






一般我们会觉得网络越深,特征信息越丰富,模型效果应该越好。但是实验证明,当网络堆叠到一定深度时,会出现两个问题:
梯度消失或梯度爆炸
关于梯度消失和梯度爆炸,其实看名字理解最好:
若每一层的误差梯度小于1,反向传播时,网络越深,梯度越趋近于0
反之,若每一层的误差梯度大于1,反向传播时,网路越深,梯度越来越大
退化问题(degradation problem):在解决了梯度消失、爆炸问题后,仍然存在深层网络的效果可能比浅层网络差的现象
总结就是,当网络堆叠到一定深度时,反而会出现深层网络比浅层网络效果差的情况。
在ResNet网络的创新点:
- 提出 Residual 结构(残差结构),并搭建超深的网络结构(可突破1000层)
- 使用 Batch Normalization 加速训练(丢弃dropout)

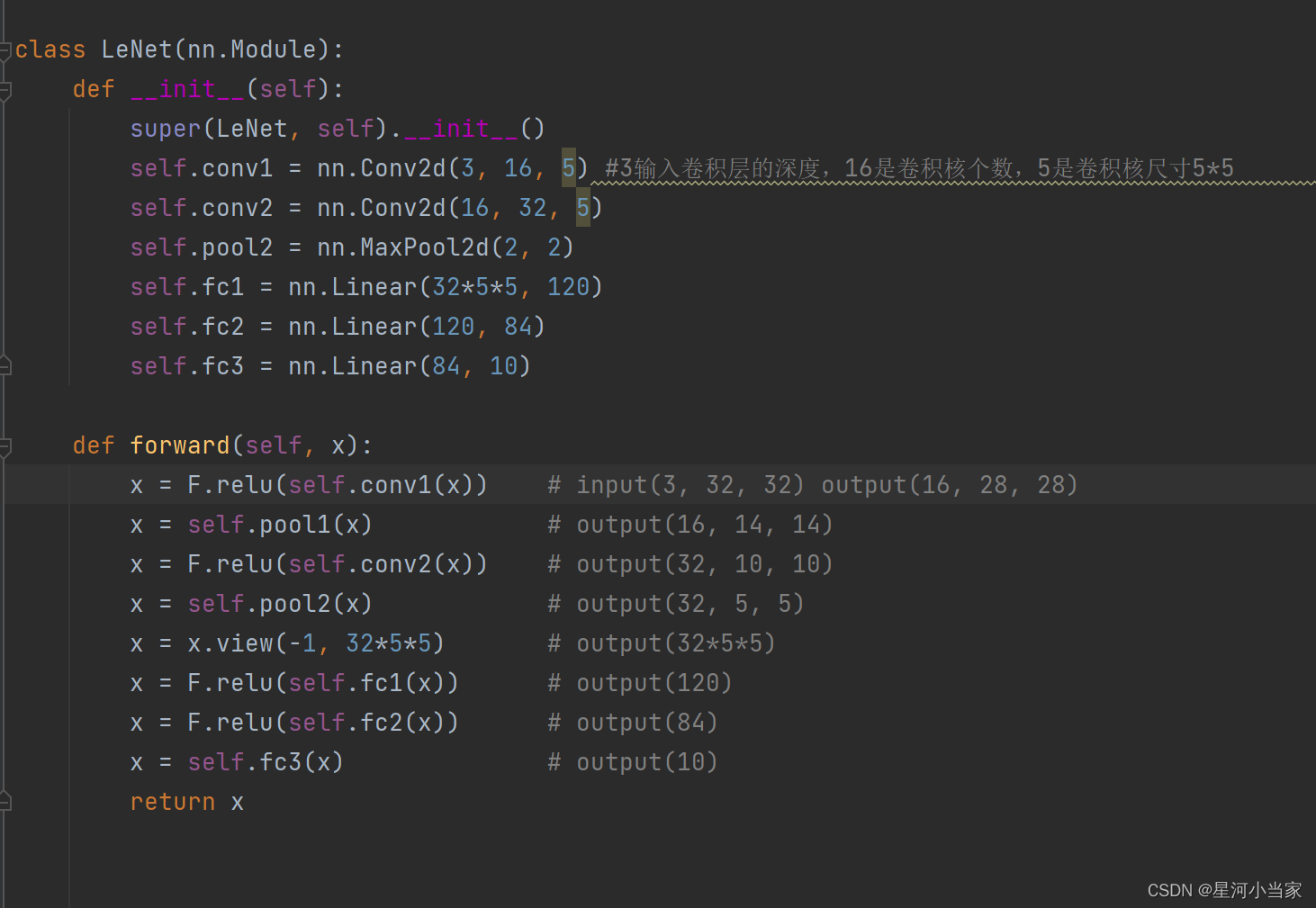
