






在使用rag对原本的通用模型进行改造后,我们发现整合后,模型的效果并不是很好。
下面介绍我们分析的原因和进行的两点改进。
一、改进rag中检索和返回的内容
我们的数据集是对话(问答)形式的数据集,即每条数据分为问题和回答两部分,在对原始数据集进行切割时也保持这样的结构,切割后的每条文本数据结构为“问题+一到多条回答的拼接”。
参考一些rag策略,发现在很多问答rag的策略中,对每条数据整体做嵌入和索引建立,但返回给模型的是top-k文本中的回答(即不返回问题)。认为该策略具有一定合理性,一是因为使用的大语言模型有token限制,删掉问题,减少语言模型的分析压力;二是检索到的问题可能与query并不完全一致,返回整个问答对可能会对模型产生误导,降低结果的准确性。
为了实现不返回文本中的问题的功能,遍历原始数据集,重新进行一遍数据切割,在切割的同时统计每个文本
下面展示的是切割部分的关键代码,可以看到每条切割文本生成后,都会将生成文本的问题长度保存到mask数组中。
answers_info = item['answers_info']
i=0
while i<len(answers_info):#进行一个问题和多个回答的拼接
answerForOne=''
combination=question
count=0#记录一个当前chunk中存储了多少个answer
while i<len(answers_info):
answer=answers_info[i]
answer_content = answer['content'].replace('\r', '').replace('\n', '')
...#一些对长度的逻辑判断
combination+=answerForOne
mask.append(len(question))
combinationList.append(combination)
完成所有原始文本的切割后,将所有mask写入文本文件,每行对应一条切割问答对的问题长度。
在检索后,因为检索索引中的向量索引与mask的索引一致,可以直接用检索到的top-k下标到mask中读取问题长度,对rag_answer,只拼接每个切割问答对的问题部分。
I = I[0]
for index in I:
