







🌟关键词
- 交叉熵,KL散度(相对熵),NLL loss(负对数似然损失),BCELoss,Contrastive loss,triplet loss,n-pair loss,focal loss
- sigmoid,tanh,ReLU,PReLU,ELU,GeLU
- BGD,SGD,momentum,NAG,AdaGrad,RMSprop,Adam,AdamW
🤖损失函数
一、信息熵系列
熵 entropy
熵(entropy)描述系统的不确定性,用来衡量获取的信息的平均值, 没有获取什么信息量, 则Entropy接近0. 计算公式:
![]()
交叉熵(Cross-Entropy)
两个变量, 分别是p(真实的分布)和q(预测的概率):
![]()
- 如果预测结果是好的, 那么p和q的分布是相似的, 此时Cross-Entropy与Entropy是相似的.
- 如果p和q有很大的不同, 那么Cross-Entropy会比Entropy大.
- 其中Cross-Entropy比Entropy大的部分, 我们称为relative entropy相对熵, 或是Kullback-Leibler Divergence(KL Divergence), 这个就是KL-散度
直观理解: 熵, 交叉熵, 和KL散度 | 文艺数学君
交叉熵损失函数
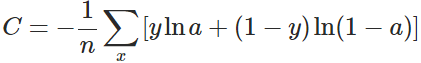
KL散度 / 相对熵
在机器学习中,不是交叉熵越接近0越好, 应该是KL-Divergence越接近0越好
![]()

KL散度的性质
- Jensen不等式证明P与Q之间的KL散度不小于0

- 最大似然估计和最小化KL散度在得出最优结果上相同
Negative Log-Likelihood Loss(负对数似然损失)
在模型训练期间,我们需要最小化模型预测结果和真实标签之间的差异,以使模型的预测结果更加接近真实结果,使用NLL损失可以帮助我们实现这一点。
具体来说,对于一个输入序列 x 和真实标签 y,我们可以使用模型预测的标签分布和真实标签 y 的对数概率来计算NLL损失,计算公式就是右半部分:
![]()
NLL损失的含义是:如果我们的模型的预测结果 越接近真实标签 y ,那么
的值就越小。
在模型训练期间,我们使用NLL损失来计算每个样本的损失值,并通过反向传播算法更新模型参数以最小化总体NLL损失。这样可以帮助我们训练出更好的模型,使其在测试数据上的表现更好。
BCELoss(加权)二分类交叉熵损失 (Binary Cross Entropy)
公式:
BCEwithlogitsloss = BCELoss + Sigmoid
WBE loss
对BCELoss加权重
WCE loss 为多分类版本
二、分类问题损失函数选择

三、 深度度量学习(deep metric learning)中的损失函数
度量学习(metric learning)研究如何在一个特定的任务上学习一个距离函数,使得该距离函数能够帮助基于近邻的算法(kNN、k-means等)取得较好的性能。
1. Contrastive loss 对比损失
对比损失在孪生神经网络(siamese network)中使用,其表达式为:

