







一、研究背景和意义
人的心脏有四个瓣膜,主动脉银、二尖、肺动脉和三尖源 不管是那一个膜发生了病变,都会导致心脏内的血流受到影响,这就是通常所说的心脏期膜病,很多是需要通过手术的方式进行改善的。随着人口老龄化的加剧,,心脏期膜病是我国最常见的心血管疾病之-,需要接受心脏瓣膜手术治疗的患者数量逐年拳升。心脏期膜手术是对病变的心脏辨膜所进行的外科手术,一般包括心脏期的置换和修复手术,心期手术是在外科技术的基础上,对病变的心脏期膜所进行的手术,可以改善患者心脏期聘狭窄或关闭不全的现象。不过心脏瓣膜病手术可能会引发机械瓣并发症,导致心功能变差,严重的还会直接造成患者死亡。
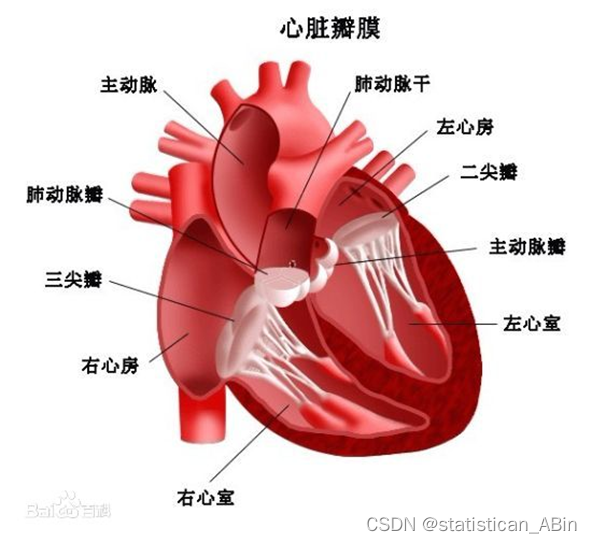
由于心瓣膜手术有一定的病死率,因此需要根据心脏瓣膜手术数据建立相应的手术风险预测模型,以规范术前风险评估工作 进一步降低手术期病死率,提高心脏瓣膜手术成功率。风险预测模型常用于根据当前患者的情况如基础特征、医学指标的值等)来预测惠者未来的健康结果,例如心脏瓣膜手术后的短期死亡率(结果变量:30天内存活死亡),癌症长期死亡率(结果变量: 死亡时间) 等。
本实验通过以往患者心脏瓣膜手术数据信息,建立基于机器学习的预测,从跳性心病惠者中快速筛选出可能会导致手术死亡的高危惠者,并将风险预测的相关信息提供给临床医生作为临床指导,以便及时做出治疗决策,例如低风险的患者通常被建议观察,而更多的医疗资源将分配给高风险的患者等。这样有助于选择合适的治疗方案,推动个性化医疗的发展。
二、实证分析
接下来进行实证分析实证分析
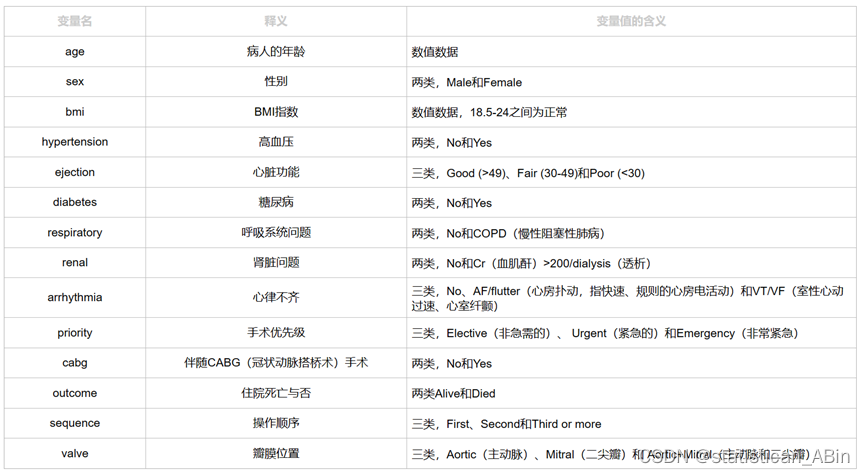
数据集各字段如下:
首先导入数据分析基本的包:
import pandas as pd
# Load the dataset
file_path = '历史患者手术信息数据.csv'
data = pd.read_csv(file_path)
