









原文:2024大语言模型入门指南:从小白到高手(基础篇) - 哔哩哔哩
硬件资源篇
GPU(GPU)
-
消费级显卡
-
推荐30系列 3060 3070 3080 3090 显存至少8GB以上
-
推荐40系列 4060 4070 4080 4090显存至少8GB显存以上
备注:以上是英伟达GeForce系列,AMD系列、Intel系列我了解不多不推荐给大家
-
-
数据中心(服务器显卡)
-
Tesla T4 16GB显存
-
L-Series L40 L40S
-
Tesla v100 32GB显存
-
A-Series A10 A16 A30 A40 A100 A800
-
H-Series H100 H800
其他类可以参考英伟达官方https://www.nvidia.cn/Download/index.aspx?lang=en-us 里面包含更多显卡类型。
-
-
显卡资源对比参考图
这张图是服务器显卡性能对比图,也是主流模型推理和训练的显卡,从做到右边性能依次变强。
内存(RAM)
-
对于更大的模型,至少需要16GB RAM
存储(硬盘空间
-
硬盘空间用于存储数据集和模型参数,至少需要100GB存储
云服务器资源
免费云服务器资源
-
1.百度飞桨
-
-
系统地址:https://aistudio.baidu.com/
以上截图是百度飞桨提供的免费算力资源,部分资源有限制条件的。
-
-
2魔塔社区PAI-DSW
-
-
系统地址:https://modelscope.cn/
以上截图是魔塔社区PAI-DSW免费算力资源,其中GPU资源送几十个小时算力分钟数,用完就没有了。
-
-
3.阿里云机器学习PAI-DSW
-
-
系统地址:https://pai.console.aliyun.com/
阿里新户提供3个月,5000元额度的算力资源。学习测试应该是够用了。
-
-
4.启智算力平台
-
-
系统地址:https://openi.pcl.ac.cn/
是一个专门提供免费算力训练平台,积分制。通过积分换算力,非常推荐大家使用。
-
-
5.超算互联网

-
系统地址:https://www.scnet.cn/
这个平台也有很多算力资源,提供免费算力资源能长达12个月。缺点是每次运行只能2个小时。模型资源也较少。
总结对比:
收费云服务器资源
-
1.阿里云 https://www.aliyun.com/
-
2.腾讯云https://cloud.tencent.com/
-
3.华为云 https://activity.huaweicloud.com/
-
4.其他云厂商 (这里就不一一举例,主流云厂商应该都支持算力服务)
-
5模型训练细分领域厂商
-
5.1autodl

-
-
网站:https://www.autodl.com/
-
-
5.2openbayes(贝式计算)
-
-
网站:https://openbayes.com/
-
-
5.3cephalon(端脑)
-
-
网站:https://cephalon.cloud/
-
-
5.4gpumall(智算云)
-
网站:https://gpumall.com/login
-
-
5.5suanyun(晨羽智云)
-
https://www.suanyun.cn/
-
-
以上罗列一些云厂商租赁方式获得算力资源从而帮助小白快速实现大模型测试用。
软件资源篇
基础环境类
-
编程语言
-
Python
python 这个不用多说了学会接触人工智能必须了解和知道这门编程语言。python版本较多,建议使用较新版本比如:python3.10+
https://www.python.org/downloads/
-
可视化必备!功能十分强大,没有画不出来的图,分析展示就靠它了!