conv2d这个函数的参数第一个是卷积层深度,输入图片是RGB3色的,32*32大小,所以是深度是3,16是卷积核的个数,尺寸为5*5,卷积后的矩阵尺寸大小为(32-5+2*0)/1(步长默认为1)+1=28
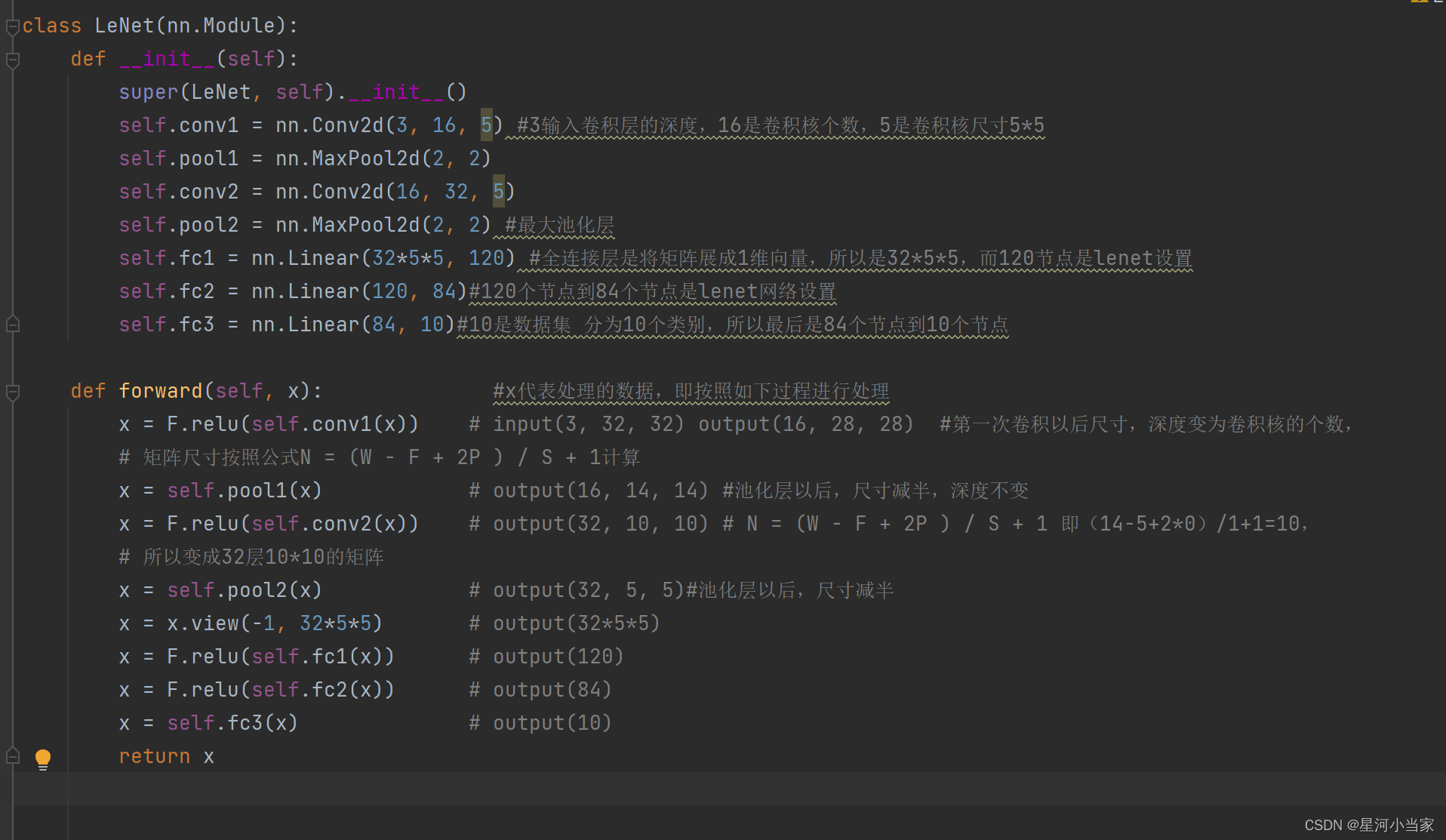
每一步的一个注释
stride作用为2时可以将特征矩阵的高和宽缩减为一半,所以一般maxpool以后深度不变宽高变成了一半,
而1*1的卷积核可以生维度和降维度
跟VggNet类似,ResNet也有多个不同层的版本,而残差结构也有两种对应浅层和深层网络:
ResNet 残差结构
浅层网络 ResNet18/34 BasicBlock
深层网络 ResNet50/101/152 Bottleneck
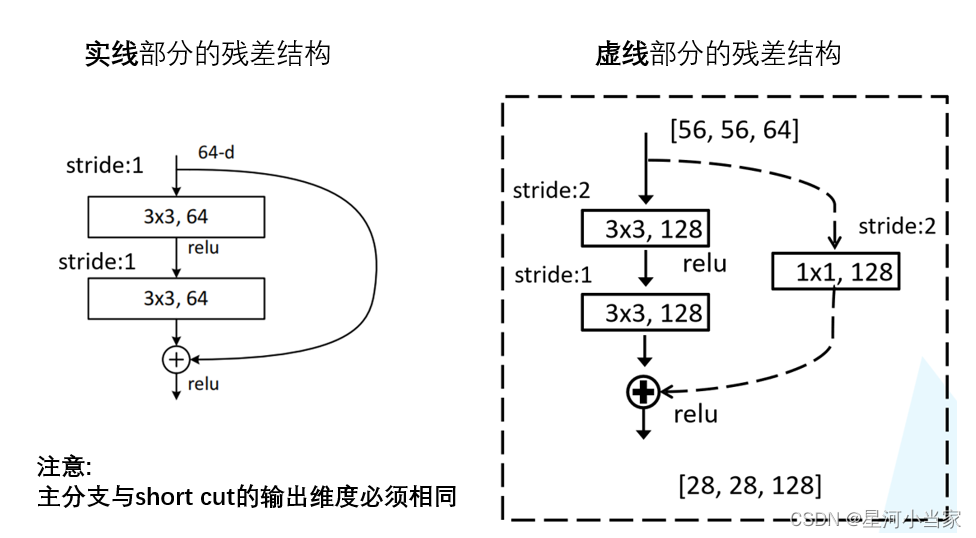
下图中左侧残差结构称为 BasicBlock,右侧残差结构称为 Bottleneck
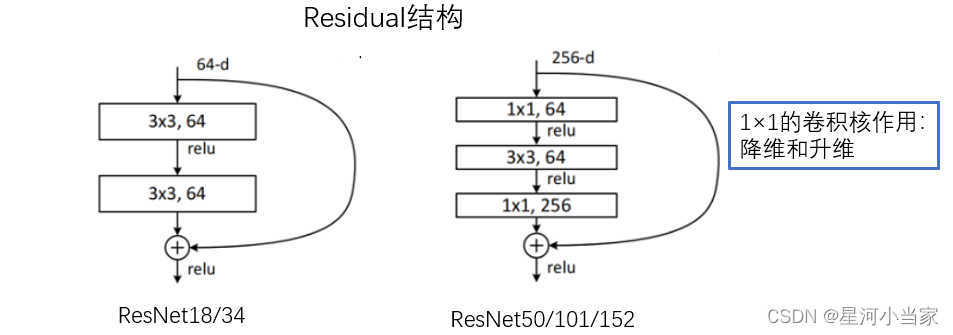
