







一、研究背景
共享单车作为一种绿色、便捷的出行方式,近年来在全球范围内迅速发展。共享单车不仅减少了城市交通拥堵和污染,还为居民提供了健康的出行选择。随着城市化进程的加快和环保意识的增强,共享单车已成为许多城市居民日常通勤和休闲娱乐的重要工具。共享单车的推广不仅有助于缓解交通压力、减少碳排放,还可以促进健康生活方式,提升城市生活质量。
二、研究意义
共享单车的推广不仅有助于缓解交通压力、减少碳排放,还可以促进健康生活方式,提升城市生活质量。因此,准确预测共享单车的租赁需求,对于合理调度单车资源、提升用户体验具有重要意义。。。。。
三、实证分析
首先导入数据分析所需要的基础的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error, r2_score接下来读取数据集并且展示前五行
file_path = 'data.csv'
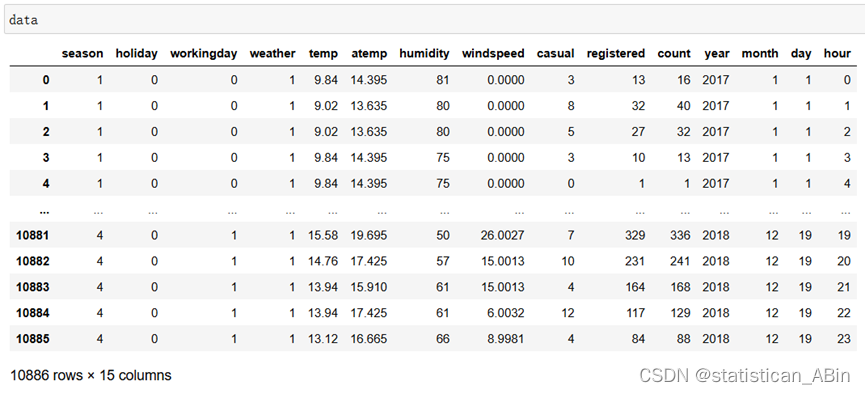
data = pd.read_csv(file_path)该数据集共有10886条记录和12个特征列。特征包括日期时间(datetime)、季节(season)、是否节假日(holiday)、是否工作日(workingday)、天气情况(weather)、温度(temp)、体感温度(atemp)、湿度(humidity)、风速(windspeed)、非注册用户的租赁次数(casual)、注册用户的租赁次数(registered)以及总租赁次数(count)。
接下来查看数据类型
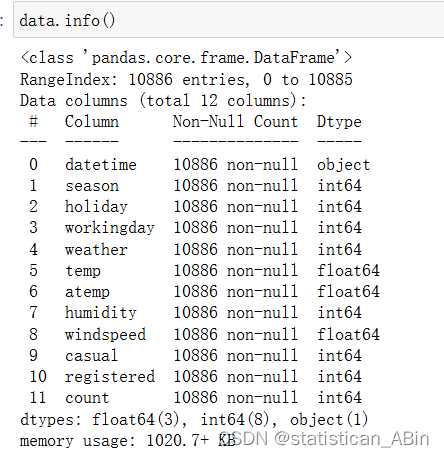
