







 本文提出了一种名为STPM的深度学习算法,用于预测公交到站时间,结合了卷积神经网络(CNN)和循环神经网络(LSTM),以捕捉时空依赖性和外部影响。STPM通过时空组件、属性组件和融合组件,有效地预测了公交从起点到终点的总行驶时长,实验结果表明其优于传统方法。
本文提出了一种名为STPM的深度学习算法,用于预测公交到站时间,结合了卷积神经网络(CNN)和循环神经网络(LSTM),以捕捉时空依赖性和外部影响。STPM通过时空组件、属性组件和融合组件,有效地预测了公交从起点到终点的总行驶时长,实验结果表明其优于传统方法。
基于时空相关属性模型的公交到站时间预测算法

来源:《软件学报》 ,作者赖永炫等
摘 要:公交车辆到站时间的预测是公交调度辅助决策系统的重要依据,可帮助调度员及时发现晚点车辆,并做出合理的调度决策.然而,公交到站时间受交通拥堵、天气、站点停留和站间行驶时长不固定等因素的影响,是一个时空依赖环境下的预测问题,颇具挑战性.提出一种基于深度神经网络的公交到站时间预测算法STPM,算法采用时空组件、属性组件和融合组件预测公交车辆从起点站到终点站的总时长.其中,利用时空组件学习事物的时间依赖性与空间相关性.利用属性组件学习事物外部因素的影响.利用融合组件融合时空组件与属性组件的输出,预测最终结果.实验结果表明,STPM 能够很好地结合卷积神经网络与循环神经网络模型的优势,学习关键的时间特征与空间特征,在公交到站时间预测的误差百分比和准确率上的表现均优于已有的预测方法.
关键词:到站预测;梯度提升树;卷积长短期记忆网络
随着我国城市的发展,私家车数量急剧增加,道路拥堵、车辆尾气排放造成环境污染等问题日益加剧[1].相比于私家车,公共交通工具具有承载量大、能源消耗较低、尾气排放相对较小等优势,对于缓解上述问题具有重要意义[2].相对于出租车等公共交通方式,公交具有投资成本更低、承载量更大,且覆盖范围更广等优势,成为城市出行的重要方式,提升其营运效率,是提升乘客满意度、吸引乘客使用该方式出行的必要手段[3,4].
目前,我国公交采取排班制发车,以达到公交公司和乘客之间的效益平衡.但由于道路交通、天气等因素复杂多变,导致车辆常常不能按照计划发车时间发班,进而会出现“串车”和“大间隔”现象[5].为应对各种原因导致车辆不能按原计划发班的情况,需要进行车辆的实时调度.现有的公交调度方式主要由手工完成,即公交调度员通过监视面板观察所负责线路的当前车辆分布状况.调度员根据自身经验估计车辆回场时间,进而进行下一班次发车时间的调整.现有调度方式仅依靠调度员的经验估计车辆到站时间,不仅工作量巨大,且常由于错误预估,导致调度策略无法被准确执行,仍无法缓解“串车”和“大间隔”现象的发生.图1 给出了厦门市11 路和22 路公交线路3 个月运行总时长的统计图(箱线图中线表示均值,其他线表示四分位点,圆圈表示异常点).从图中可以看出:同一线路方向,即使在同一时间段内的总行驶时长依然存在较大差异和异常点.因此,良好运行的调度系统迫切需要一个能相对准确地预测到站时间的算法,进而辅助调度员合理地预估车辆回场时间.这也是近年来智能交通(intelligent transportation system,简称ITS)[6−8]应用的典型场景.
