







导读:大型预训练模型是一种在大规模语料库上预先训练的深度学习模型,它们可以通过在大量无标注数据上进行训练来学习通用语言表示,并在各种下游任务中进行微调和迁移。随着模型参数规模的扩大,微调和推理阶段的资源消耗也在增加。针对这一挑战,可以通过优化模型结构和训练策略来降低资源消耗。
一般来说,研究者的优化方向从两个方面共同推进:
- 一方面,针对训练参数过多导致资源消耗巨大的情况,可以考虑通过固定基础大型语言模型的参数,引入部分特定参数进行模型训练,大大减少了算力资源的消耗,也加速了模型的训练速度。比较常用的方法包括前缀调优、提示调优等。
- 另一方面,还可以通过固定基础大型语言模型的架构,通过增加一个“新的旁路”来针对特定任务或特定数据进行微调,当前非常热门的LoRA就是通过增加一个旁路来提升模型在多任务中的表现。
接下来,我们将详细介绍11种高效的大型语言模型参数调优的方法。
本文目录
- 前缀调优
- 提示调优
- P-Tuning v2
- LoRA
- DyLoRA
- AdaLoRA
- QLoRA
- QA-LoRA
- LongLoRA
- VeRA
- S-LoRA
- 总结
1前缀调优
前缀调优(Prefix Tuning)是一种轻量级的微调替代方法,专门用于自然语言生成任务。前缀调优的灵感来自于语言模型提示,前缀就好像是“虚拟标记”一样,这种方法可在特定任务的上下文中引导模型生成文本。
前缀调优的独特之处在于它不改变语言模型的参数,而是通过冻结LM参数,仅优化一系列连续的任务特定向量(即前缀)来实现优化任务。前缀调优的架构如图1所示。
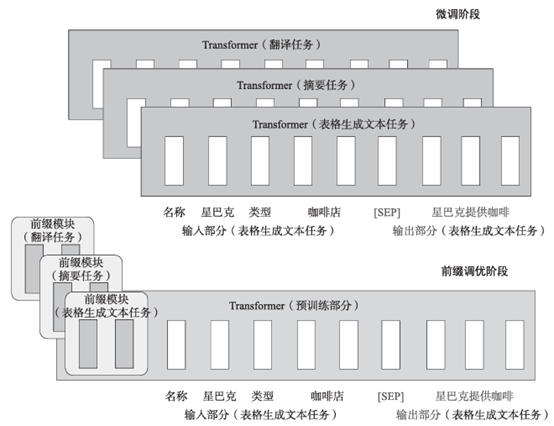
图1 前缀调优的架构
由于在训练中只需要为每个任务存储前缀,前缀调优的轻量级设计避免了存储和计算资源的浪费,同时保持了模型的性能,具有模块化和高效利用空间的特点,有望在NLP任务中提供高效的解决方案。
2提示调优
提示调优(Prompt Tuning)方法是由Brian Lester在论文“The Power of Scale for Parameter-Efficient Prompt Tuning”中提出的。
提示调优采用“软提示”(Soft Prompt)的方式,通过冻结整个预训练模型,只允许每个下游任务在输入文本前面添加k个可调的标记(Token)来优化模型参数,赋予语言模型能够执行特定的下游任务的能力。提示调优的架构如图2所示。

图2 提示调优的架构
在论文的实验对比中,对于T5-XXL模型,每个经过调整的模型副本需要110亿个参数,相较于为每个下游任务制作特定的预训练模型副本,提示调优需要的参数规模仅为20480个参数。该方法在少样本提示方面表现出色。
3P-Tuning v2
尽管提示调优在相应任务上取得了一定的效果,但当底座模型规模较小,特别是小于1000亿个参数时,效果表现不佳。为了解决这个问题,清华大学的团队提出了针对深度提示调优的优化和适应性实现——P-Tuning v2方法。
该方法最显著的改进是对预训练模型的每一层应用连续提示,而不仅仅是输入层。这实际上是一种针对大型语言模型的软提示方法,主要是将大型语言模型的词嵌入层和每个Transformer网络层前都加上新的参数。深度提示调优增加了连续提示的功能,并缩小了在各种设置之间进行微调的差距,特别是对于小型模型和困难的任务。
实验表明,P-Tuning v2在30亿到100亿个参数的不同模型规模下,以及在提取性问题回答和命名实体识别等NLP任务上,都能与传统微调的性能相匹敌,且训练成本大大降低。
4LoRA
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 121
121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