bef = mask[index]
rag_answer += text_documents[index][bef:] + '\n'二、加上微调技术
1.背景
使用rag增强后的psyLLM作为我们网站的使用的模型,在进行网站使用测试时发现,由于知识库中数据的限制,rag有时无法发挥很好的性能,甚至会误导原本LLM的回答。
分析原因,认为是我们使用的数据集具有局限性:我们的数据集多集中于情感问题,对于生活中的其他问题,知识库中可能不存在与query相关的文本,但检索算法一定会返回最近的k个向量的下标(即使它们与query向量的相似度很低)。
我们可以选择对返回的top-k的相似度进行约束,search方法返回两个元素,I是top-k向量的下标,D是top-k向量与query向量的距离。可以判断每个距离是否超过阈值,舍弃与query向量距离较大的向量,不将其对应的原始文本拼接到rag_answer中。但这样就与我们使用rag的目的不完全一致了。
D, I = loaded_index.search(xq, k) # actual search
count=0
for distance in D:
if distance>threshold:
break
count+=1考虑使用微调技术:微调后query与用于训练的数据是否相关的问题就交给了模型来判断,将知识库直接嵌入到模型的参数中,比rag更为直接。
2.环境配置
仍然选择我们之前使用的chatGLM进行部署和微调。因为微调需要较大的显存(>=24G),因此租用一张4090的显卡进行训练。此外,运行实例要求python>=3.10
选择占用显存最少的微调方式——LORA 微调: 1张显卡,占用 14082MiB 显存。
1.安装chatGLM3
下载模型到本地
git clone https://github.com/THUDM/ChatGLM3.git进入模型目录,安装模型
pip install -r requirements.txt
pip install nltk
pip install datasets
pip install jieba
pip install rouge_chinese
如果直接整个安装requirements.txt无法成功,可以删除requirements.txt中报错的包,先把能安装的部分安装掉。之后解决无法安装的包的问题。