从上面可以看见,除了日期时间列为对象类型外,其他特征均为数值型数据。数据集的内存使用量约为1020.7 KB。
接下来处理 datetime 特征,将其划分为年月日小时分割开来,为了后续建模使用
接下来填充并且查看缺失值
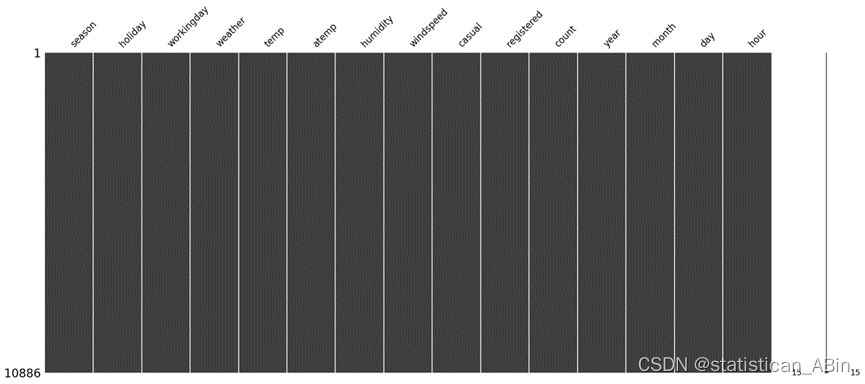
从缺失值可视化图查看发现不存在缺失值。接下来进行特征可视化:
首先可视化气温的直方图:
plt.figure(figsize=(10, 6))
data['temp'].hist(bins=50, color='skyblue')
plt.xlabel('Temperature')
plt.ylabel('Frequency')
plt.title('Histogram of Temperature')
plt.grid(True)
plt.show()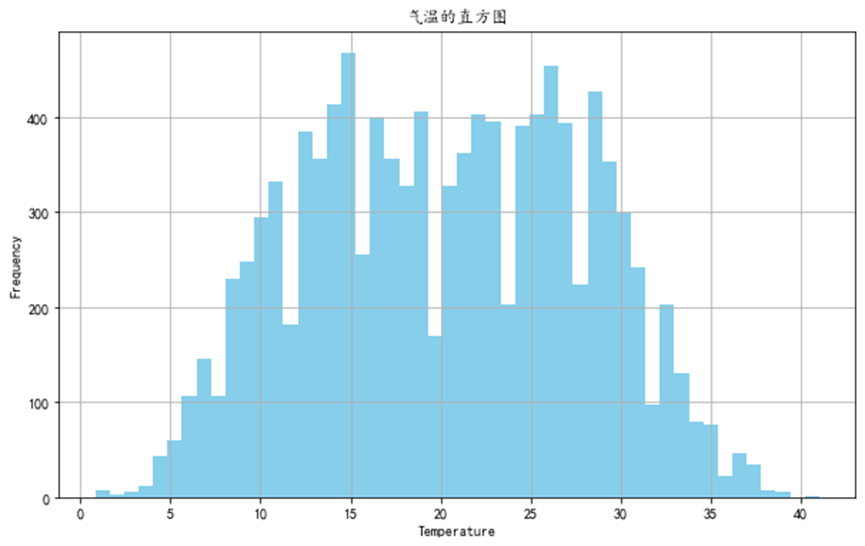
温度数据呈现一个接近正态分布的形态,两端较低,中间较高,形成一个钟形曲线。温度数据大致集中在0°C到40°C之间,这符合我们对自然环境温度的预期。...
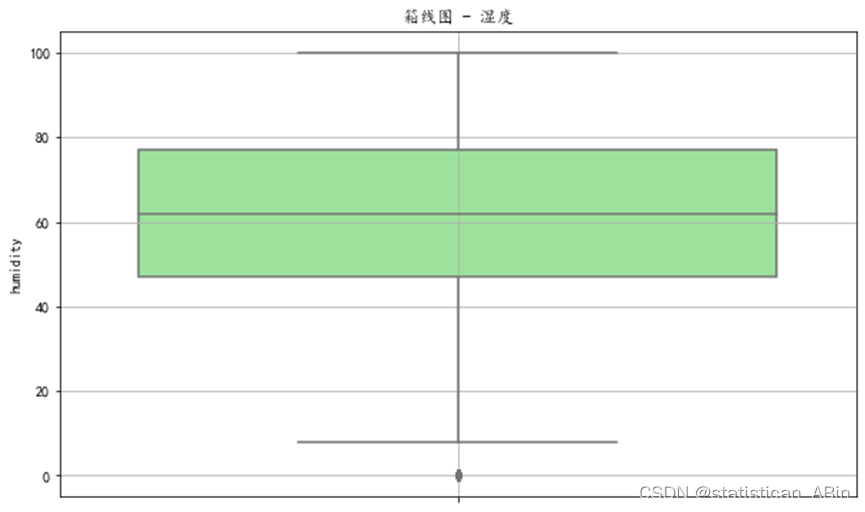
接下来查看湿度的箱线图
plt.figure(figsize=(10, 6))
sns.boxplot(y=data['humidity'], color='lightgreen')
plt.title('Boxplot of Humidity')
plt.grid(True)
plt.show()
 接下来注册与租赁次数的散点图
接下来注册与租赁次数的散点图
plt.figure(figsize=(10, 6))