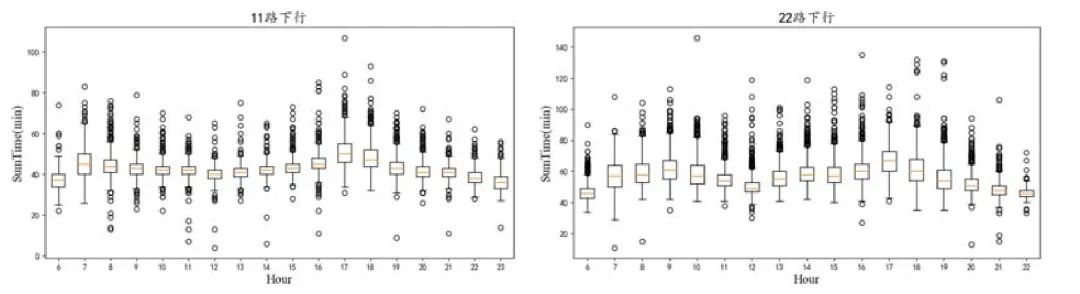
Fig.1 Distribution of bus travel time of route No.11 and 22 in Xiamen city
图1 厦门市11 路和22 路公交行驶总时长分布图
公交车辆到站时间预测受站点停留和站间行驶时长等相关因素的影响,存在时空依赖性.从时间的角度看,无论是站点停留还是站间行驶,都具有一定的时间规律,这种规律可能是长期的历史规律、短期的周期规律或者近期的波动规律等.从空间的角度看,站点停留和站间行驶具有一定的空间规律.例如:对于站点停留来说,某一站用于乘客上车的停留时间必然影响另一站用于乘客下车的停留时间.对于站间行驶而言,相邻路段的行驶速度也相互影响.此外,天气状况、道路交通状况等难以准确预知,增加了预测的挑战性[9].已有的预测行程时长的方式包括两种,即分段预测[9,10]与全程预测[11,12].分段预测是指对路段进行划分预测,对预测时间加以累加.这种方式可能产生的问题是误差累积,使得最终预测误差变大.全程预测是指直接预测从起点到达终点的时间的方式.这种方式可能产生的问题是当路径越长时,覆盖完整路径的轨迹点就越少,数据越稀疏导致结果往往不准确.由于公交通常具有“定线路”、“定站点”的特点,发车频率较快,同一时段有多辆同线路公交在运行,因此公交车辆本身即可收集各种交通数据,为即将发班的车辆预测提供依据.
近年来,深度学习技术在视觉、自然语言处理等领域得到了广泛应用.其中,卷积神经网络模型[13]已被证明可很好地捕捉空间规律,而循环神经网络[14]类似于一个存在记忆功能的神经网络,能够捕捉事物的时间规律.本文基于二者的融合,提出一种基于ConvLSTM[15]模型,能够同时捕捉事物时间依赖性、空间相关性与外部影响因素的公交车到站时间预测算法——时空属性模型(spatio-temporal property model,简称STPM).
本文的主要贡献包括:提出一种能够同时学习事物时空依赖性和外部因素影响的卷积时空属性模型,该算法通过时空组件捕获事物的时间依赖性和空间相关性,利用该组件分别学习与预测站点停留与站间行驶参数.通过属性组件,将外部因素如天气、时间、驾驶员、车辆、近期路段行驶状况等因素的复杂性融合到模型预测结果的考量中去.提出一种融合组件,将事物的时空特征与外部因素特征进行融合,预测公交车辆从起点到终点的总行驶时长.该算法可作为调度辅助决策系统的依据,帮助调度员及时发现晚点车辆,并作出合理的调度决策.在真实数据集上实现了该算法并进行了验证.实验结果表明:SPTM 算法能够更好地学习事物的时空特性,相对于单一使用卷积神经网络或循环神经网络而言,其预测准确率能提高至少2.25 个百分点;且可以充分利用外部属性的因素,提高预测的准确率.
据我们所知,本文是首个利用深度学习算法进行公交车从起点到终点总时长预测的研究.第1 节介绍国内外关于行程时长预测的研究.第2 节介绍数据预处理过程.第3 节对STPM 算法进行详细展开和叙述.第4 节利用真实公交到离站数据进行实验验证与分析.第5 节总结全文并对未来工作进行展望.
1 相关工作
现有的关于行驶时长预测的方法主要可以分成基于传统方法和基于深度学习的方法.传统方法包括回归模型和卡尔曼滤波模型,利用历史数据和时间序列数据进行预测.Wu 等人[9]利用支持向量回归(support vector regression,简称SVR)进行交通时长的预测.在该文献的研究中,通过使用过去t 个时刻的真实交通时长数据,预测未来一段时间内的交通行驶时长.通过实验证明,该方法在预测旅行时间问题上具有一定可行性.但其在特征使用上,仅使用了过去时刻的数据,无法体现外在因素如驾驶员风格、车辆性能、道路交通状况的差异对预测结果的影响.Vanajakshi 等人[16]利用卡尔曼滤波技术预测不同交通条件下的出行时间.在该文献的研究中,对路段进行等距离划分,利用2 辆前序车辆收集到的信息进行当前车辆的预测.在该方法中,假设任何时刻均有两辆前序车辆跑完全程为其收集信息,在实际应用中较难实现.Mathieu 等人[17]提出了一种用于预测到站时间的基于实时GPS 数据的非参数算法,关键思想是,使用内核回归模型来表示位置更新与公交车站到达时间之间的依赖关系.实验结果表明:对于50 分钟的时间范围,算法的预测误差平均小于10%.在该文献的研究方法中,通过依据历史数据与当前状况的相似性为其赋予不同的权重,计算当前状况的预测值.这种方式对于模型训练的时间跨度要求较为严格,需要更长时间的数据样本.
近年来,深度神经网络
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2072
2072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