其中 d 代表两个样本特征的欧氏距离,y为两个样本是否匹配的标签,y=1代表两个样本相似或者匹配,y=0则代表不匹配,margin为设定的阈值。
这种损失函数可以很好的表达成对样本的匹配程度,也能够很好用于训练提取特征的模型。当y=1(即样本相似)时,如果在特征空间的欧式距离较大,则说明当前的模型不好,因此加大损失。而当y=0时(即样本不相似)时,其特征空间的欧式距离反而小的话,损失值会变大,这也正好符号我们的要求。
损失函数值与样本特征的欧式距离之间的关系:
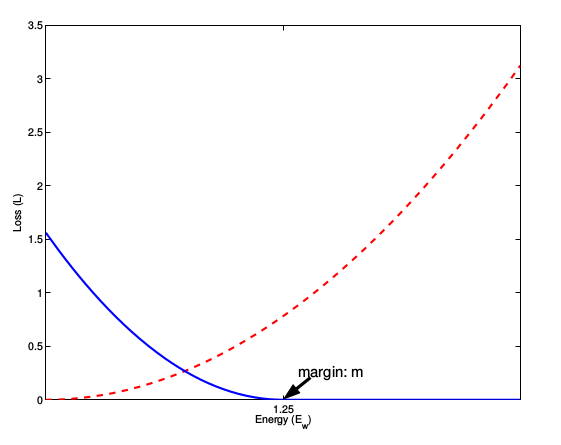 红色是相似样本的损失值,蓝色是不相似样本的损失值。
红色是相似样本的损失值,蓝色是不相似样本的损失值。
2. Triplet loss 三元组损失
Contrastive loss和triplet loss都很常用,一般来说,Triplet-Loss的效果比Contrastive Loss的效果要好,因为他考虑了正负样本与锚点(Anchor)的距离关系。然而,这两种loss函数如果单独使用则会遭遇收敛速度慢的问题。
triplet 三元组是这样构成的:从训练数据集中随机选一个样本,该样本称为Anchor,然后再随机选取一个和Anchor (记为x_a)属于同一类的样本和不同类的样本,这两个样本对应的称为Positive (记为x_p)和Negative (记为x_n)
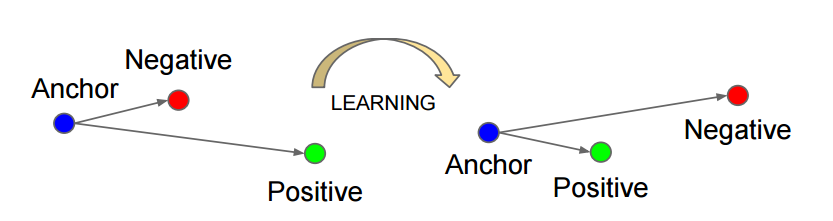
triplet loss:针对三元组中的每个元素(样本),训练一个参数共享或者不共享的网络,得到三个元素的特征表达,分别记为:f(x_a)、f(x_p)、f(x_n)。通过学习,让x_a和x_p特征表达之间的距离尽可能小,而x_a和x_n的特征表达之间的距离尽可能大,并且要让x_a与x_n之间的距离和x_a与x_p之间的距离之间有一个最小的间隔 α (类似对比损失的margin)。其目标函数表达式为:

距离用欧式距离度量,+表示[]内的值大于零的时候,取该值为损失,小于零的时候,损失为零。
 margin = α
margin = α
设置margin的原因?
- 避免模型走捷径,将negative和positive的embedding训练成很相近,也就是锚点a和正例p与锚点a和负例n的距离一样即可,这样模型很难正确区分正例和负例。
- 设定一个margin常量,可以迫使模型努力学习,能让锚点a和负例n的distance值更大,同时让锚点a和正例p的distance值更小。
- 注意margin设置很大时不容易收敛,太小则很难区分a和p
triplet loss如何构造训练集?
尽量多使用第三种:


