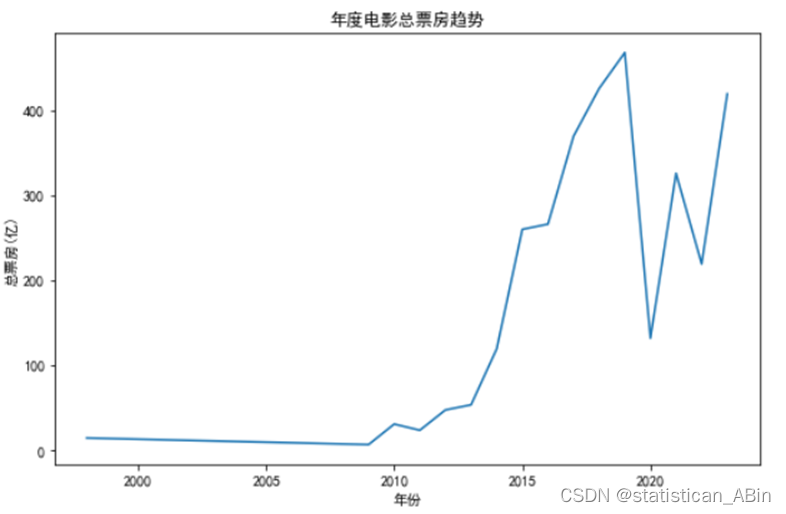
在上图展现的年度票房总和的时间序列图中,通过一条清晰的折线,我们能够追踪2000年至2020年20年间电影票房的发展轨迹。这个图形不仅揭示了整体上升的大趋势,而且还描绘出了一些特别的增长时期,如2000年末至2010年期间的快速上升,以及2015年后的另一轮显著增长。
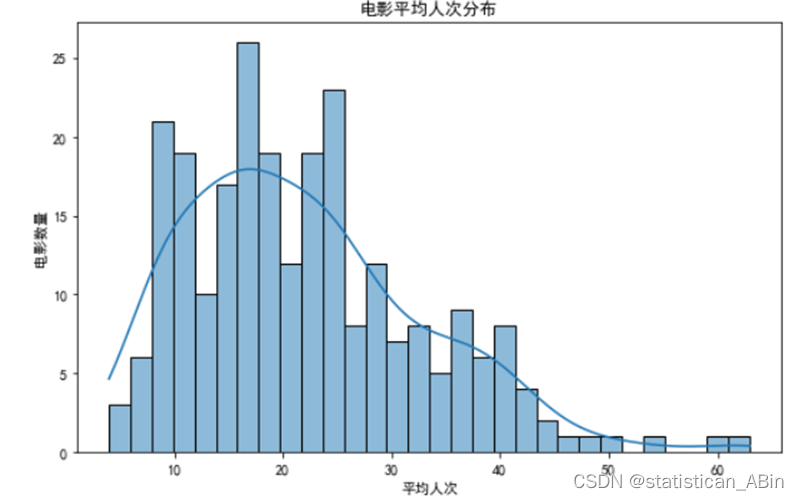
上图是电影平均人次的直方图,上面叠加了一个拟合的概率密度曲线。这个图表显示了电影平均人次的分布情况。直方图显示,电影的平均人次集中在较低的范围内,大多数电影的平均人次在30次以下,呈现出接近正态分布的形态。
plt.figure(figsize=(10, 6))
movies_per_year = movies_df['年份'].value_counts()
plt.pie(movies_per_year, labels=movies_per_year.index, autopct='%1.1f%%', startangle=90)
plt.title('每年电影数量分布')
plt.show()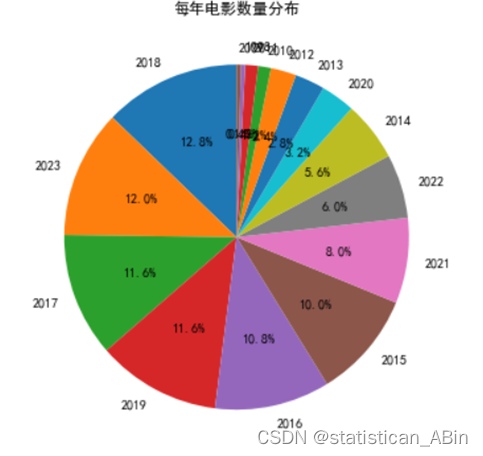
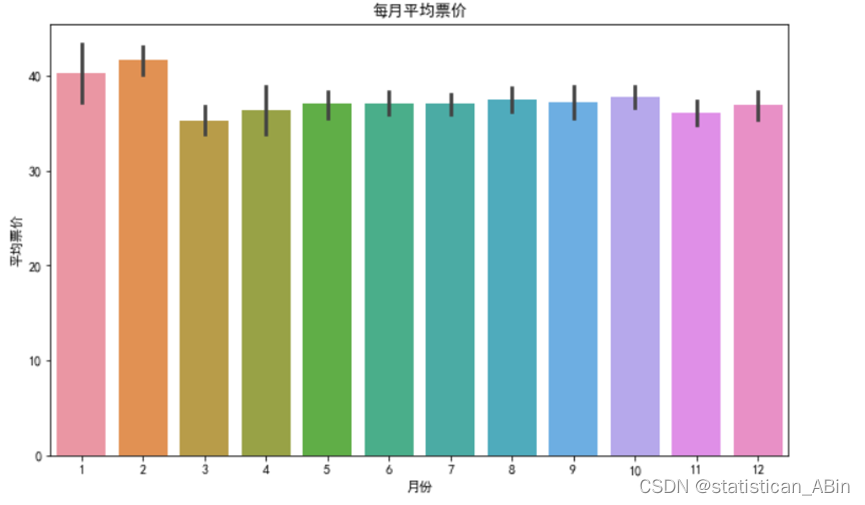
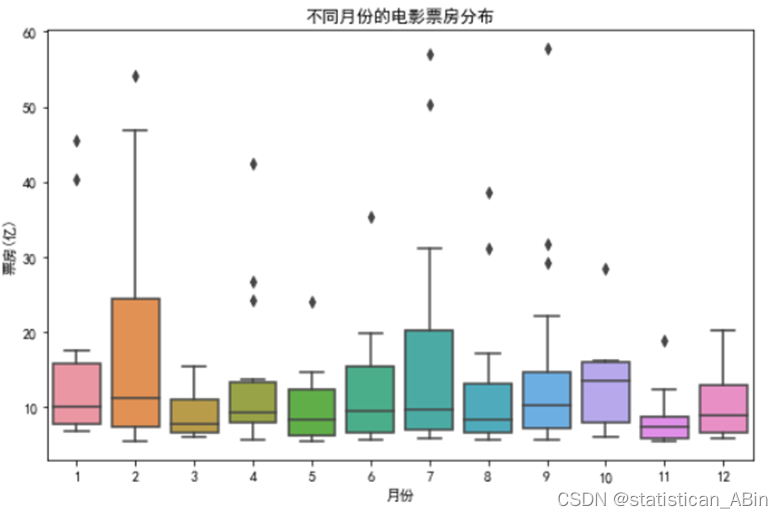
柱状图上的误差线提供了关于每月平均票价变异性的信息。从图中可以观察到,虽然各月份的平均票价相差不大,但仍有一定的波动,这可能受到季节性因素和不同月份电影类型及数量的影响。
