






摘要:随着OpenAI发布o1模型,采用慢思考策略的推理模型逐渐出现。 由于此类模型产生的响应通常包含复杂的推理、中间步骤和自我反思,因此现有的评估方法往往不够充分。 他们很难确定LLM的输出是否真的与参考答案相同,而且很难从冗长复杂的回复中识别和提取最终答案。 为了解决这个问题,我们提出了xVerify,这是一种高效的答案验证器,用于推理模型评估。 xVerify在等价性判断方面展示了强大的能力,使其能够有效地确定推理模型产生的答案是否与各种类型的客观问题的参考答案等价。 为了训练和评估xVerify,我们通过收集多个LLM在各种数据集上生成的问答对,利用多个推理模型和专门为推理模型评估设计的具有挑战性的评估集,构建了VAR数据集。 采用多轮注释过程来确保标签准确性。 基于VAR数据集,我们训练了多个不同规模的xVerify模型。 在测试集和泛化集上进行的评估实验中,所有xVerify模型都获得了超过95%的总体F1得分和准确率。 值得注意的是,最小的变体xVerify-0.5B-I优于除GPT-4o之外的所有评估方法,而xVerify-3B-Ib在整体性能上超过了GPT-4o。 这些结果验证了xVerify的有效性和通用性。Huggingface链接:Paper page,论文链接:2504.10481
研究背景与目的
研究背景
随着大型语言模型(LLMs)的不断发展,尤其是那些具备复杂推理能力的模型,如OpenAI的o1、o3-mini,以及DeepSeek-R1等,对LLMs的评估成为了一个日益重要且充满挑战的问题。这些先进的推理模型通常生成包含详细推理过程的长响应,这些响应中可能包含中间步骤、自我反思和复杂的数学表达式等内容。然而,现有的评估方法往往难以应对这种复杂性。
传统的自动评估方法,如基于规则的评估框架(如LM Eval Harness、OpenCompass等)和基于LLM的判断模型(如JudgeLM、PandaLM等),在处理这种包含复杂推理的长响应时存在明显局限。基于规则的评估框架通常依赖于严格的格式要求,难以处理格式多样的推理响应,且往往忽略推理过程本身。而基于LLM的判断模型虽然具备更强的任务适应性,但在处理需要精确等价性判断的客观问题时表现不佳,尤其是在检测长链式推理响应中的错误时。
此外,人工评估虽然灵活,但成本高昂且难以扩展,不适合大规模评估任务。因此,如何高效、准确地评估推理模型的长响应成为了一个亟待解决的问题。
研究目的
本研究旨在提出一种高效且准确的答案验证器xVerify,以专门用于评估推理模型生成的客观问题响应。xVerify旨在解决现有评估方法在处理包含复杂推理的长响应时的不足,通过强大的等价性判断能力,有效地确定推理模型生成的答案是否与参考答案等价。同时,xVerify还具备对长响应中最终答案的准确识别和提取能力,从而适应不同类型客观问题的评估需求。
研究方法
数据集构建
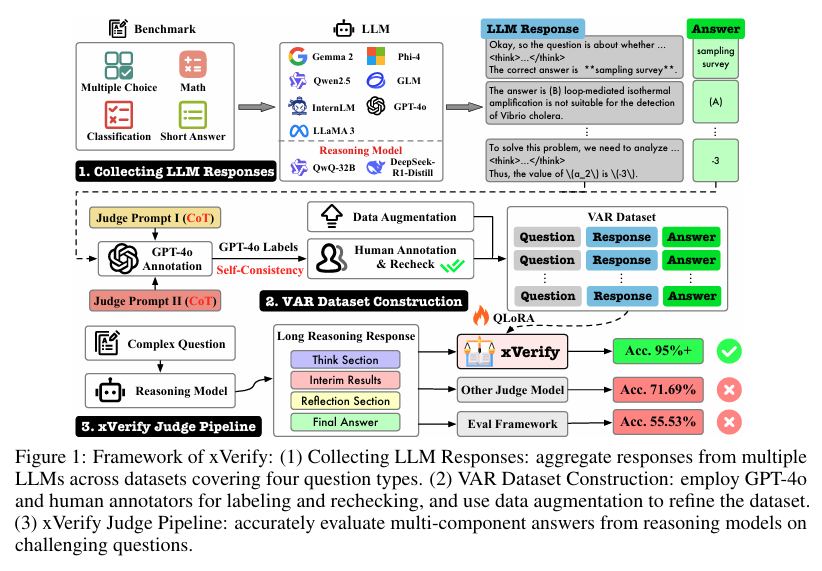
为了训练和评估xVerify,本研究构建了一个名为VAR(Verify Answer for Reasoning)的数据集。VAR数据集通过收集多个LLM在各种数据集上生成的问答对来构建,涵盖了多选择、数学、简答题和分类等四种问题类型。在数据生成过程中,采用了多种提示模板来引导LLM生成响应,以模拟真实的评估场景。
为了确保数据集的准确性和多样性,采用了多轮注释过程。首先,使用GPT-4o对所有样本进行两轮注释,然后人工注释员对具有挑战性的数学问题以及GPT-4o注释不一致的样本进行手动注释。此外,还设计了数据增强策略,通过添加噪声、转换选项格式和变换最终答案表述等方式,进一步提高了数据集的多样性和复杂性。