3. N-pair loss(2016)
之前提出的contrastive loss和triplet loss中,每次更新只会使用一个负样本,而无法见到多种其他类型负样本信息,因此模型优化过程只会保证当前样本的embedding和被采样的负样本距离远,无法保证和所有类型的负样本都远,会影响模型收敛速度和效果。即使多轮更新,但是这种情况仍然会导致每轮更新的不稳定性,导致学习过程持续震荡。
N-pair loss其实就是重复利用了embedding vectors的计算来作为negative样本,避免了每一行都要计算新的negative样本的embedding vectors。计算公式:
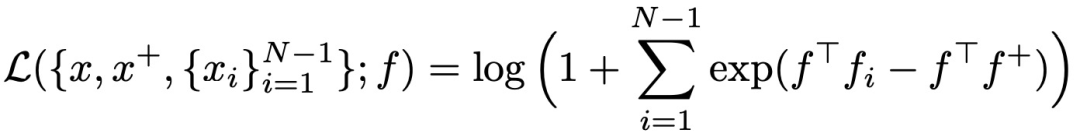
 右边为改进后N-pair
右边为改进后N-pair
为了解决负样本增加而导致的计算量增加,将一个batch内不同样本的负样本数据共享,这样只需要计算3*N个样本的embedding即可
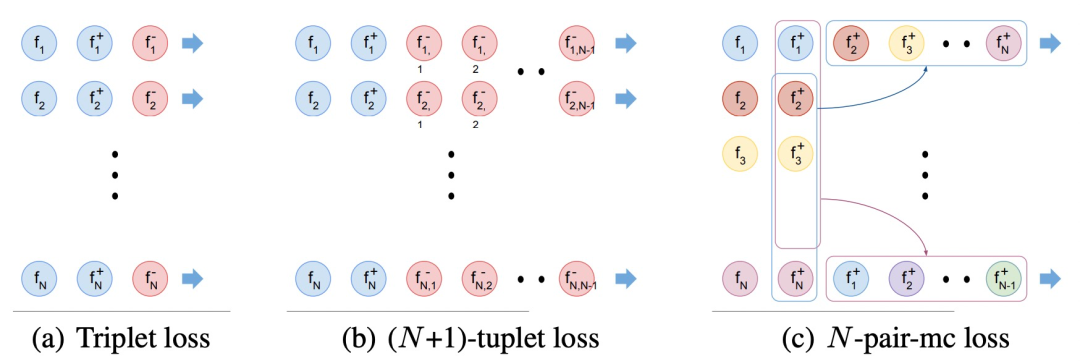
L2 norm regularization of embedding vectors
排除范数的影响——>归一化
4. InfoNce Loss (2018)
使用分类交叉熵损失在一组不相关的噪声样本中识别正样本。
5. Focal loss (2018)


四、图像分割领域
1. Dice Loss
2. 敏感性和特异性 Sensitivity and specificity(SS)
评估分割结果
3. Lovasz loss
将Jaccard index (IoU score)当做损失函数来用

🔥激活函数
激活函数分为:饱和激活函数(软和硬)和 非饱和激活函数。饱和指自变量趋于无穷时因变量导数趋于0。非饱和激活函数可以解决梯度消失并且加快收敛。

1. Sigmoid函数 (也叫标准logistic函数)
![]()
虽然具有概率解释(probabilistic interpretation),但是具有如下缺点:
1、使得网络收敛较慢(slow);2、使得网络参数解收敛不准确(inaccurate)

2. logit 函数 (logistic unit)
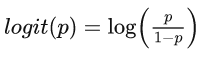 其为 sigmoid函数的反函数
其为 sigmoid函数的反函数
但在深度学习中,logits就是最终的全连接层的输出,而非其本意。通常神经网络中都是先有logits,而后通过sigmoid函数或者softmax函数得到概率p的,所以大部分情况下都无需用到logit函数的表达式。
3. tanh函数
当输入接近0时, tanh函数接近线性变换。虽然该函数的形状和sigmoid函数的形状很像,但tanh函数在坐标系的原点上对称。


4. LU(liner unit)系列函数
4.1 ELU函数
ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题,不过还是有梯度饱和和指数运算的问题
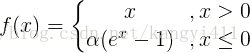
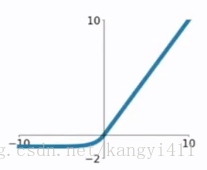
4.2 PReLU函数
如果ai是一个很小且确定的值时,PReLU就变成了LReLU。LReLU的目的是为了避免梯度为零提出来的。实验表明,LReLU在精确度上与ReLU相差无几。然而,PReLU是通过在训练中自学习参数ai的。PReLU只引进了n(n为通道数量)个参数,这和整个模型的权重数量比起来是微不足道的。因此我们预料这不会增加过拟合的风险。作者也考虑了通道共享的参数,即所有通道的ai都相等,这样就只引进了一个参数。