以上只是简单罗列了python数据计算用的依赖包,python包其实非常多。有的小伙伴会说怎么没有Transformer依赖包,别急后面会有的。
-
-
Python工具包
-
Numpy
矩阵计算必备!它是后续一切计算的核心,数据科学领域核心工具包
-
Pandas
数据处理必备!读数据,处理数据,分析数据,非他不可!
-
Matplotlib
-
-
机器学习
机器学习算法
-
分类算法
-
逻辑回归,决策树,支持向量机,集成算法,贝叶斯算法
-
-
回归算法
-
线性回归,决策树,集成算法
-
-
聚类算法
-
k-means,dbscan等
-
-
降维算法
-
主成分分析,线性判别分析等
-
-
进阶算法
-
GBDT提升算法,lightgbm,,EM算法,隐马尔科夫模型
-
-
机器学习算法实验分析
-
线性回归实验分析
-
模型评估方法
-
逻辑回归实验分析
-
聚类算法实验分析
-
决策树实验分析
-
集成算法实验分析
-
支持向量机实验分析
-
关联规则实战分析
-
深度学习
-
深度学习算法
-
神经网络
-
卷积神经网络
-
递归神经网络
-
对抗生成网络
-
序列网络模型
-
各大经典网络架构
-
-
深度学习工具
-
深度学习框架
-
Caffe框架
-
Caffe框架是一个开源的深度学习框架,由伯克利人工智能研究小组和伯克利视觉学习中心(BVLC)开发,主要用于图像处理、计算机视觉和自然语言处理等领域。Caffe框架的核心组件包括Blob、Solver、Net、Layer和Proto
-
-
Tensorflow2
-
谷歌出品,TensorFlow 2.0 框架主要关注于简化API、易用性提升以及对Keras和eager execution模式的支持。支持TPU
-
-
Keras
-
Keras框架是一个基于TensorFlow的深度学习库,它使用Python编写,并且支持多种后端框架,如TensorFlow、PyTorch和Jax。Keras不仅可以与TensorFlow无缝集成,还可以与其他深度学习框架如PyTorch和Jax进行交互
-
-
PyTorch
-
PyTorch是一个开源的深度学习框架,由Facebook的人工智能研究团队(FAIR)开发。它是基于Python的科学计算库,用于深度学习研究和GPU加速。PyTorch提供了一个简单、灵活、高效的工具,用于构建和部署深度学习模型。它支持多种平台和硬件,具有灵活的设计和高效的性能。PyTorch提供了张量计算、自动微分、动态神经网络等功能,支持在GPU上进行高效计算
-
网站:https://pytorch.org/
-
github地址:https://github.com/pytorch/pytorch
-
支持升腾架构pytorch :https://github.com/Ascend/pytorch
-
-
计算机视觉
-
自然语言处理
以上篇章涉及到机器学习、深度学习、深度学习框架、计算机视觉、自然语言处理这些作为大模型基础课程,要深入研究里面东西也非常多,这里简单罗列一下一些相关知识,后面有些东西涉及到避免小白遇到专业词语搞不懂。
补充一点:PyTorch这框架我们有时间还是需要多了解一下,后面很多地方涉及
-
自然语言处理(NLP)是一个涉及计算机科学、人工智能和语言学的交叉领域,旨在通过复杂的数学模型和算法来识别、理解和使用人类语言。
-
NLP的应用包括机器翻译、语音识别、情感分析、对话系统、文本摘要、文本生成、文本分类、文本挖掘、文本纠错和文本检索等。
-
NLP的核心任务包括但不限于句法语义分析、信息抽取、情感分析、对话系统、机器翻译等。这些任务通常需要深度学习技术,如BERT和XLNet等。
-
近年来,基于神经网络的方法在NLP领域取得了显著进展
-
操作系统
-
windows