# Display the first few rows of the dataset
data.head() 
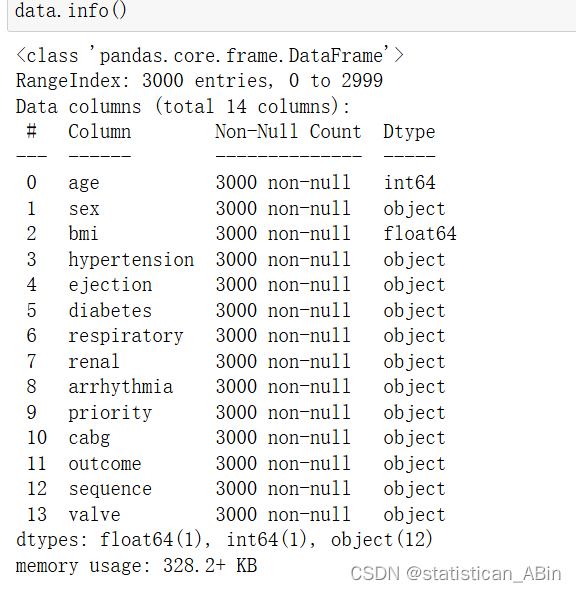
显示数据的基本信息
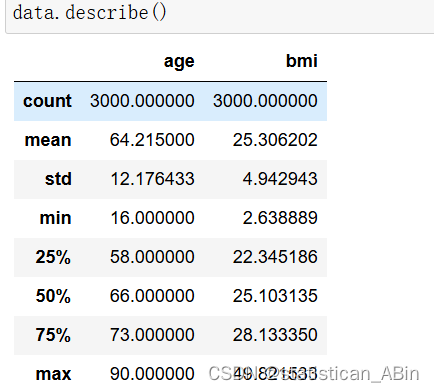
显示数值特征的统计描述
接下来检查缺失值情况
data.isnull().sum()
接下来查看数值特征分布可视化
numeric_features = ['age', 'bmi']
fig, axes = plt.subplots(1, 2, figsize=(15, 5))
for i, feature in enumerate(numeric_features):
sns.histplot(data[feature], kde=True, ax=axes[i])
axes[i].set_title(f'{feature} Distribution')
plt.tight_layout()
plt.show() 
类别特征分布
for i, feature in enumerate(categorical_features):
sns.countplot(x=feature, data=data, ax=axes[i])
axes[i].set_title(f'{feature} Distribution')
axes[i].tick_params(axis='x', rotation=90)
plt.tight_layout()
plt.show() 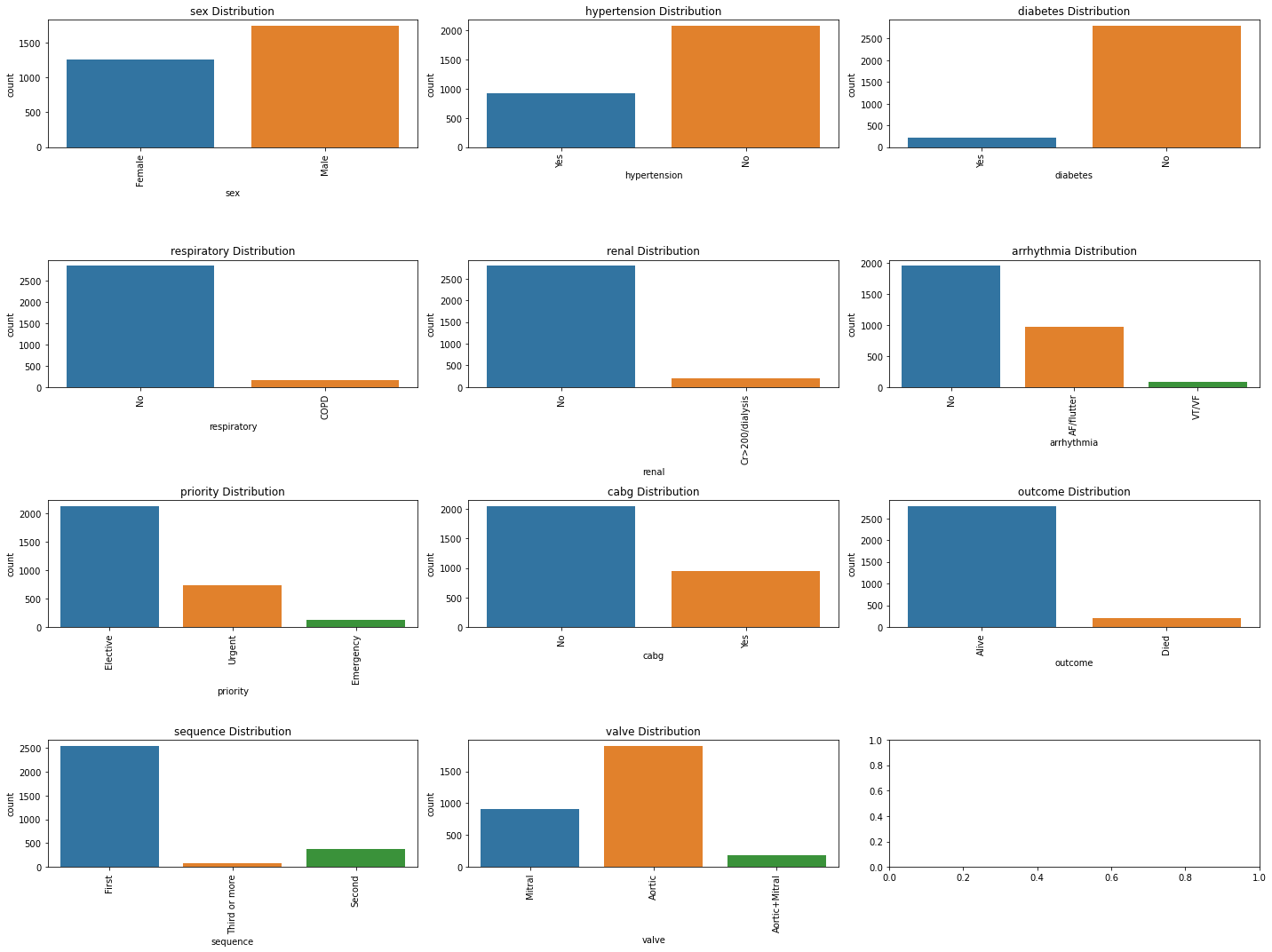
接下来查看不同类别下特征的分布
fig, axes = plt.subplots(1, 2, figsize=(15, 5))
for i, feature in enumerate(numeric_features):