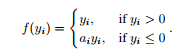
PReLU可以通过反向传播算法来更新参数。ai 的梯度为:
![]()
![]()
![]()
其中μ是动量,e代表学习速率,ε代表目标函数,ai初始值为0.25。值得注意的是,不使用权重衰减(L2正则化)来更新ai,因为这会使得ai趋向于0,变为ReLU。即使没有正则化,ai在实验中也没有超过1。作者没有限制ai的范围,因此激活函数可能是非单调的。
4.3 GeLU函数:高斯误差线性单元
GELU可以看作 dropout的思想和relu的结合,GELU对于输入乘以一个0,1组成的mask,而该mask的生成则是依概率随机的依赖于输入。假设输入为X, mask为m,则m服从一个伯努利分布


def gelu(input_tensor):
cdf = 0.5 * (1.0 + tf.erf(input_tensor / tf.sqrt(2.0)))
return input_tesnsor*cdf5. swish激活函数
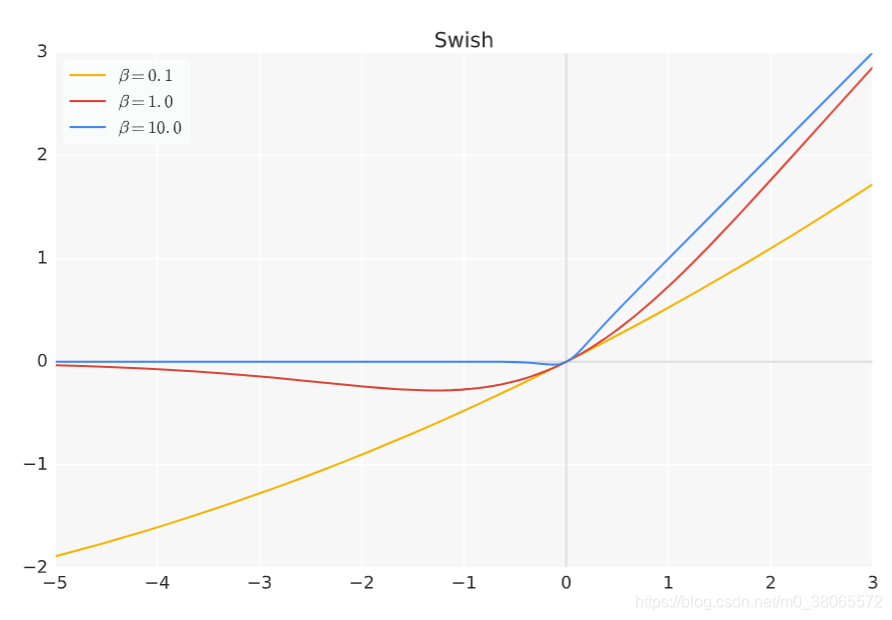

函数形式:![]()
求导过程:
- 1.Swish函数和其一阶导数都具有平滑特性;
- 2.有下界,无上界,非单调。
class SwishImplementation(torch.autograd.Function):
@staticmethod
def forward(ctx, i):
ctx.save_for_backward(i)
return i * torch.sigmoid(i)
@staticmethod
def backward(ctx, grad_output):
sigmoid_i = torch.sigmoid(ctx.saved_variables[0])
return grad_output * (sigmoid_i * (1 + ctx.saved_variables[0] * (1 - sigmoid_i)))
class Swish(nn.Module):
def forward(self, x):
return SwishImplementation.apply(x)
📈优化算法
深度学习模型的优化是一个非凸优化问题,这是与凸优化问题对应的。
对于凸优化来说,任何局部最优解即为全局最优解。用贪婪算法或梯度下降法都能收敛到全局最优解。而非凸优化问题则可能存在无数个局部最优点,有非常多的极值点,有极大值也有极小值。
除了极大极小值,还有一类值为“鞍点”,简单来说,它就是在某一些方向梯度下降,另一些方向梯度上升,形状似马鞍。
- 一阶优化算法
- 二阶优化算法:牛顿法
1. 梯度下降法(Gradient Descent)
BGD(Batch Gradient Descent)
每进行一次参数更新,需要计算整个数据样本集。收敛慢,由于每次的下降方向为总体平均梯度,它得到的会是一个全局最优解

SGD(Stochastic Gradient Descent)
每次参数更新时,仅仅选取一个样本计算其梯度。速度快,样本量大可能迭代到最优解,但梯度下降的波动非常大,更容易从一个局部最优跳到另一个局部最优,准确度下降。