模型训练
基于VAR数据集,本研究训练了多个不同规模和架构的xVerify模型。在模型训练过程中,采用了LLaMA-Factory框架和QLoRA技术,通过优化超参数设置,确保了模型的训练效率和性能。此外,为了全面评估xVerify的泛化能力,还训练了多个具有不同参数规模和架构的xVerify模型。
评估方法
在评估阶段,本研究采用了准确率(Accuracy)和F1得分(F1 Score)作为主要评估指标,分别在测试集和泛化集上对xVerify模型进行了评估。测试集用于评估xVerify模型的基本性能,而泛化集则用于模拟更广泛的样本分布,以评估xVerify模型的泛化能力。同时,还将xVerify模型与多种现有的评估框架和判断模型进行了比较,以验证其有效性和通用性。
研究结果
整体性能
在测试集上,所有xVerify模型都取得了超过95%的总体F1得分和准确率,显著优于现有的评估框架和判断模型。特别是xVerify-0.5B-I模型,尽管参数量最小,但其性能仍然优于除GPT-4o之外的所有评估方法。而xVerify-3B-Ib模型则在整体性能上超过了GPT-4o。
在泛化集上,xVerify模型同样表现出了强大的泛化能力。尽管整体性能略有下降,但下降幅度不超过1.5%,且仍然优于其他评估方法。特别是较大的xVerify模型(如xVerify-32B-I)在泛化集上的性能下降幅度更小,表现出更强的泛化能力。
具体任务表现
在不同类型的问题上,xVerify模型也表现出了稳定的性能。在数学问题上,xVerify模型的表现尤为突出,所有xVerify模型(除了xVerify-0.5B-I)在数学问题上的F1得分和准确率都超过了95%。这表明xVerify模型在处理需要精确等价性判断的数学问题时具有显著优势。
研究局限
尽管xVerify模型在评估推理模型生成的长响应方面取得了显著成果,但仍存在一些局限性。首先,xVerify模型的性能受到训练数据集质量和规模的影响。如果训练数据集中存在噪声或样本分布不均等问题,可能会影响xVerify模型的准确性和泛化能力。
其次,xVerify模型在处理某些特定类型的推理问题时可能仍存在不足。例如,在处理需要复杂上下文理解和多步骤推理的问题时,xVerify模型可能需要进一步优化其等价性判断能力和最终答案提取能力。
未来研究方向
针对上述研究局限,未来的研究可以从以下几个方面展开:
-
优化训练数据集:通过收集更高质量、更多样化的训练数据,进一步提高xVerify模型的准确性和泛化能力。可以考虑引入更多领域的推理问题和更复杂的推理场景,以增强xVerify模型的鲁棒性。
-
改进模型架构:探索更先进的模型架构和训练技术,如自注意力机制、知识蒸馏等,以进一步提高xVerify模型的等价性判断能力和最终答案提取能力。同时,还可以考虑将xVerify模型与其他评估方法相结合,形成更全面的评估体系。
-
拓展应用场景:将xVerify模型应用于更多实际的推理模型评估场景中,如自动问答系统、知识推理引擎等。通过在实际应用中的不断验证和优化,进一步提升xVerify模型的实用性和可靠性。
-
加强国际合作与交流:与国际上的相关研究机构和学者加强合作与交流,共同推动推理模型评估领域的发展。通过分享研究成果和经验教训,促进学术进步和技术创新。
综上所述,本研究提出的xVerify模型为评估推理模型生成的长响应提供了一种高效且准确的方法。未来的研究将进一步优化xVerify模型的性能和泛化能力,拓展其应用场景和实用价值。

















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