plt.scatter(data['registered'], data['count'], alpha=0.5, color='coral')
plt.xlabel('registered')
plt.ylabel('Count')
plt.title('Scatter Plot of registered vs. Count')
plt.grid(True)
plt.show()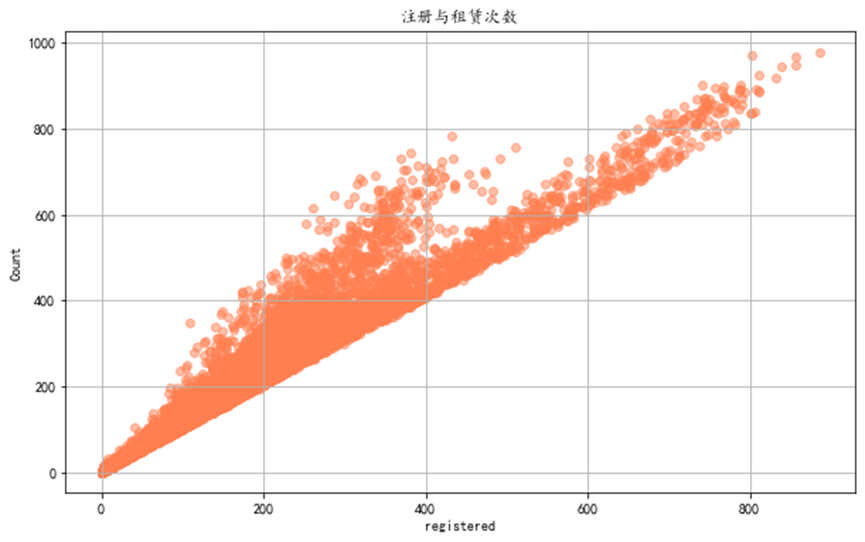
通过这个散点图发现, 图中的点大部分分布在从左下角到右上角的对角线上,表明这两个变量之间存在强烈的正相关关系。这意味着当一个变量的值增加时,另一个变量的值也倾向于增加。
接下来查看随时间变化的租赁次数的折线图
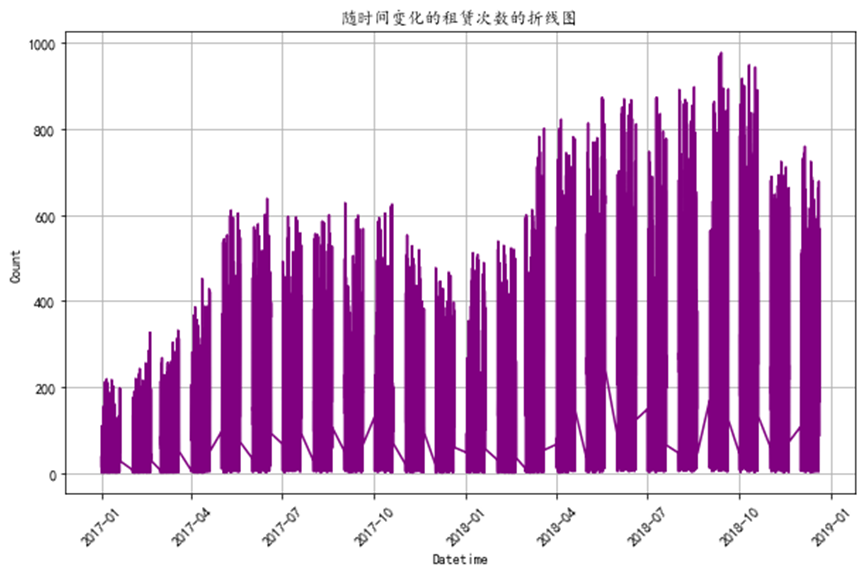
从图中可以看出,这是一个时间序列图,表示租赁次数随时间的变化趋势。图中显示出明显的周期性波动,每个周期的峰值和谷值反复出现。这种周期性波动可能对应于每日或每周的周期性变化。
接下来绘制相关矩阵热图
plt.figure(figsize=(12, 10))
correlation_matrix = data.corr()
sns.heatmap(correlation_matrix, annot=True, cmap=plt.cm.coolwarm)
plt.show()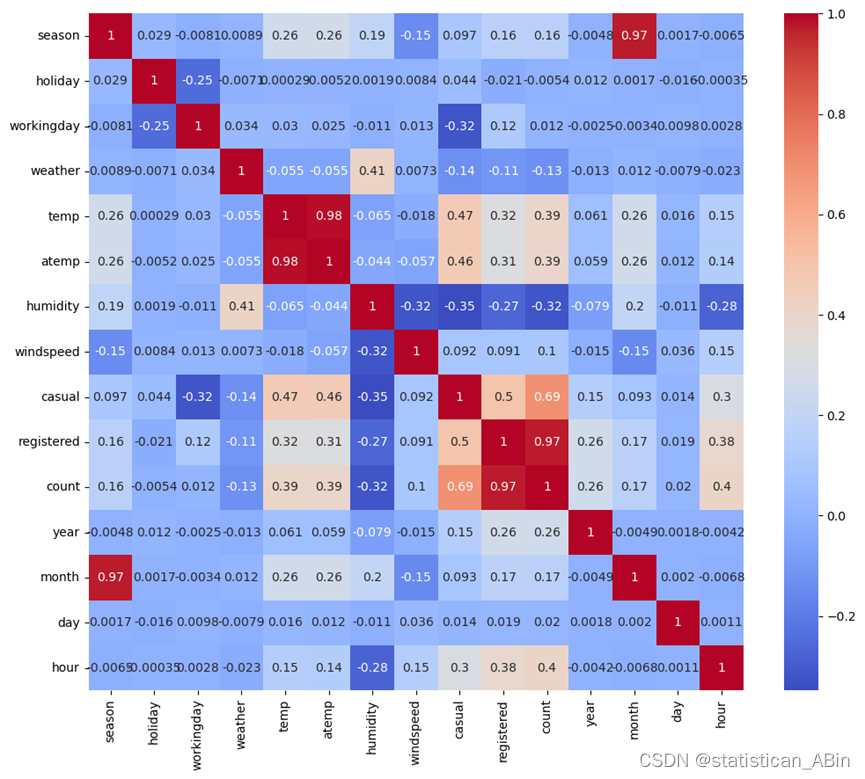
热图中颜色从蓝色(负相关)到红色(正相关),颜色越深表示相关性越强。registered 和 count:相关系数为0.97,表示注册用户的租赁次数与总租赁次数之间存在非常强的正相关关系。....