接下来使用相关性热力图看一下个特征之间的关系:
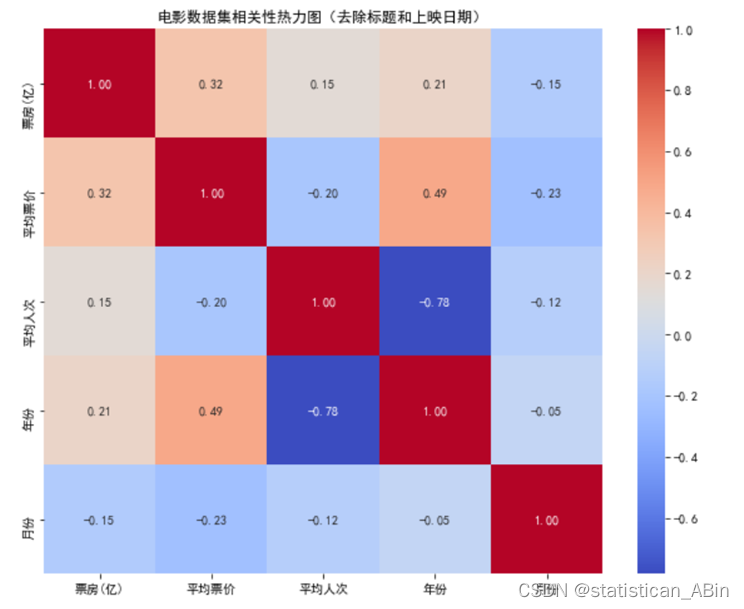
这显示了一个相关性热力图,它展示了电影数据集中几个数值变量之间的相关性系数。热力图的颜色变化从红色到蓝色代表了相关性系数的范围,红色表示正相关,蓝色表示负相关,颜色的饱和度表示相关性的强度。
四、时间序列方法研究和分析
接下来使用使用时间序列方法中的移动平均来平滑数据,这可以帮助我们更好地理解票房随时间的整体趋势。
# 计算年度票房的移动平均值
movies_data['年份'] = movies_data.index.year
yearly_box_office = movies_data.groupby('年份')['票房(亿)'].sum()
rolling_mean = yearly_box_office.rolling(window=3).mean()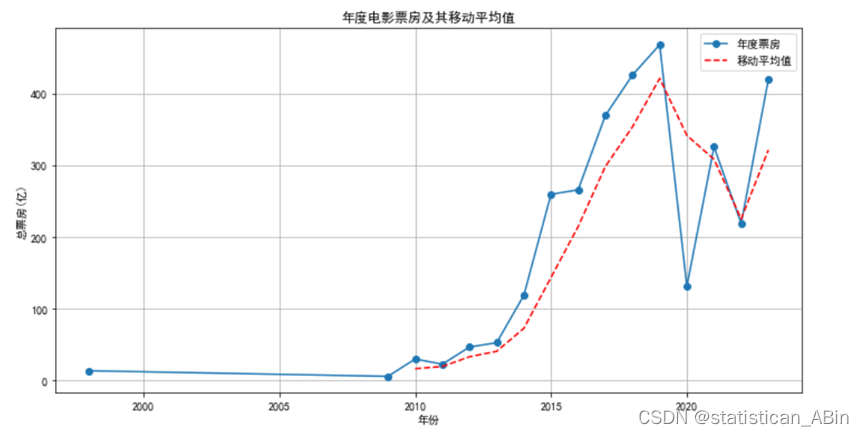
上图显示了两条趋势线:一条表示原始数据的年度票房总和,另一条表示通过移动平均方法平滑后的数据。从图中可以看出,原始数据的趋势线(实线)在某些年份出现了尖峰或下降,这可能是由于特定的市场事件、重大电影发布或外部经济因素造成的。。。。
移动平均是一种常用的数据分析技术,特别是在时间序列数据分析中,它可以帮助分析师识别和跟踪数据的长期趋势和周期性模式。通过对原始数据应用移动平均,我们可以更清晰地看到总体的增长趋势,以及潜在的上升或下降周期。这种分析方法对于市场分析师、投资者和决策者来说是非常有价值的,因为它提供了对未来市场动态的洞见,有助于做出更加信息化的决策。