当时我无法一次性安装mpi4py包,参考了以下博客:
2.从魔搭社区下载模型
因为chatGLM是国内团队开发,所以魔搭社区上也提供了模型参数的下载,相比huggingface,下载速度更快一些,成功率也更高。
直接在ChatGLM3/chatglm3-6b文件夹下clone包即可,如果服务器上下载不稳定,可以先下载到本地,再从本地上传到服务器。
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git当时在配置环境时,先在hugging-face上下载模型,完成后发现所有的文件都是齐全的,但一直报错。最后在网上检索bug的过程中发现一篇博客中提到,由于网络问题可能会发生chatglm3-6b下应有的文件名齐全,但每个文件没有下完整的情况。
使用ls -l打印文件夹下的文件大小后发现本来应该有10G+的文件只有240K,没能在hugging-face上下全。改用在魔搭社区中下载,修改basic_demo/cli_demo.py中的模型路径为本地路径,之后运行demo命令,成功跑通本地部署的chatGLM3。
python basic_demo/cli_demo.py 这里贴一张当时成功跑通demo的图片
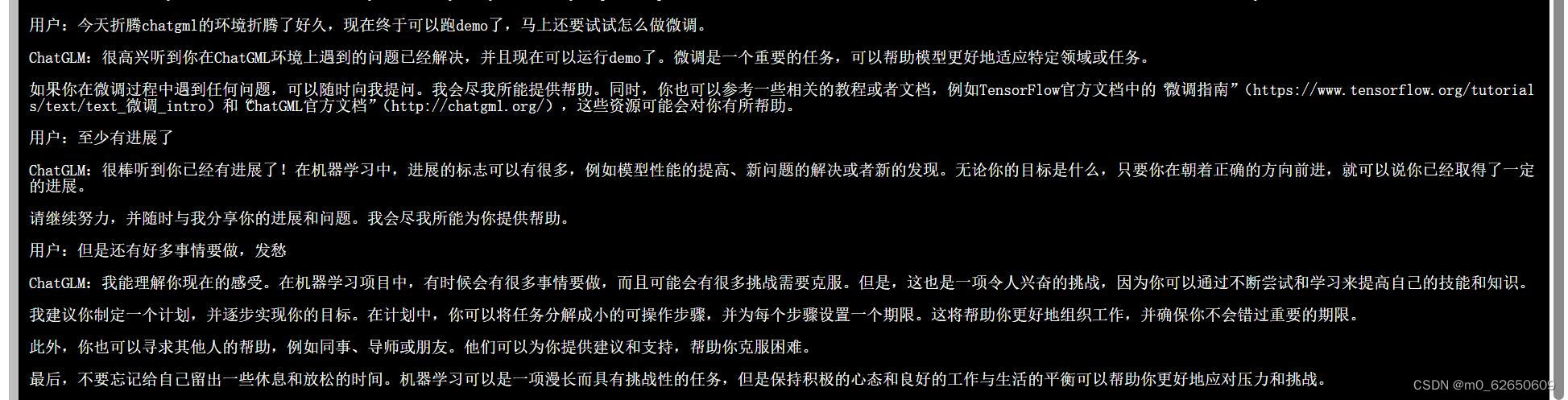
可以看出在中文情景下chatglm3-6b还是非常自然通顺的。
3.数据处理
当时找到了两个数据集,使用另一个数据集用来做微调,另一个数据集同样是问答形式的数据集。
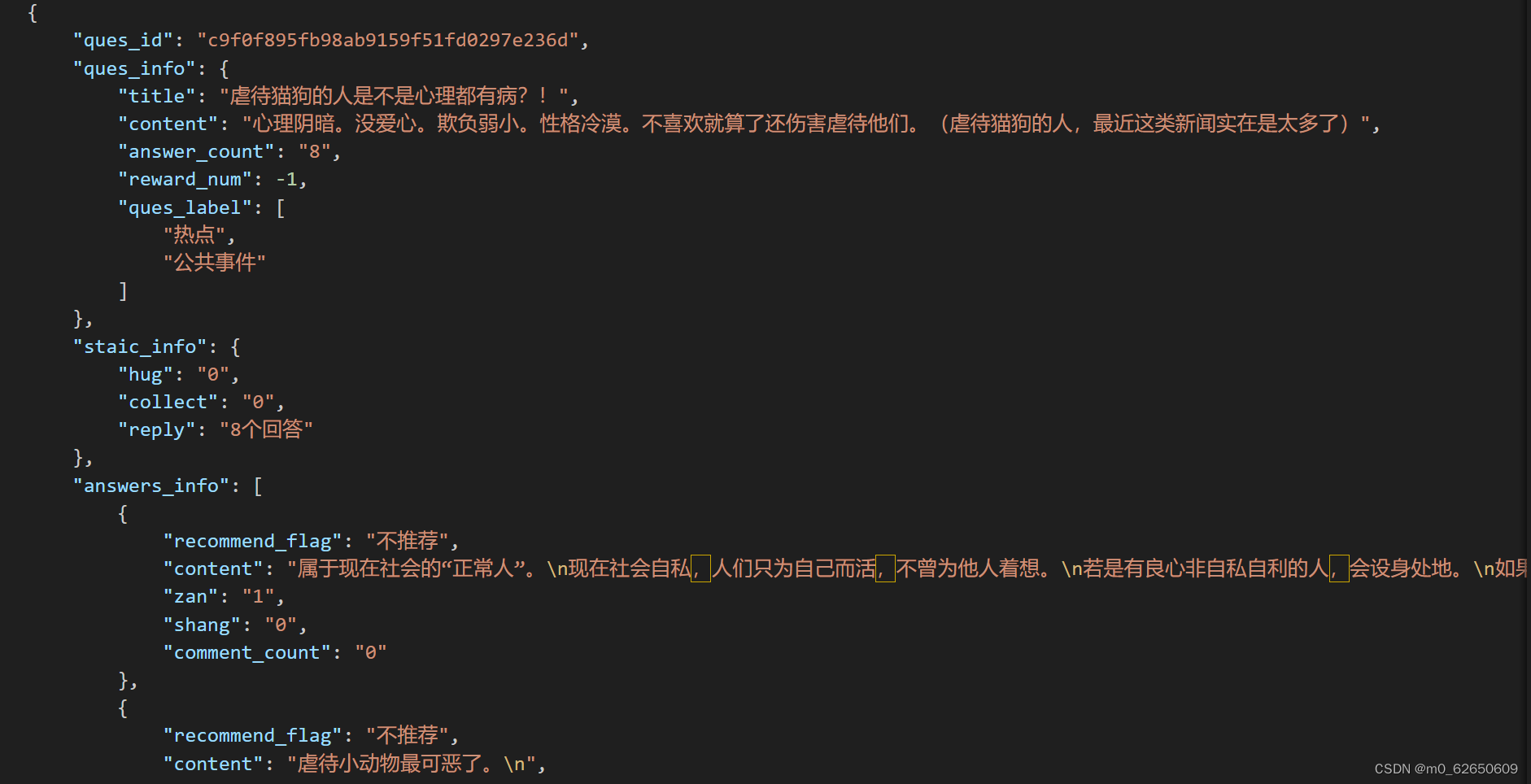
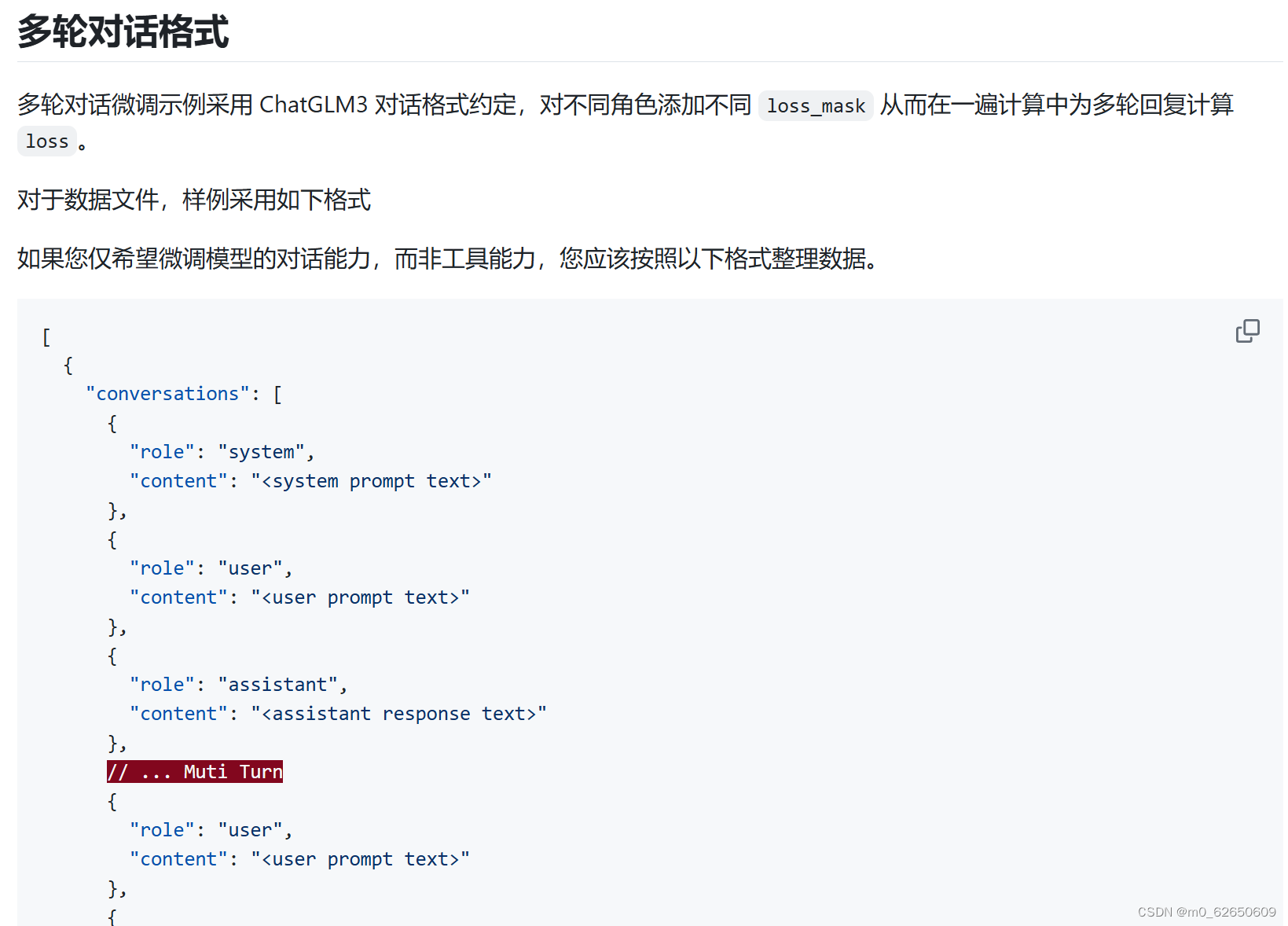
ChatGLM3的github官网上给出了不同应用场景下的微调数据的格式,选择我们网站需要的对话格式的数据,根据以下格式对数据集进行整合。
对数据集中的问题和回答进行拼接和切分,同时记录最长问题和最长回答的大小,用作后面的微调配置参数,之后将每个问答对组合成不同角色回答内容的格式。
for i in range(len(questions)):
new_data = {
"conversations": [