使用模型必然会用到操作系统,我们常用操作系统winows7 、windows10 、windows11等等,这里我们就不提windows服务器版本操作系统。提windows主要是个人电脑使用,也是方便小白入门使用。如果使用服务器操作系统大概率也不会用windows服务器操作系统,linux更好用,为啥我们还用windows版本呢?
-
linux
设计到服务器linux 办法也非常多。
以上我就罗列一部分,另外还有国产操作系统。大大小小操作系统也有几十种,这个新手小白也不需要知道了,讲多了也会晕的。我们这里重点就推荐一个操作系统Ubuntu,大家可以了解这个操作系统使用即可。(掌握常用命令行即可)
-
ubuntu20 和ubuntu22.04
-
Ubuntu:Ubuntu是目前使用最广泛、下载次数最多的Linux操作系统,尤其是其长期支持版(LTS),已被数百万用户和众多企业商业使用。
-
Debian:Debian是一个可靠且稳定的Linux发行版,适用于服务器和桌面环境。它也是一个基于社区开发的发行版,与ArchLinux等一起,被广泛认知。
-
Red Hat Enterprise Linux:这是一个由商业公司维护的商业版本Linux系统,典型代表了商业版Linux系统。
-
CentOS:CentOS是一个免费的Linux发行版,根据阿里云镜像站统计,它在2021年是最受欢迎的Linux桌面操作系统之一。
-
Fedora:Fedora由Red Hat赞助,是一个开源Linux发行版,由全球社区维护。它提供了多个主要版本,包括用于桌面、服务器和云映像的版本。
-
SUSE:SUSE也是一个由大公司背后的Linux发行版,与Debian、Ubuntu等并列为常用Linux发行版。
-
-
mac
苹果电脑这个我自己没有,所以也就不给大家介绍了。(谁叫我是穷人呢?穷人不配有MAC电脑的)
容器技术
-
docker
Docker是一种开源的应用容器引擎,它允许开发者将应用及其依赖打包成一个可移植的容器。这个容器可以在任何支持Linux或Windows操作系统的服务器上运行,而无需对每个环境进行手动配置。
这里为什么提 docker 因为它能很简单方的部署后面涉及到第三方套壳软件。包括云服务器GPU资源都是使用docker技术的。这里小白不需要太多了解,掌握常用的docker 命令即可。如果单讲docker 也能讲一堆知识。我们只要知道常用 docker 命令即可。比如:docker pull docker run
关于docker 学习可以看菜鸟docker ,里面有详细内容内容。
关于docker 我们不得不提windows 桌面版本Docker Desktop。 本地电脑运行建议大家安装个这个
Docker Desktop 下载地址:https://www.docker.com/products/docker-desktop/
镜像
- 主要把依赖python运行环境,pytorch、显卡驱动打包减少模型训练推理软件安装难度,这个其实就是上面docker知识大家有个概念即可。
-
K8S
K8S是“Kubernetes”的缩写,是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用。Kubernetes提供了应用部署、规划、更新、维护的一种机制。
这个大家了解就可以了,新手小白可以不掌握。因为我们个人如果不做开发几乎涉及不到。为什么要提到它,有的小白可能会问云服务厂商提供那么多资源他怎么做到的,他怎么做的就靠这个家伙(K8S)
大语言模型LLM
-
1.大型语言模型(LLM)的概念
-
大语言模型(LLM,Large Language Model),也称大型语言模型,是一种旨在理解和生成人类语言的人工智能模型
-
-