五、随机森林模型预测与分析
接下来使用随机森林模型来预测,其中票房为响应变量,其他为特征,训练集测试集划分比例为7:3,具体代码如下:
# 创建并训练随机森林回归模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = rf_model.predict(X_test)
# 计算模型性能指标
mse_rf = mean_squared_error(y_test, y_pred)
r2_rf = r2_score(y_test, y_pred)
# 可视化预测结果与实际值
plt.figure(figsize=(12, 6))
plt.scatter(y_test, y_pred, alpha=0.5)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2) # 对角线
plt.xlabel('实际票房')
plt.ylabel('预测票房')
plt.title('随机森林回归模型的预测效果')
plt.show()
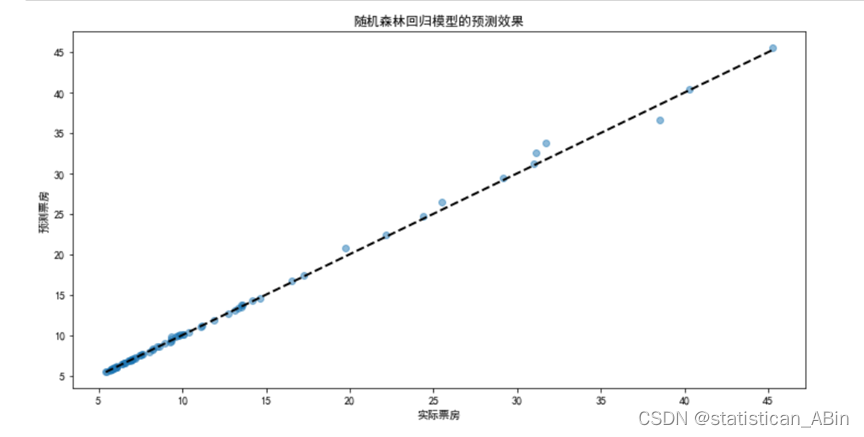
该散点图显示了预测值和实际值之间的关系,并配有一条拟合线。这条拟合线表示的是变量之间的线性关系,而散点图上的点代表观测数据。
