






深度学习使用VOVNET时候考虑了特征重用,在看源码时候很不解,不是concat吗,为什么还有1x1卷积和最大池化。在加入CSPNET时候使用效果也不好,因此看源码,发现使用OSA模块时候他的最大池化层下采样不可以在CSPNET中的bottleneck使用,会降低分辨率,发现有一个1X1CONV被我忽略了。鉴于此,写下来记忆一下。
VOVNET结构图
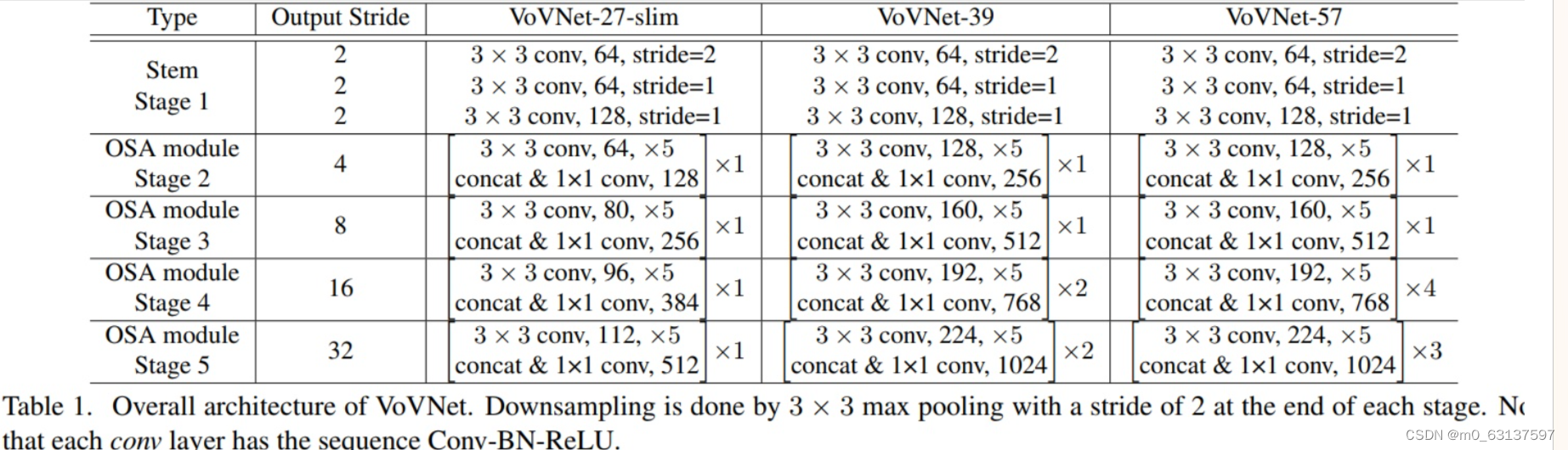
OSA模块源码
class _OSA_module(nn.Module):
def __init__(self,
in_ch,
stage_ch,
concat_ch,
layer_per_block,
module_name,
identity=False):
super(_OSA_module, self).__init__()
self.identity = identity # 默认不使用恒等映射
self.layers = nn.ModuleList()
in_channel = in_ch
# stage_ch: 每个 stage 内部的 channel 数
for i in range(layer_per_block):
self.layers.append(nn.Sequential(
OrderedDict(conv3x3(in_channel, stage_ch, module_name, i))))
in_channel = stage_ch
# feature aggregation
in_channel = in_ch + layer_per_block * stage_ch
# concat_ch: 1×1 卷积输出的 channel 数
# 也从 stage2 开始,每个 stage 最开始的输入 channnel 数
self.concat = nn.Sequential(
OrderedDict(conv1x1(in_channel, concat_ch, module_name, 'concat')))
def forward(self, x):
identity_feat = x
output = []
output.append(x)
for layer in self.layers: # 中间所有层的顺序连接
x = layer(x)
output.append(x)
# 最后一层的输出要和前面所有层的 feature map 做 concat
x = torch.cat(output, dim=1)
xt = self.concat(x)
if self.identity:
xt = xt + identity_feat
return xt














 875
875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