2.LLM 的发展历程
-
语言建模采用统计学习方法来预测词汇,通过分析前面的词汇来预测下一个词汇
-
Transformer 架构的神经网络模型开始崭露头角。通过大量文本数据训练这些模型,使它们能够通过阅读大量文本来深入理解语言规则和模式,就像让计算机阅读整个互联网一样,对语言有了更深刻的理解,极大地提升了模型在各种自然语言处理任务上的表现
-
-
3.常见的 LLM 模型
-
以上图是我们过去发展的开源和闭源主流大模型。大家做个知识点了解即可。目前大模型数量肯定不止以上的截图
-
模型进化树
这个是目前大模型主要发展的三个模型技术路线,最左边是google bert模型,从树的发展来看从2021年之后就没有发展了。中间GLM技术路线,目前有清华GLM和google ul2还在发展。最右边的树目前枝叶最茂盛也是主流技术路线。包括GPT3、llama等。
4.LLM 的能力与特点
-
4.1涌现能力
-
上下文学习
-
上下文学习能力是由 GPT-3 首次引入的。这种能力允许语言模型在提供自然语言指令或多个任务示例的情况下,通过理解上下文并生成相应输出的方式来执行任务,而无需额外的训练或参数更新
-
指令遵循
-
通过使用自然语言描述的多任务数据进行微调,也就是所谓的 指令微调。LLM 被证明在使用指令形式化描述的未见过的任务上表现良好。这意味着 LLM 能够根据任务指令执行任务,而无需事先见过具体示例,展示了其强大的泛化能力
-
-
逐步推理
-
型语言模型通常难以解决涉及多个推理步骤的复杂任务,例如数学问题。然而,LLM 通过采用 思维链(CoT, Chain of Thought) 推理策略,利用包含中间推理步骤的提示机制来解决这些任务,从而得出最终答案。据推测,这种能力可能是通过对代码的训练获得的
-
-
4.2LLM 的特点
-
1.巨大的规模
-
LLM 通常具有巨大的参数规模,可以达到数十亿甚至数千亿个参数
-
-
2.预训练和微调
-
LLM 采用了预训练和微调的学习方法
-
-
3.上下文感知
-
LLM 在处理文本时具有强大的上下文感知能力,能够理解和生成依赖于前文的文本内容
-
-
4.多语言支持
-
LLM 可以用于多种语言,不仅限于英语
-
-
5.多模态支持
-
一些 LLM 已经扩展到支持多模态数据,包括文本、图像和声音
-
-
6.高计算资源需求
-
LLM 参数规模庞大,需要大量的计算资源进行训练和推理。通常需要使用高性能的 GPU 或 TPU 集群来实现
-
5 2024年4月大模型APP应用报告
5.1 全球总榜
5.2 国内总榜
6 大模型常见问题
-
6.1 模型有哪些格式
-
GGUF
-
这是由Georgi Gerganov定义的一种格式,专为大模型文件设计,是一种二进制模型文件格式。专为大模型文件设计,以便在不同平台之间进行交换和使用
-
-
PyTorch .pth 文件
-
这是使用PyTorch框架时常用的二进制格式,用于保存预训练结果
-
-
TensorFlow .safetensors 文件
-
这是TensorFlow 2.x中新增的文件格式,用于保存模型参数和优化器状态
-
-
TensorFlow .ckpt 文件
-
这是另一种用于保存模型参数的格式,虽然不如.safetensors安全,但在早期版本的TensorFlow中广泛使用
-
-
.bin 文件
-
某些特定应用或框架中的文件格式,用于存储模型参数
-
-
HDF5 (.h5)
-
这是一个广泛使用的开源数据存储格式,适用于存储大型机器学习模型的数据
-
-
.pb 文件
-
这是Google Cloud Machine Learning Engine(GCMLE)使用的格式,用于存储机器学习模型
-
-
ONNX
-