Mini-batch Gradient Descent
BGD和SGD的折中,每次选取小批量数据计算梯度,目前的SGD默认是小批量梯度下降算法。

SGD缺点:
- 选择合适的learning rate比较困难 ,学习率太低会收敛缓慢,学习率过高会使收敛时的波动过大
- 所有参数都是用同样的learning rate
- SGD容易收敛到局部最优,并且在某些情况下可能被困在鞍点
2. 动量优化法
引入物理学中的动量思想,加速梯度下降,有Momentum和Nesterov两种算法。梯度方向在不变的维度上,参数更新变快,梯度有所改变时,更新参数变慢,这样就能够加快收敛并且减少动荡。
Momentum
参数更新时在一定程度上保留之前更新的方向,同时又利用当前batch的梯度微调最终的更新方向。在SGD的基础上增加动量:

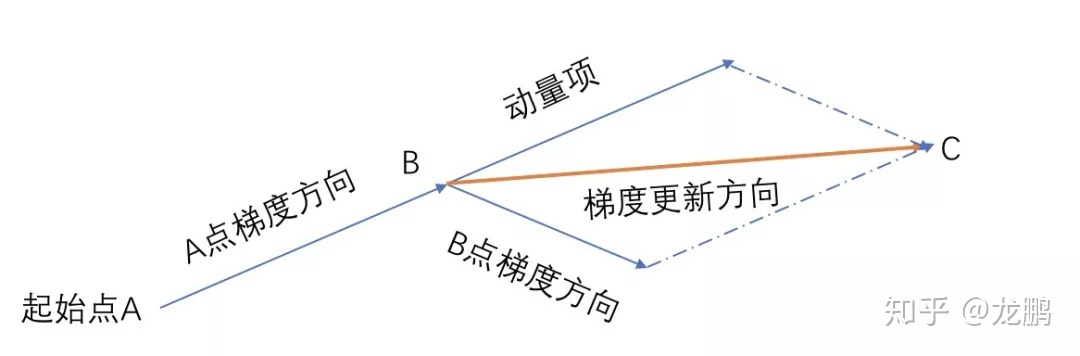
- 优点:可以使得梯度方向不变的维度上速度变快,梯度方向有所改变的维度上的更新速度变慢,这样就可以加快收敛并减小震荡。
- 缺点:这种情况相当于小球从山上滚下来时是在盲目地沿着坡滚,如果它能具备一些先知,例如快要上坡时,就知道需要减速了的话,适应性会更好。
NAG(Nesterov accelerated gradient)
NAG是momentum的改进,在梯度更新时J(θ)做一个矫正(加上nesterov项),


3. 自适应学习率优化算法
策略自适应地调节学习率的大小,从而提高训练速度。 目前的自适应学习率优化算法主要有:AdaGrad算法,RMSProp算法,Adam算法以及AdaDelta算法。
AdaGrad
将每一个参数的每一次迭代的梯度取平方累加再开方,用基础学习率除以这个数,来做学习率的动态更新。(学习率和梯度建立关系,自适应改变)
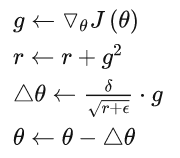
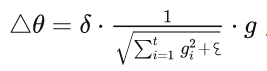
缺点:
- 仍需要手工设置一个全局学习率δ , 如果设置过大的话,会使regularizer过于敏感,对梯度的调节太大
- 中后期,分母上梯度累加的平方和会越来越大,使得参数更新量趋近于0,使得训练提前结束,无法学习
Adadelta
Adagrad会累加之前所有的梯度平方,而Adadelta只累加固定大小的项,并且也不直接存储这些项,仅仅是近似计算对应的平均值
![]()

为了解决依赖全局学习率的问题,经过近似牛顿迭代法之后:

特点:训练初中期,加速很快。训练后期,反复在局部最小值附近抖动。
RMSprop
RMSProp算法修改了AdaGrad的梯度平方和累加为指数加权的移动平均,使得其在非凸设定下效果更好。与AdaDelta区别就是使用全局学习率