{
"role": "user",
"content": questions[i]
},
{
"role": "assistant",
"content": answers[i]
}
]
}由于微调的需求,将调整格式后的数据集划分成训练集、验证集和测试集,之后分别写入json文件。
if count%10==0:
val_data.append(new_data)
elif count%85==0:
test_data.append(new_data)
else:
train_data.append(new_data)
count+=1
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(train_data, f, ensure_ascii=False, indent=4)
...调整后的数据样式如下:

将三个数据集放在服务器上的同一个文件夹下。
4.配置文件
修改ChatGLM文件夹下的lora.yaml文件(我们使用lora微调方式),修改max_input/output_length为上面我们统计的数值,修改各个数据集的文件路径,指定output_dir,max_steps和save_steps等参数。
对于微调来说,max_steps>50才有效果。
lora.yaml / ptuning.yaml / sft.yaml: 模型不同方式的配置文件,包括模型参数、优化器参数、训练参数等。 部分重要参数解释如下:
- data_config 部分
- train_file: 训练数据集的文件路径。
- val_file: 验证数据集的文件路径。
- test_file: 测试数据集的文件路径。
- num_proc: 在加载数据时使用的进程数量。
- max_input_length: 输入序列的最大长度。
- max_output_length: 输出序列的最大长度。
- training_args 部分
- output_dir: 用于保存模型和其他输出的目录。
- max_steps: 训练的最大步数。
- per_device_train_batch_size: 每个设备(如 GPU)的训练批次大小。