是一种开放式的文件格式,主要用于存储和交换训练好的机器学习模型。它支持多种深度学习框架,如PyTorch、TensorFlow等,使得这些框架之间可以无缝地共享和部署模型
-
6.2 NPU MLU DCU CPU TPU GPU 区别
-
1.CPU (Central Processing Unit)
CPU是中央处理单元,主要负责执行程序指令,是计算机的大脑。它优化了顺序串行处理,适合执行复杂的运算和多任务处理
-
2.GPU (Graphics Processing Unit)
-
GPU最初设计用于图形渲染,但现在也广泛用于并行计算,如深度学习和科学计算。它包含数千个小核心,专为同时处理多重任务而设计
-
-
3.TPU (Tensor Processing Unit)
-
TPU是专为机器学习模型训练和推理设计的处理器,具有大量的并行处理能力,特别适合于大规模矩阵运算
-
-
4.NPU (Neural Processing Unit)
-
NPU是专门为神经网络处理设计的处理器,通常用于边缘计算和实时数据处理场景
-
-
5.DCU (Data Center Unit)
-
DCU可能指的是数据中心用途的计算单元,虽然具体细节不详,但可以推测它与数据处理和存储相关
-
-
6.MLU (Multi-Layer Unit)
-
MLU可能是一个特定的硬件或软件单元,用于执行多层次的计算任务,但具体信息较少
-
6.3模型分类
-
1 大语言模型
-
Qwen、ChatGLM3、Baichuan、Mistral、LLaMA3、YI、InternLM2、DeepSeek、Gemma、Grok 等等
-
-
2 文本嵌入模型
-
text2vec、openai-text embedding、m3e、bge、nomic-embed-text、snowflake-arctic-embed
-
-
3 重排模型
-
bce-reranker-base_v1、bge-reranker-large、bge-reranker-v2-gemma、bge-reranker-v2-m3
-
-
4 多模态模型
-
Qwen-VL 、Qwen-Audio、YI-VL、DeepSeek-VL、Llava、MiniCPM-V、InternVL
-
-
5语音识别语音播报
-
Whisper 、VoiceCraft、StyleTTS 2 、Parler-TTS、XTTS、Genny
-
-
6.扩散模型
-
AnimateDiff、StabilityAI系列扩散模型
-
开源模型资料整理
-
模型托管平台
-
全球最大模型托管平台。HuggingFace是一个专注于自然语言处理(NLP)的开源社区和平台,它提供了大量的预训练模型、工具和资源,用于构建、训练和部署最先进的NLP模型。该平台不仅支持各种NLP任务,还提供了模型仓库、数据集等功能,使得用户可以管理代码版本、开源代码以及开源模型等。
-
1.🔥huggingface(抱脸)
-
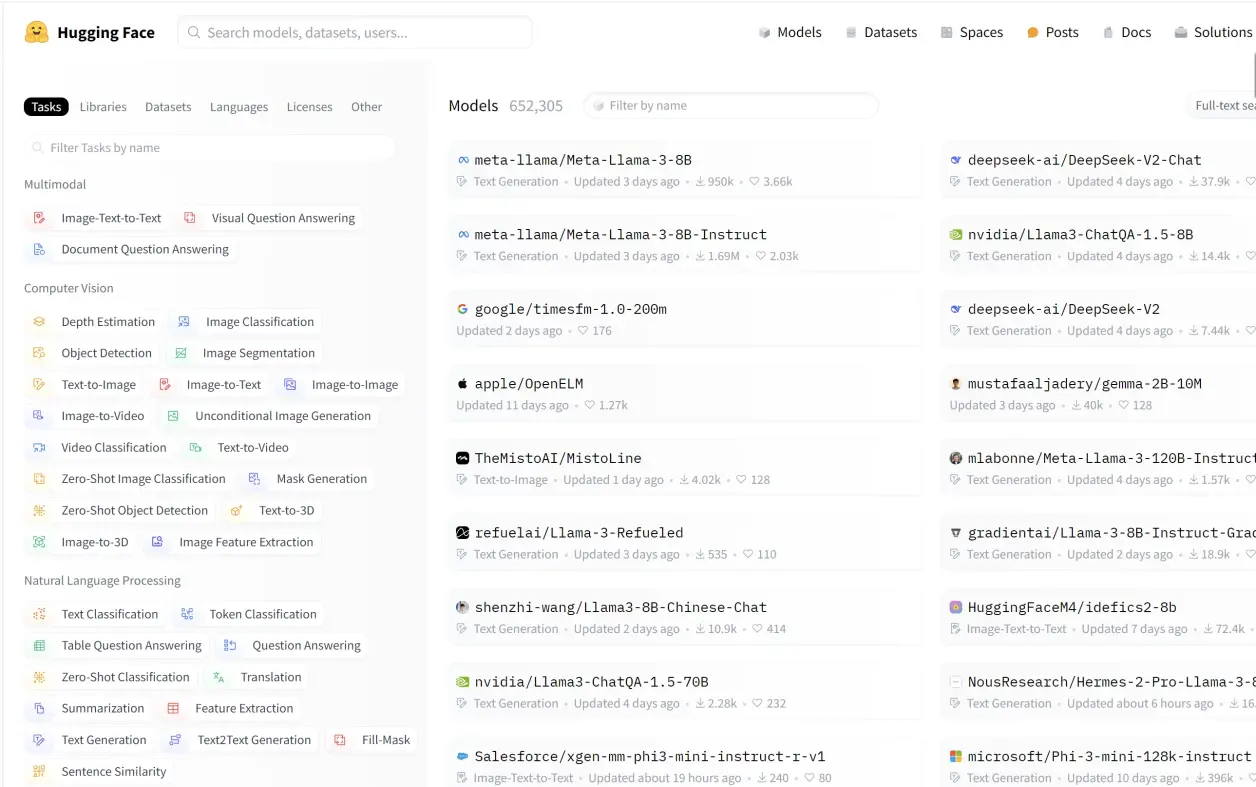
-
网站地址:https://huggingface.co/
-
2.🔥魔塔社区
-
国内最大的模型托管数据集服务平台
-
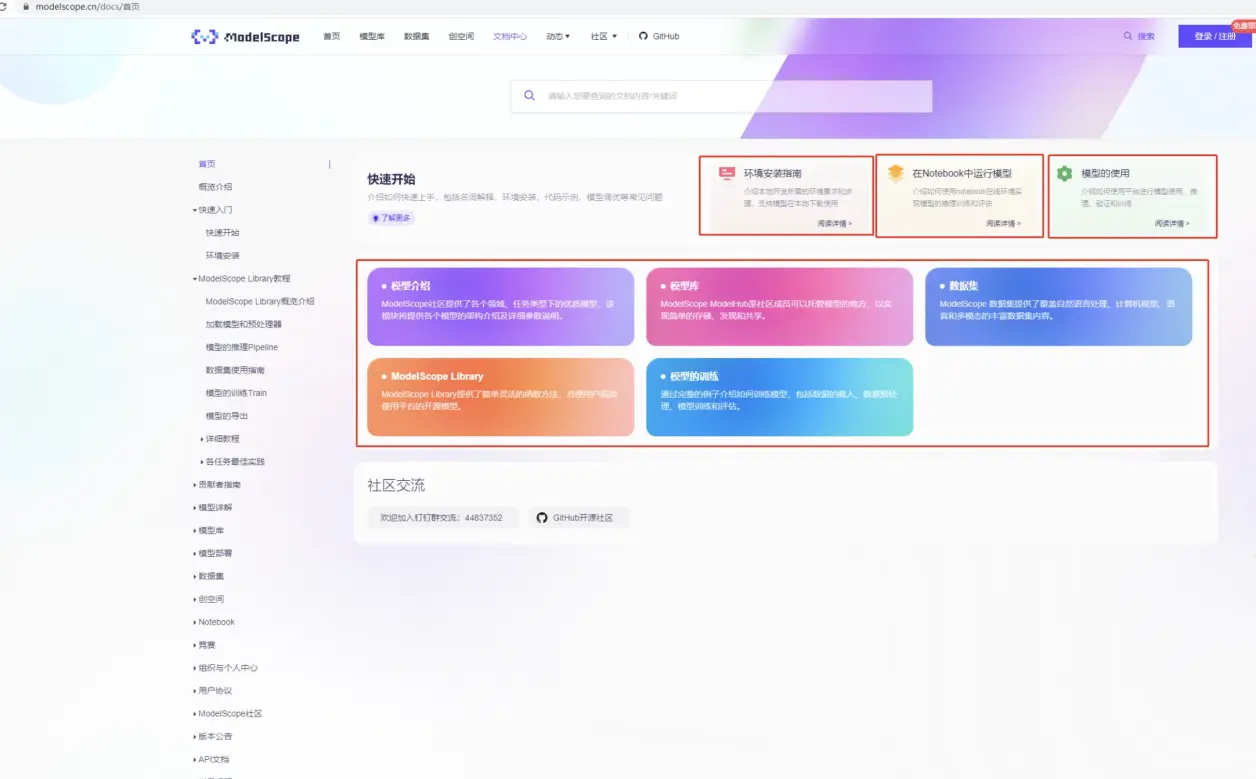
-
网站地址:https://modelscope.cn/
始智AI
-
国内发展较快的模型及数据集托管平台
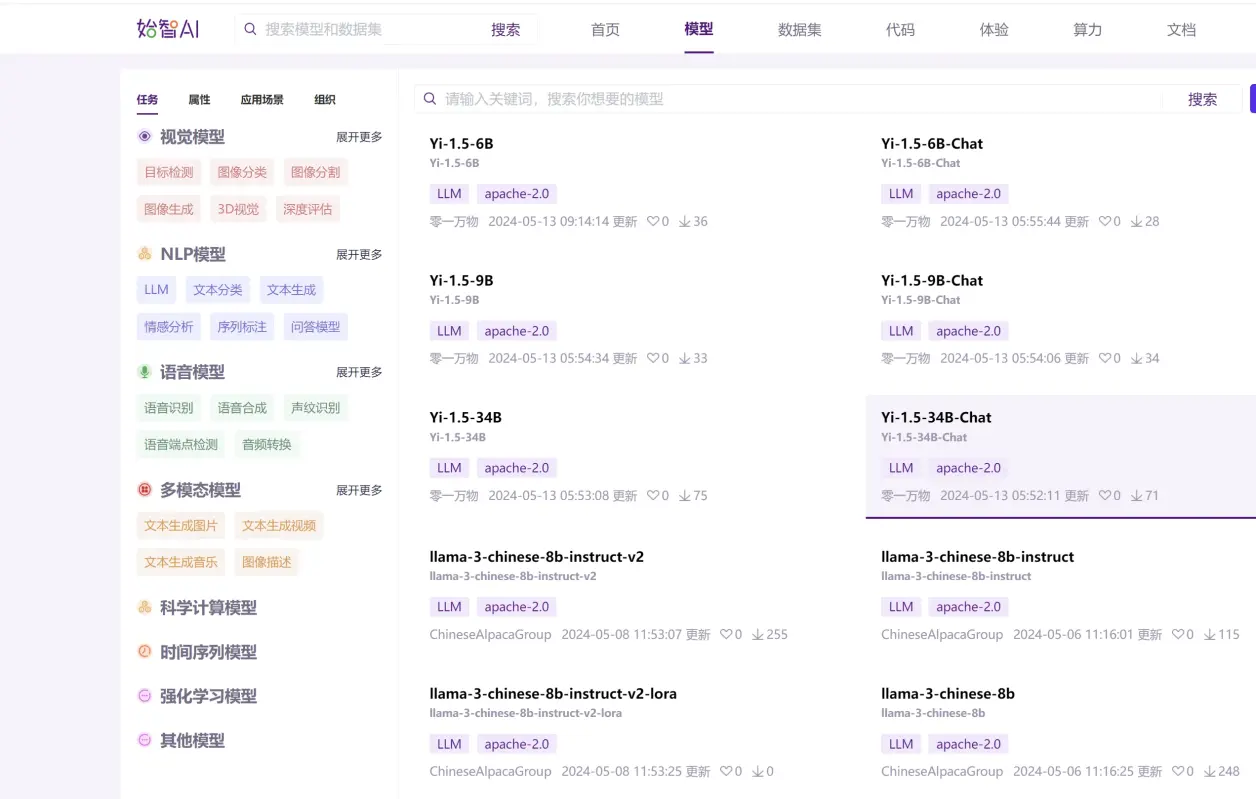
-
网站:https://wisemodel.cn/
模型评测排行榜
-
1.🔥SuperCLUE
-
SuperCLUEai是一家专注于中文人工智能模型性能评估和排名的公司
-
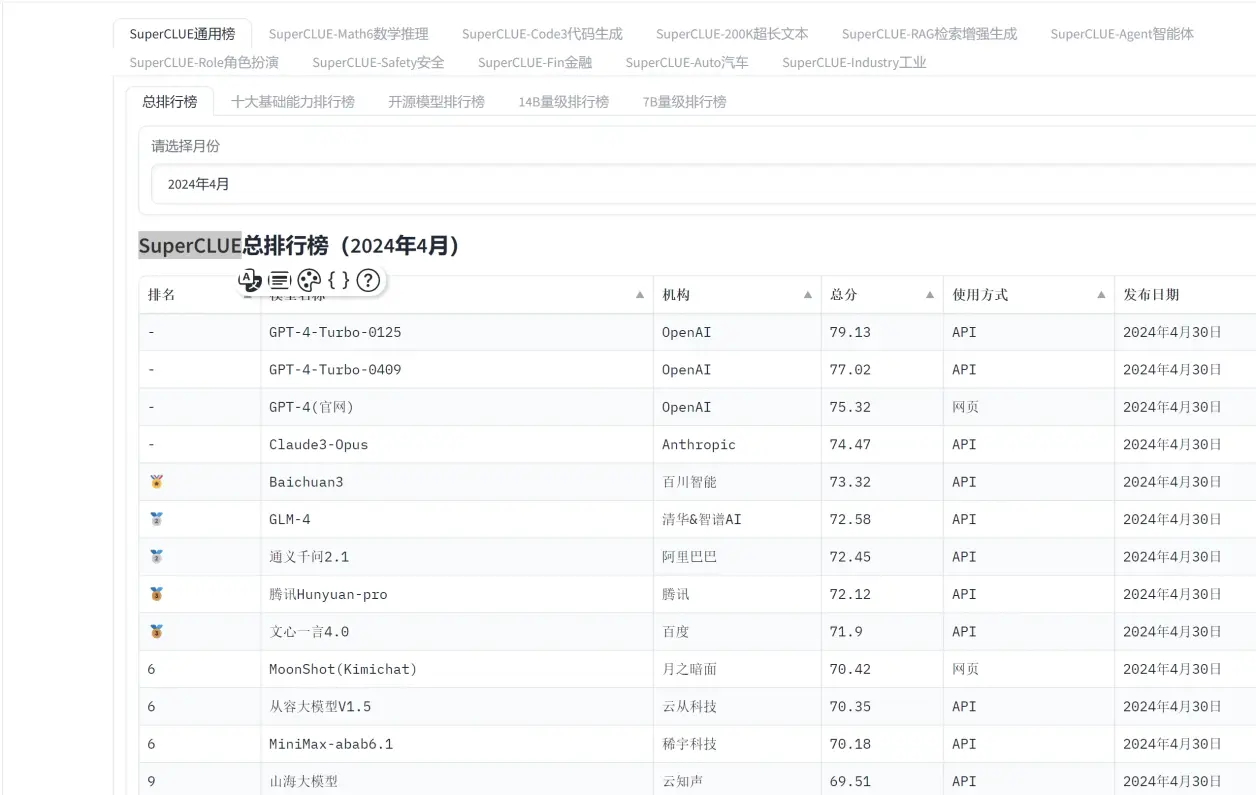
-
