







 本文介绍YOLOv10的原创改进,特别是自研MSAM(多尺度通道注意力模块),该模块提升了CBAM的性能,适用于目标检测、分割等任务。通过MSAM的加入,模型在多个数据集上实现性能增益,适用于红外、小目标检测等场景。作者提供魔改代码和结构图,帮助读者理解和应用这些创新点。
本文介绍YOLOv10的原创改进,特别是自研MSAM(多尺度通道注意力模块),该模块提升了CBAM的性能,适用于目标检测、分割等任务。通过MSAM的加入,模型在多个数据集上实现性能增益,适用于红外、小目标检测等场景。作者提供魔改代码和结构图,帮助读者理解和应用这些创新点。
💡💡💡本文自研创新改进:MSAM(CBAM升级版):通道注意力具备多尺度性能,多分支深度卷积更好的提取多尺度特征,最后高效结合空间注意力

1)作为注意力MSAM使用;
推荐指数:五星
MSCA | 亲测在多个数据集能够实现涨点,对标CBAM。
改进1结构图:
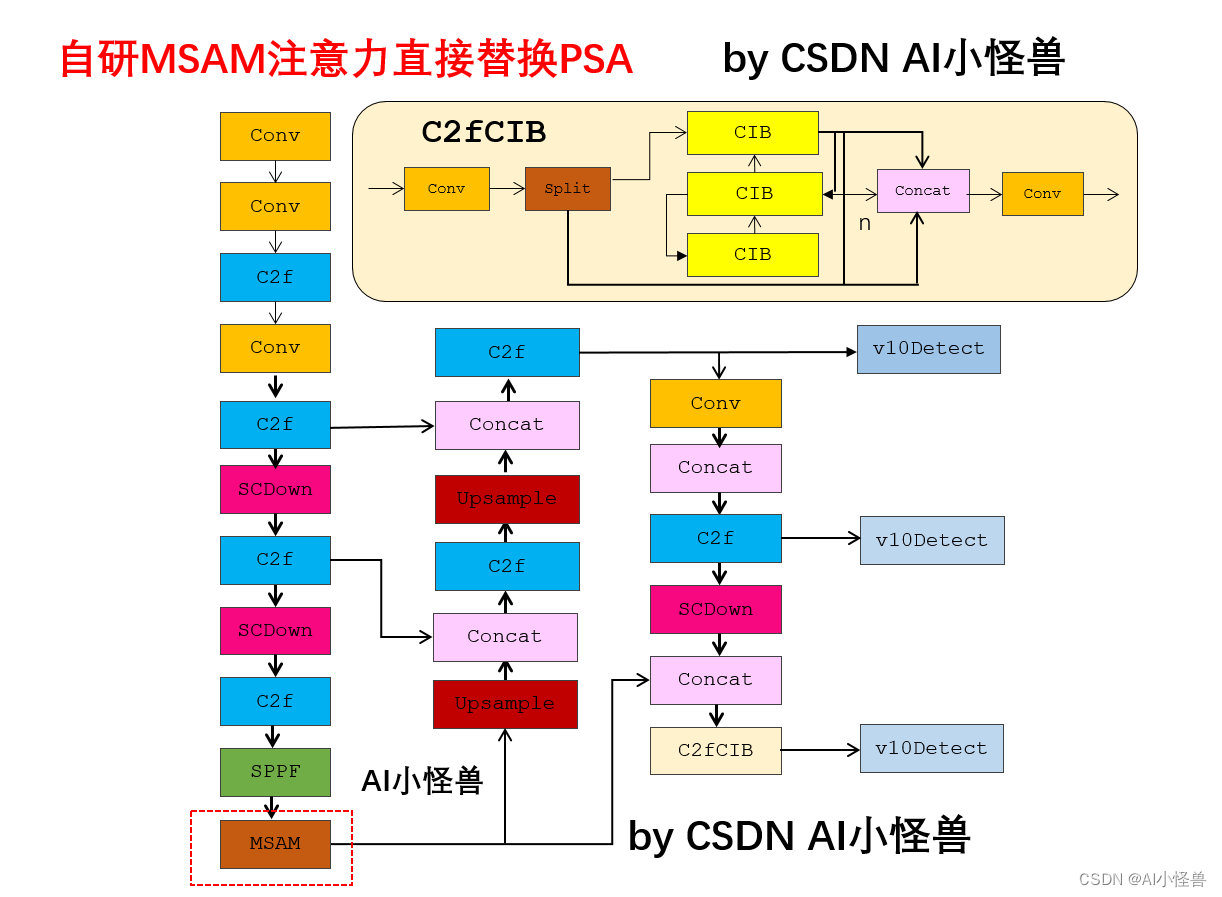
改进2结构图:
💡💡💡本文自研创新改进:MSAM(CBAM升级版):通道注意力具备多尺度性能,多分支深度卷积更好的提取多尺度特征,最后高效结合空间注意力
1)作为注意力MSAM使用;
推荐指数:五星
MSCA | 亲测在多个数据集能够实现涨点,对标CBAM。
改进1结构图:
改进2结构图:
 352
1129
1517
352
1129
1517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文

























