






必须使用24G显存的显卡(3090ti or 4090以上)
llama3.2:11B 申请不到,可以通过modelscope下载,但建议通过代码自动下载。
环境安装:
conda create -n llama3.2:11B python=3.10
conda activate llama3.2:11B
# 本人测试版本:显卡驱动:550 cuda:12.4 cudnn:9.5.1 pytorch:2.5.1
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install transformers modelscope accelerate sentencepiece Protobuf Gradio1、用户交互界面
创建gradio_app_llama3.2_11B.py文件:
import gradio as gr
from transformers import MllamaForConditionalGeneration, AutoProcessor
import torch
from PIL import Image
from modelscope import snapshot_download
# 通过代码自动下载
model_id = "LLM-Research/Llama-3.2-11B-Vision-Instruct"
model_dir = snapshot_download(model_id, ignore_file_pattern=['*.pth'])
# 加载Llama 3.2 11B模型
model = MllamaForConditionalGeneration.from_pretrained(
model_dir,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_dir)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": " "}
]}
]
# 定义推理函数,处理图片和文本
def llama_generate(image, text):
messages[0]["content"][1]["text"] = text
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(image, input_text, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=300)
return processor.decode(output[0], skip_special_tokens=True)
# 使用Gradio构建UI,添加图片和文本输入
demo = gr.Interface(fn=llama_generate,
inputs=["image", "text"],
outputs="text",
title="Llama 3.2 11B 模型(图片+文本)")
# 启动界面
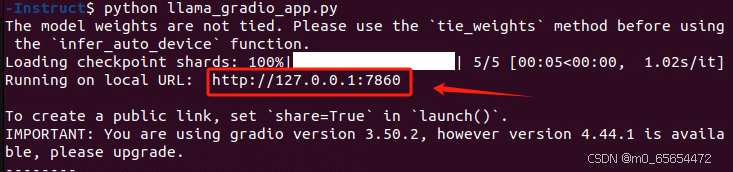
demo.launch()启动服务:python ./gradio_app_llama3.2_11B.py.
用浏览器访问给出的本地地址:
2、本地流式推理
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
from modelscope import snapshot_download
import os
model_id = "LLM-Research/Llama-3.2-11B-Vision-Instruct"
model_dir = snapshot_download(model_id, ignore_file_pattern=['*.pth'])
model = MllamaForConditionalGeneration.from_pretrained(
model_dir,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_dir)
# setting!
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": ""}
]}
]
# 输入图片文件夹
dir_path = "./"
with open("./result.txt", "w") as f:
for file_name in os.listdir(dir_path):
image = Image.open(os.path.join(dir_path, file_name))
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(image, input_text, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=300)
result = processor.decode(output[0], skip_special_tokens=True)
result = result.split("\n")
f.write(file_name + ": ")
for i in result:
f.write(i.strip())
f.write("\n")
f.close()

















 2466
2466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