- dataloader_num_workers: 加载数据时使用的工作线程数量。
- remove_unused_columns: 是否移除数据中未使用的列。
- save_strategy: 模型保存策略(例如,每隔多少步保存一次)。
- save_steps: 每隔多少步保存一次模型。
- log_level: 日志级别(如 info)。
- logging_strategy: 日志记录策略。
- logging_steps: 每隔多少步记录一次日志。
- per_device_eval_batch_size: 每个设备的评估批次大小。
- evaluation_strategy: 评估策略(例如,每隔多少步进行一次评估)。
- eval_steps: 每隔多少步进行一次评估。
- predict_with_generate: 是否使用生成模式进行预测。
- generation_config 部分
- max_new_tokens: 生成的最大新 token 数量。
- peft_config 部分
- peft_type: 使用的参数有效调整类型(如 LORA)。
- task_type: 任务类型,这里是因果语言模型(CAUSAL_LM)。
- Lora 参数:
- r: LoRA 的秩。
- lora_alpha: LoRA 的缩放因子。
- lora_dropout: 在 LoRA 层使用的 dropout 概率
- P-TuningV2 参数:
- num_virtual_tokens: 虚拟 token 的数量。
运行下面的命令进行微调(单机单卡模式)
finetune_hf.py 数据集文件夹路径 本地模型路径 configs/lora.yaml结束后会在output_dir下生成检查点文件,使用最后一个生成的即可。
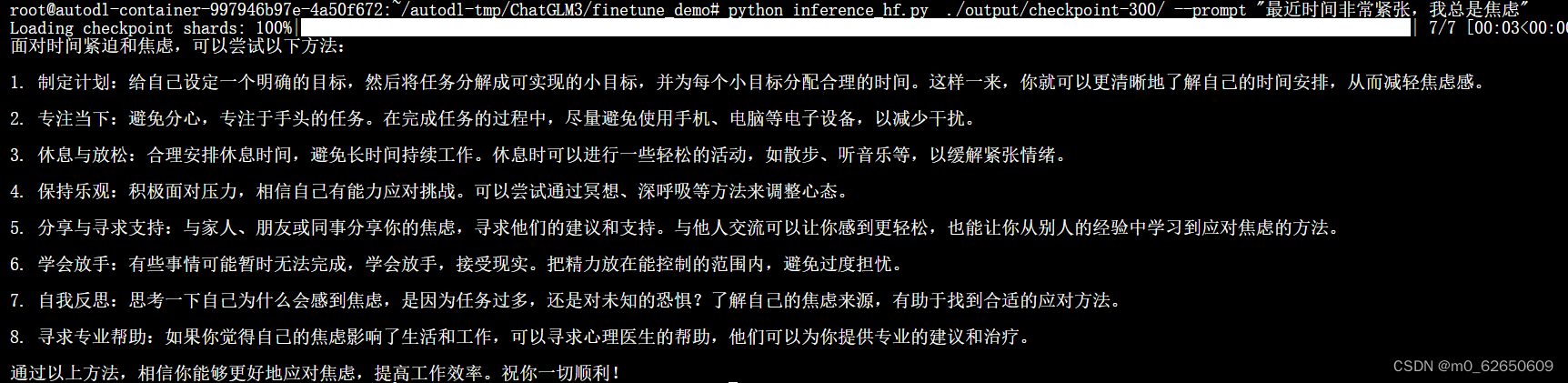
5.微调效果展示
运行
python inference_hf.py 微调后生成的检查点文件路径 --prompt your prompt即可使用微调后的模型。
简单的效果展示如下:















 751
751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