接下来进行支持向量机的模型建立,首先分割数据集,然后标准化数据,后面对模型进行评价,评价指标为:拟合优度、MSE、RMSE
# 创建支持向量机回归模型
svr_model = SVR()
svr_model.fit(X_train_scaled, y_train)
# 预测
y_train_pred = svr_model.predict(X_train_scaled)
y_test_pred = svr_model.predict(X_test_scaled)
# 计算拟合优度、MSE、RMSE
train_r2 = r2_score(y_train, y_train_pred)
test_r2 = r2_score(y_test, y_test_pred)
train_mse = mean_squared_error(y_train, y_train_pred)
test_mse = mean_squared_error(y_test, y_test_pred)
train_rmse = np.sqrt(train_mse)
test_rmse = np.sqrt(test_mse)

结果可视化一下
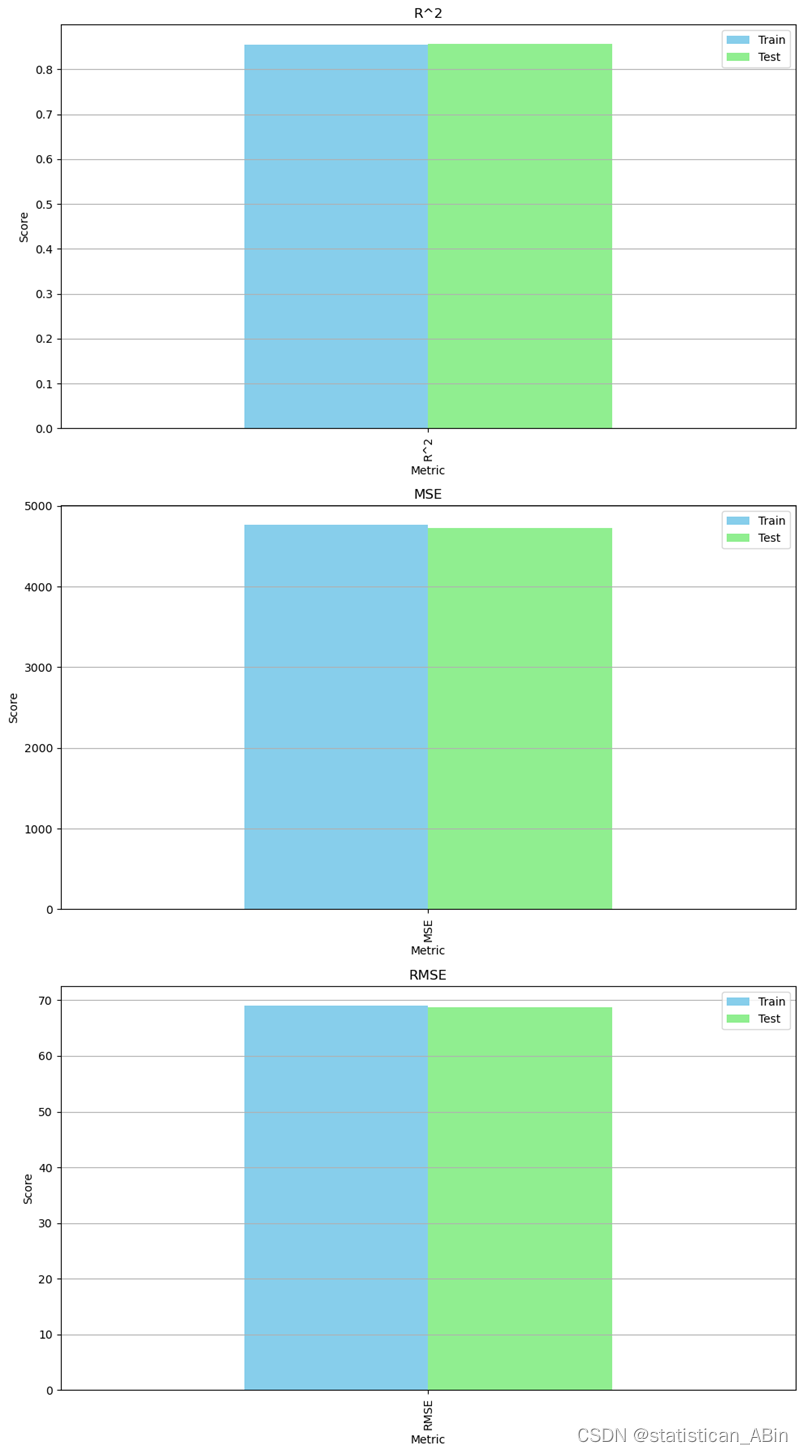
从图中可以看出,你对支持向量机(SVM)模型进行了评价,并使用柱状图展示了训练集和测试集上的R²、MSE和RMSE指标。R² (R-squared)训练集 R²:大约为0.85。测试集 R²:大约为0.86。这意味着模型能够解释大部分的目标变量的方差,具有较高的预测准确性。。。
可视化实际值与预测值