对于深层的 Bottleneck,1×1的卷积核起到降维和升维(特征矩阵深度)的作用,同时可以大大减少网络参数。
1.4 降维时的 short cut
观察下图的 ResNet18层网络,可以发现有些残差块的 short cut 是实线的,而有些则是虚线的。
这些虚线的 short cut 上通过1×1的卷积核进行了维度处理(特征矩阵在长宽方向降采样,深度方向调整成下一层残差结构所需要的channel即升维)。
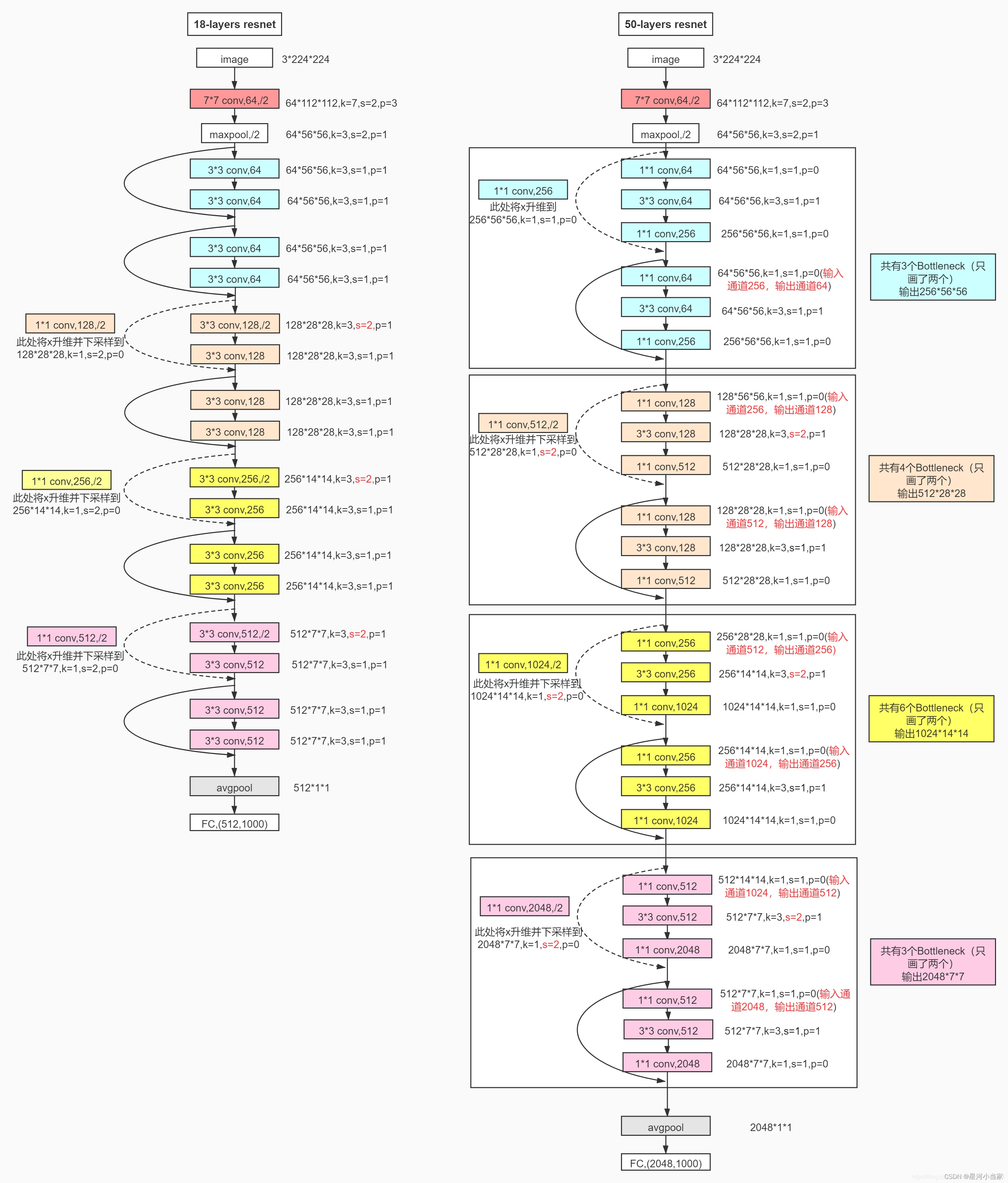
我用到的主要是resnet18,

下面是 ResNet 18/34 和 ResNet 50/101/152 具体的实线/虚线残差结构图:
-
ResNet 18
-
YOLOv5和YOLOv8都是优秀的目标检测模型,在人脸表情识别任务上都可以使用,主要区别如下:
- 架构设计不同 YOLOv5基于YOLOv3和YOLOv4改进而来,使用了一定的注意力机制。YOLOv8则在YOLOv5的基础上,引入了Transformer作为backbone,进一步增强了模型的表示能力。
- 精度提升 在同等计算资源下,YOLOv8的精度明显优于YOLOv5,特别是在小目标检测上有显著提升。
- 速度表现 YOLOv5的检测速度会更快一些,YOLOv8因引入了Transformer,速度略慢于YOLOv5。
- 训练时间 YOLOv8的训练时间更长,收敛较慢。
综合来看,YOLOv8的定位和识别精度会优于YOLOv5,更适合对精度要求较高的场景,如人脸表情识别。但其训练和预测速度稍慢。如果对检测速度要求较高,则建议使用YOLOv5。
所以在人脸表情识别任务上,如果追求高精度,建议先用YOLOv8检测出人脸,然后传入表情分类模型。如果需要实时处理,则可考虑使用YOLOv5加快检测速度。
因为需要实时表情处理,所以选择了YOLOv5,

















 2803
2803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