网站:https://www.superclueai.com/
-
2.huggingface
-
huggingface是全球最大的模型托管平台,自然也有自己评测排行榜
-
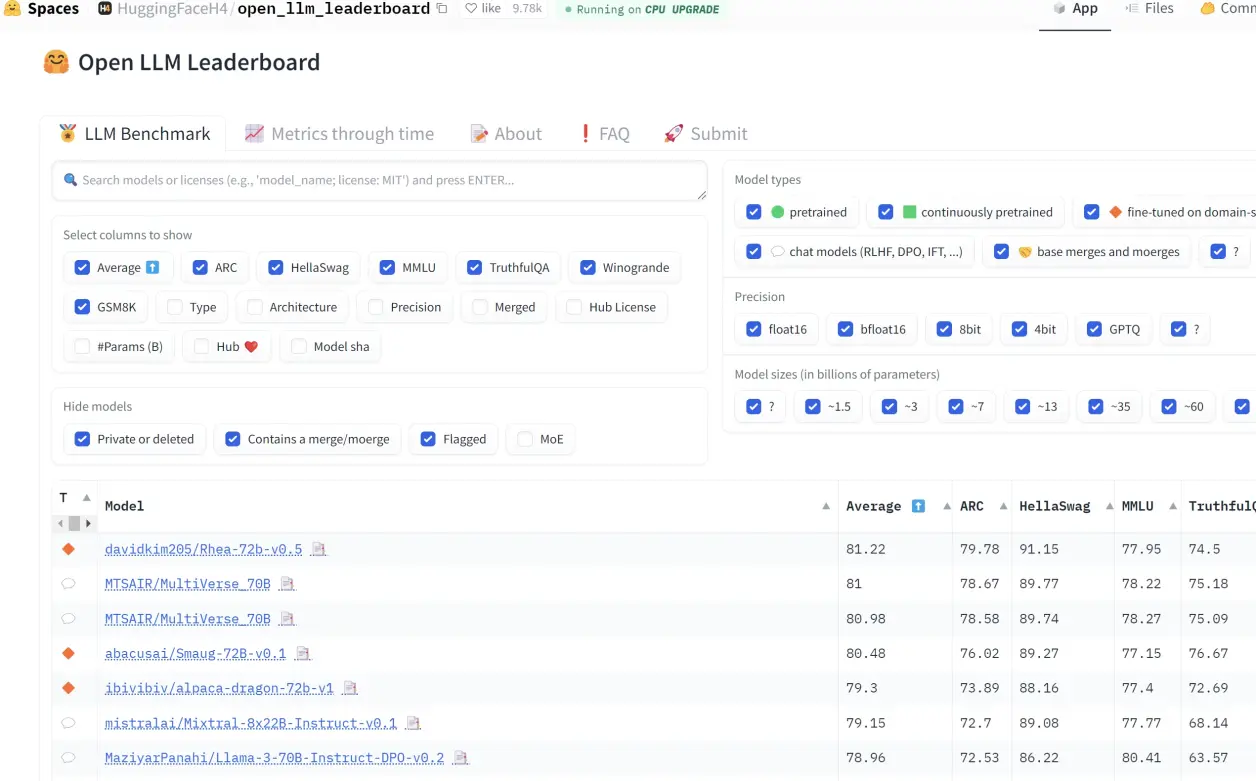
-
网站地址:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
-
3.🔥opencompass(司南)
-
国内大模型评测机构提供开源、可复现的评测框架,支持大语言模型和多模态模型的一站式评测
-
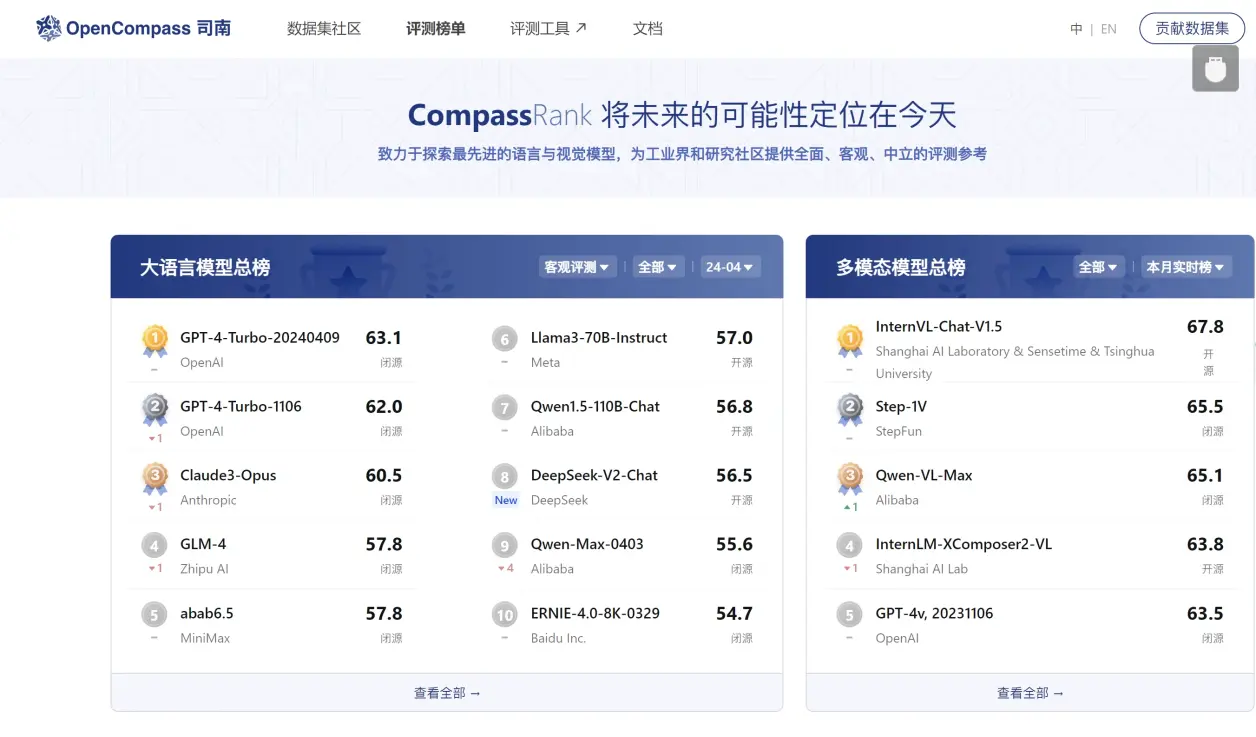
-
网站地址:https://rank.opencompass.org.cn/home
-
4.lmsys
-
一个旨在使大型模型及其系统基础设施的技术民主化的组织,用于训练、部署和评估基于大型语言模型的聊天机器人。提供较为权威的模型评测
-
网站地址:https://chat.lmsys.org/
-
开源套壳软件
-
1.🔥chatbox
-
github地址 https://github.com/Bin-Huang/chatbox/releases
-
客户端工具
-
不支持docker部署
-
2.🔥ChatGPT-Next-Web
-
GitHub地址:https://github.com/Yidadaa/ChatGPT-Next-Web
-
客户端工具+web
-
支持docker部署
3.LibreChat
-
github地址:https://github.com/danny-avila/LibreChat
-
支持docker部署

模型整合工具
-
客户端工具
-
ollama是一个开源应用程序,允许用户在本地运行、创建和共享大型语言模型(LLMs)。ollama支持MacOS和Linux系统,并且可以在这些平台上使用命令行界面来操作LLMs,支持上百种gguf格式模型。
-
1.🔥ollama
-
-
github地址:https://github.com/jmorganca/ollama
-
支持windows、linux、mac部署、支持docker部署
2.🔥LM Studio
-
LM Studio的应用程序,它支持在笔记本电脑上完全离线运行大型语言模型(LLMs),包括但不限于Hugging Face上的ggml Llama、MPT和StarCoder模型
-
网站地址:https://lmstudio.ai/
-
支持windows、linux、mac部署
3.jan
-
Jan.ai是一个专注于AI的平台,提供了多种功能和服务
-
github地址:https://github.com/janhq/jan
-
支持windows、linux、mac部署
模型推理框架
-
1.FastChat
-
FastChat 是一个开放平台,用于训练、服务和评估基于大型语言模型的聊天机器人
-
github地址:https://github.com/lm-sys/FastChat
-
-
2.🔥text-generation-webui
-
适用于大型语言模型的 Gradio Web UI transformers、GPTQ、AWQ、EXL2、llama.cpp (GGUF)、Llama 模型
-
github地址:https://github.com/oobabooga/text-generation-webui
-
-
3.llama.cpp
-
Python版本llama.cpp项目
-
github地址:https://github.com/abetlen/llama-cpp-python
-
C/C++支持的模型推理框架
-
github地址:https://github.com/ggerganov/llama.cpp