# 可视化实际值与预测值
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.scatter(y_train, y_train_pred, alpha=0.5)
plt.xlabel('Actual')
plt.ylabel('Predicted')
plt.title('Train Data')
plt.subplot(1, 2, 2)
plt.scatter(y_test, y_test_pred, alpha=0.5, color='red')
plt.xlabel('Actual')
plt.ylabel('Predicted')
plt.title('Test Data')
plt.tight_layout()
plt.show()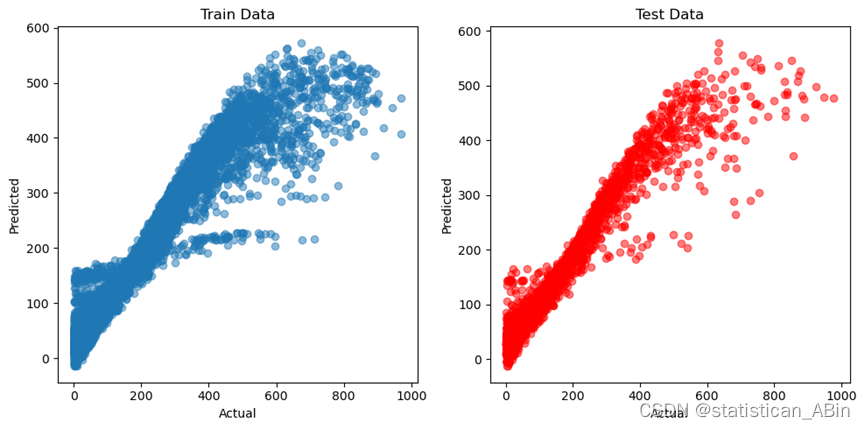
训练数据的散点图来看,模型能很好地拟合训练数据,大多数数据点集中在理想的对角线附近。从测试数据的散点图来看,模型在测试数据上的表现也较好,大多数数据点同样集中在对角线附近,表明模型具有良好的泛化能力。
四、结论
通过对共享单车租赁数据的分析和支持向量机模型的构建,我们得出以下结论:
1.温度对共享单车的租赁需求具有显著影响。在温暖的天气条件下,人们更倾向于使用共享单车,这可能是因为舒适的骑行体验。湿度:湿度也影响租赁需求,高湿度可能使骑行体验不佳,从而降低租赁次数。
2.租赁需求存在明显的时间模式。例如,在工作日的上下班高峰期和周末的休闲时段,租赁次数会显著增。。。
创作不易,希望大家多点赞关注评论!!!(类似代码或报告定制可以私信)















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