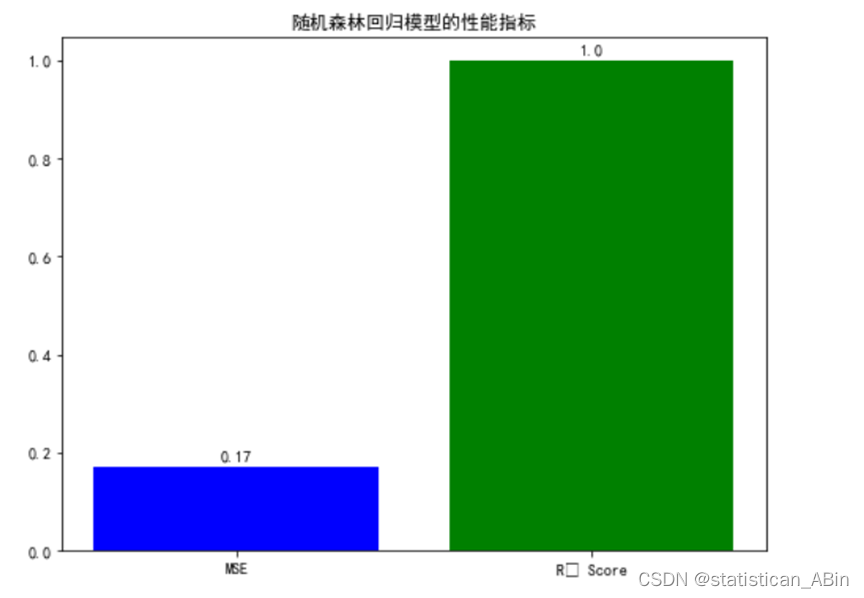 在这个图表中,R²分数是0.997,这意味着模型的预测非常准确,而MSE的值很低(0.169),表明模型的预测误差较小。这样的结果通常表明模型在统计上是成功的,能够很好地捕捉到数据中的模式和关系。
在这个图表中,R²分数是0.997,这意味着模型的预测非常准确,而MSE的值很低(0.169),表明模型的预测误差较小。这样的结果通常表明模型在统计上是成功的,能够很好地捕捉到数据中的模式和关系。
六、文本分析与可视化
接下来针对标题长度分布做一个文本分析:
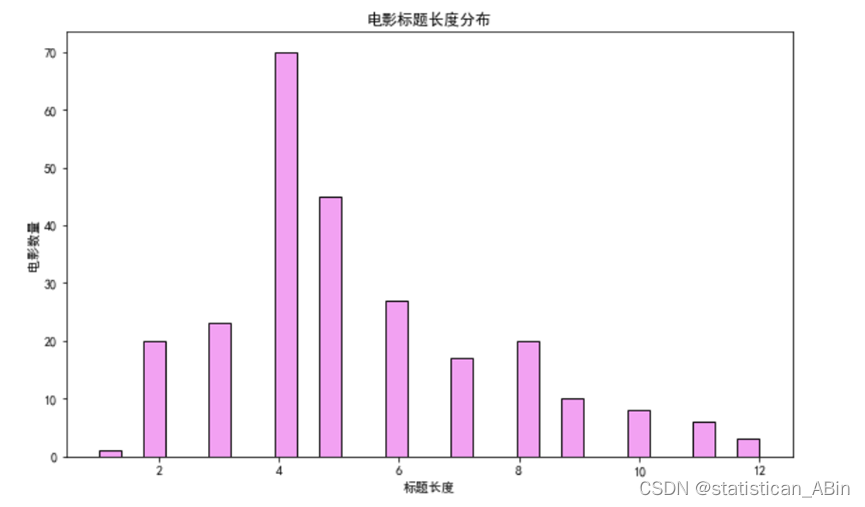
从这个柱状图中,我们可以看到大多数电影的标题长度集中在较短的区间内,尤其是在4到6个字符之间的标题数量最多,这可能表明在电影标题的设计上倾向于简洁明了,以便观众容易记忆和识别。
七、总结和展望
总结以上分析,我们可以看到数据科学在电影产业中的应用是多方面的,从基础的统计分析到复杂的机器学习模型,都能提供有价值的见解。描述性统计帮助我们理解了市场的基本面貌,时间序列分析揭示了电影票房的动态趋势,随机森林模型使我们能够预测并理解电影成功的驱动因素,而文本分析提供了对市场营销策略的深入理解。
展望未来,随着数据科学技术的进步和数据收集能力的提高,我们可以预期在电影产业中的数据分析会更加精细化和个性化。。。
创作不易,希望大家多点赞关注评论!!!(类似代码或报告定制可以私信)















 2290
2290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