-
这个项目衍生项目llama-cpp-python
-
-
4.🔥inference
-
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理
-
github地址:https://github.com/xorbitsai/inference
-
备注:支持图像模型、文本嵌入模型、多模态模型、语音识别模型)
-
-
5.LMDeploy
-
书生浦语推出的LLM 任务的全套轻量化、部署和服务解决方案
-
github地址:https://github.com/InternLM
-
模型训练框架
-
1.🔥unsloth
-
unsloth是一个大模型微调框架可以实现微调 Mistral、Gemma、Llama 速度提高 2-5 倍,内存减少 80%
-
项目地址:https://github.com/unslothai/unsloth
-
-
2.xtuner
-
XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库
-
项目地址:https://github.com/InternLM/xtuner
-
-
3.Firefly
-
Firefly: 一站式大模型训练工具
-
项目地址:https://github.com/yangjianxin1/Firefly
-
-
4.LLaMA-Factory
-
LLaMA-Factory项目是一个专为大型语言模型(LLM)设计的微调工具。它提供了一站式Web UI界面,集成了多种训练方法,使用户能够轻松地对预训练的模型进行定制化的训练和调整,以适应特定的应用场景
-
项目地址:https://github.com/hiyouga/LLaMA-Factory/
-
-
5.🔥SWIFT
-
阿里魔塔社区提供的一站式模型推理框架
-
项目地址:https://github.com/modelscope/swift
-
支持RAG增强检索套壳框架
-
1.🔥dify
-
Dify 是一个开源的 LLM 应用开发平台。其直观的界面结合了 AI 工作流、RAG 管道、Agent、模型管理、可观测性功能等,让您可以快速从原型到生产
-
项目地址:https://github.com/langgenius/dify
-
-
2.fastgpt
-
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力
-
项目地址:https://github.com/labring/FastGPT
-
-
3.🔥lobe-chat
-
一个开源、现代设计的法学硕士/人工智能聊天框架。支持多AI提供商(OpenAI / Claude 3 / Gemini / Ollama / Bedrock / Azure / Mistral / Perplexity),多模态(Vision / TTS)和插件系统。一键免费部署您的私人 ChatGPT 聊天应用程序
-
项目地址:https://github.com/lobehub/lobe-chat
-
-
4.MaxKB
-
基于 LLM 大语言模型的知识库问答系统
-
项目地址:https://github.com/1Panel-dev/MaxKB
-
-
5.QAnything
-
有道开源的知识库管理
-
项目地址:https://github.com/netease-youdao/QAnything
-
-
以上是开源项目,其实闭源的项目也有比较好用的产品。例如: 字节跳动旗下的coze .这个coze 分为海外版和国内2个版本。海外版主要使用gpt4模型,国内版本主要使用的字节国内的豆包大模型。项目地址如下
海外版