sns.boxplot(x='outcome', y=feature, data=data, ax=axes[i])
axes[i].set_title(f'{feature} Distribution by Outcome')
plt.tight_layout()
plt.show()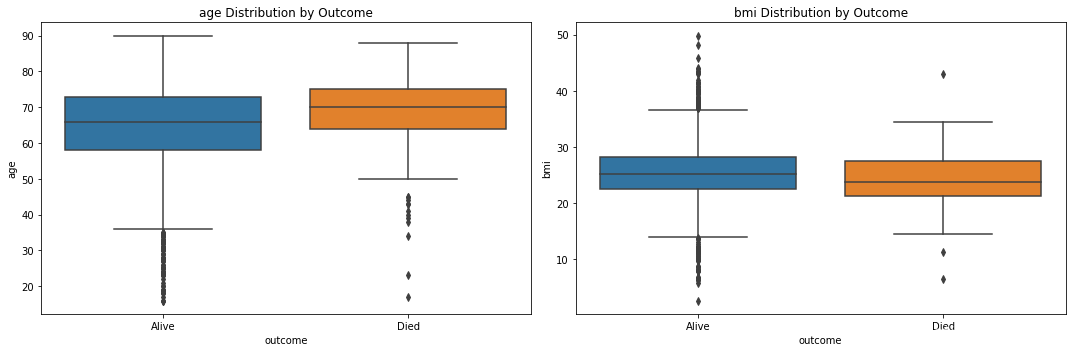
接下来对类别特征进行独热编码
data_encoded = pd.get_dummies(data, drop_first=True)
data_encoded.head()
接下来进行特征处理,分离特征和响应变量并且数据划分为训练集和测试集
from sklearn.model_selection import train_test_split
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)接下来使用随机森林进行分类建模
# 初始化随机森林分类器
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
rf_model.fit(X_train, y_train)
具体结果如下
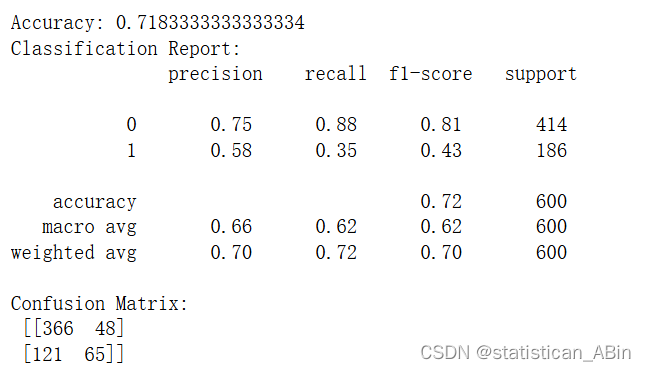
接下来我们进行随机森林可视化
# 显示随机森林中的一棵树
plt.figure(figsize=(20, 10))
plot_tree(rf_model.estimators_[0], filled=True, feature_names=X.columns, class_names=['Class 0', 'Class 1'])
plt.show()
计算并可视化特征重要性
plt.figure(figsize=(10, 8))
sns.barplot(x='Importance', y='Feature', data=feature_importances_df)