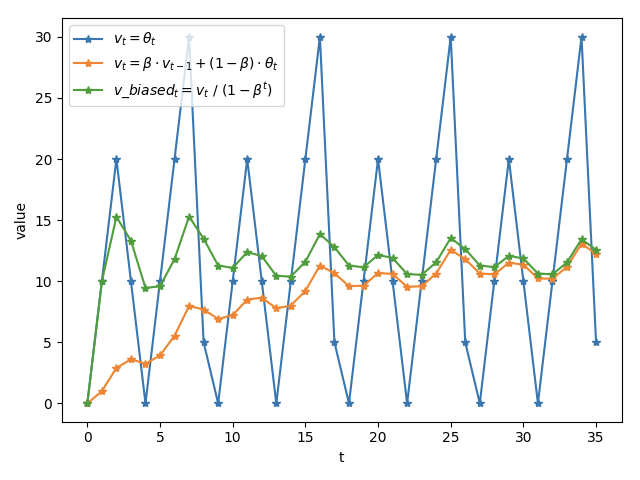
滑动平均(exponential moving average,EMA),或者叫做指数加权平均(exponentially weighted moving average),可以用来估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关。
而 t 时刻变量 v 的滑动平均值大致等于过去 1/(1−β) 个时刻 θ 值的平均。这个结论在滑动平均起始时相差比较大,所以有了Bias correction,将 vt 除以 (1−βt) 修正对均值的估计。加入了Bias correction后,
结果对比:
滑动平均的好处:占内存少,不需要保存过去10个或者100个历史 θ 值,就能够估计其均值。
滑动平均为什么在测试过程使用:对神经网络边的权重 weights 使用滑动平均,得到对应的影子变量 shadow_weights。在训练过程仍然使用原来不带滑动平均的权重 weights,不然无法得到 weights 下一步更新的值。之后在测试过程中使用 shadow_weights 来代替 weights 作为神经网络边的权重,这样在测试数据上效果更好。因为 shadow_weights 的更新更加平滑,对于随机梯度下降而言,更平滑的更新说明不会偏离最优点很远
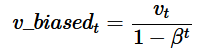
Adam(Adaptive Moment Estimation)
Adam是Momentum和RMSProp的结合体,既能适应稀疏梯度,又能缓解梯度震荡的问题。
对梯度的一阶和二阶都进行了估计与偏差修正,使用梯度的一阶矩估计和二阶矩估计来动态调整每个参数的学习率。变量更新值正比于历史梯度的一阶指数平滑值,反比于历史梯度平方的一阶指数平滑值
![]()
![]()

特点:
- Adam梯度经过偏置校正后,每一次迭代学习率都有一个固定范围,使得参数比较平稳。
- 结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
- 为不同的参数计算不同的自适应学习率
- 也适用于大多非凸优化问题——适用于大数据集和高维空间。
AdamW
Adam加入L2正则化
AMSgrad
Adam类的方法之所以会不能收敛到好的结果,是因为在优化算法中广泛使用的指数衰减方法会使得梯度的记忆时间太短。深度学习中,每一个mini-batch对结果的优化贡献是不一样的,有的产生的梯度特别有效,但是也一视同仁地被时间所遗忘。
AMSgrad使用过去平方梯度的最大值来更新参数,而不是指数平均

4. 二阶优化算法
二阶的方法因为使用了导数的二阶信息,因此其优化方向更加准确,速度也更快,这是它的优势。
但是它的劣势也极其明显,使用二阶方法通常需要直接计算或者近似估计Hessian 矩阵,一阶方法一次迭代更新复杂度为O(N),二阶方法就是O(N*N)
总结

l2_normalize
这个函数的作用是利用 L2 范数对指定维度 dim 进行标准化。
对某个一维张量,dim=0,则 output = x / sqrt(max(sum(x**2), epsilon))
References
【深度学习笔记】深入理解激活函数_月满星沉的博客-CSDN博客_激活函数作用















 1663
1663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