网址:https://www.coze.com/
国内版
网站:https://www.coze.cn
开发使用开源整合框架
-
1.🔥LangChain
-
angChain 框架是一个开源工具,充分利用了大型语言模型的强大能力,以便开发各种下游应用。它的目标是为各种大型语言模型应用提供通用接口,从而简化应用程序的开发流程。具体来说,LangChain 框架可以实现数据感知和环境互动,也就是说,它能够让语言模型与其他数据来源连接,并且允许语言模型与其所处的环境进行互动
-
LangChain 的核心组件
-
模型输入/输出
-
与语言模型交互的接口
-
-
数据连接(Data connection)
-
与特定应用程序的数据进行交互的接口
-
-
链(Chains)
-
将组件组合实现端到端应用。比如后续我们会将搭建检索问答链来完成检索问答
-
-
记忆(Memory)
-
用于链的多次运行之间持久化应用程序状态
-
-
代理(Agents)
-
扩展模型的推理能力。用于复杂的应用的调用序列
-
-
回调(Callbacks)
-
扩展模型的推理能力。用于复杂的应用的调用序列
-
LangChain 的生态
开发小伙伴避免不了会接触到LangChain这个框架,所以也拿出来简单提一下。
模型实战
1.模型下载
-
LangChain Community
-
专注于第三方集成,极大地丰富了 LangChain 的生态系统,使得开发者可以更容易地构建复杂和强大的应用程序,同时也促进了社区的合作和共享
-
LangChain Core
-
LangChain 框架的核心库、核心组件,提供了基础抽象和 LangChain 表达式语言(LCEL),提供基础架构和工具,用于构建、运行和与 LLM 交互的应用程序,为 LangChain 应用程序的开发提供了坚实的基础。我们后续会用到的处理文档、格式化 prompt、输出解析等都来自这个库
-
LangChain CLI
-
命令行工具,使开发者能够通过终端与 LangChain 框架交互,执行项目初始化、测试、部署等任务。提高开发效率,让开发者能够通过简单的命令来管理整个应用程序的生命周期
-
-
LangServe
-
部署服务,用于将 LangChain 应用程序部署到云端,提供可扩展、高可用的托管解决方案,并带有监控和日志功能
-
-
LangSmith
-
开发者平台,专注于 LangChain 应用程序的开发、调试和测试,提供可视化界面和性能分析工具,旨在帮助开发者提高应用程序的质量,确保它们在部署前达到预期的性能和稳定性标准
-
-
项目地址:https://github.com/langchain-ai/langchain
-
-
这里我们需要从模型托管平台比如魔塔社区中下载模型
-
git clone https://www.modelscope.cn/01ai/Yi-1.5-9B.git
-
-
2.模型部署
-
模型推理框架FastChat、text-generation-webui 部署上面下载模型
-
可以本地安装ollama 通过命令行实现模型下载和模型部署
3.模型训练
-
我们可以使用魔塔社区swift框架部署微调模型(后面补充)
-
Llama3 中文版模型微调笔记,小白也能学会
西瓜视频(https://www.ixigua.com/7364726582587589146#/)
油管视频(https://www.youtube.com/watch?v=tarOnTrGRBw)
4.模型评测
未完待续......
5.模型发布
未完待续.....

















 5608
5608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