plt.title('Feature Importances in Random Forest Model')
plt.show()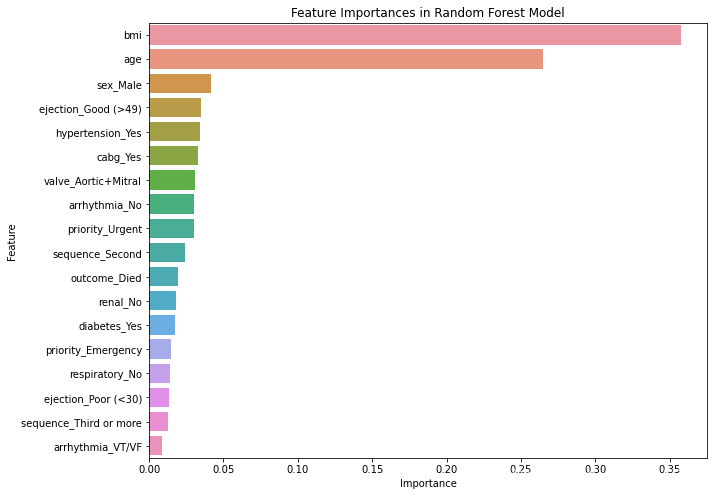
从上面可以看出,BIM和AGE的影响程度是最大的,其次是性别。。。
三、小结
结论:
本研究通过对心脏瓣膜手术数据的分析和建模,建立了基于机器学习的手术风险预测模型。通过对历史患者手术信息数据的清洗、特征处理和随机森林建模,我们能够从众多患者中快速筛选出可能导致手术死亡的高危患者,并将风险预测信息提供给临床医生作为参考,以便及时做出治疗决策。通过对随机森林模型的评估,我们发现该模型具有较高的准确性和可靠性,可以为临床医生提供有价值的决策支持。同时,我们也对模型进行了可视化,以便更直观地展示模型的预测结果。
展望:
本研究为心脏瓣膜手术风险预测提供了一种新的方法和思路,但仍存在一些不足之处。未来的研究可以从以下几个方面进行改进和完善:
- 数据方面:进一步扩大数据集,增加更多的特征变量,以提高模型的准确性和泛化能力。
- 模型方面:尝试使用其他机器学习算法或集成学习方法,如支持向量机、神经网络、Adaboost 等,与随机森林进行比较和优化,以找到更适合的模型。
- 临床应用方面:将模型应用于实际临床环境中,进行进一步的验证和优化,以提高模型的实用性和临床价值。
- 个性化医疗方面:结合患者的个体特征和医疗史,进一步推动个性化医疗的发展,为患者提供更精准的治疗方案。
总之,心脏瓣膜手术风险预测是一个具有挑战性的问题,需要综合考虑多种因素。本研究为该领域的发展提供了一定的参考,但仍需要不断地探索和创新,以提高手术的安全性和成功率,为患者的健康保驾护航。
创作不易,希望大家多点赞关注评论!!!(类似代码或报告定制可以私信)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









