






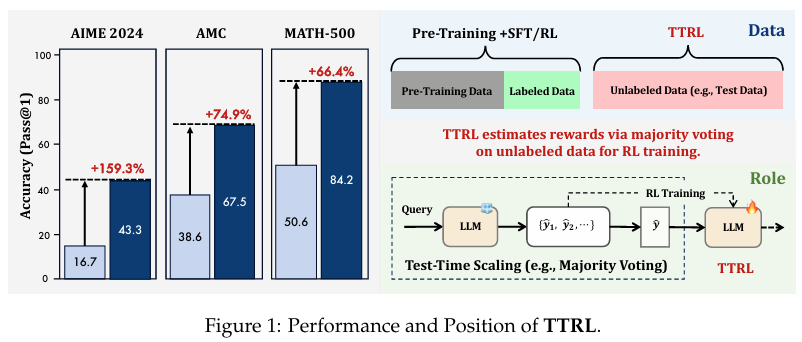
摘要:本文研究了在没有明确标签的情况下,强化学习(RL)在大型语言模型(LLM)中的推理任务。 该问题的核心挑战是在推理过程中进行奖励估计,同时无法访问地面实况信息。 虽然这种设置似乎难以捉摸,但我们发现测试时间缩放(TTS)中的常见做法,如多数投票,会产生出奇有效的奖励,适合推动强化学习训练。 在这项工作中,我们引入了测试时间强化学习(TTRL),这是一种在未标记数据上使用RL训练LLM的新方法。 TTRL通过利用预训练模型中的先验知识来实现LLM的自我进化。 我们的实验表明,TTRL在各种任务和模型中都能持续提高性能。 值得注意的是,TTRL在AIME 2024上仅使用未标记的测试数据就将Qwen-2.5-Math-7B的pass@1性能提高了约159%。 此外,尽管TTRL仅由Maj@N度量监督,但TTRL已经证明其性能始终超过初始模型的上限,并接近直接在具有地面真实标签的测试数据上训练的模型的性能。 我们的实验结果验证了TTRL在各种任务中的普遍有效性,并突出了TTRL在更广泛的领域和任务中的潜力。github:https://github.com/PRIME-RL/TTRL。Huggingface链接:Paper page,论文链接:2504.16084
研究背景和目的
研究背景
随着大型语言模型(LLMs)在自然语言处理领域的快速发展,如何进一步提升这些模型在复杂任务上的性能成为了当前研究的热点。传统的监督学习方法依赖于大量带有标签的数据,然而在实际应用中,获取高质量、大规模的标注数据往往成本高昂且效率低下。此外,对于新兴领域或快速变化的任务,及时获取足够的标注数据尤为困难。因此,如何有效利用未标注数据来增强LLMs的性能成为了一个亟待解决的问题。
近年来,测试时间缩放(TTS)技术,如多数投票和蒙特卡洛树搜索等,为提升LLMs在推理任务上的表现提供了一种新的思路。这些方法通过在推理阶段增加计算资源来提高模型性能,而无需重新训练模型。然而,这些方法主要依赖于模型的内部知识,缺乏对外界信息的利用和自我进化能力。
强化学习(RL)作为一种让智能体在与环境交互的过程中学习最优策略的方法,已经在多个领域取得了显著成果。特别是在大型语言模型的训练中,RL已经被证明能够有效提升模型生成连贯、符合逻辑的文本的能力。然而,现有的RL方法大多依赖于大量的标注数据来指导训练过程,这在很多实际应用场景中是不可行的。
研究目的
针对上述问题,本研究旨在提出一种新的测试时间强化学习(TTRL)方法,利用未标注数据来训练大型语言模型,以提升其在推理任务上的性能。具体目标包括:
-
探索利用未标注数据进行强化学习的可行性:通过设计合适的奖励估计方法,使LLMs能够在没有地面真实标签的情况下进行自我优化。
-
提高LLMs在推理任务上的性能:通过TTRL方法,使LLMs能够更有效地处理复杂推理任务,生成更准确、更有逻辑性的回答。
-
减少对数据标注的依赖:通过利用未标注数据,降低模型训练的成本和时间,使LLMs的训练过程更加灵活和高效。
-
推动LLMs的自我进化能力:使LLMs能够在与环境的交互中不断学习和优化自身,以适应不断变化的任务需求。
研究方法
方法概述
TTRL方法的核心思想是在测试时间利用强化学习技术来优化大型语言模型的性能。具体来说,该方法通过生成多个候选输出,并使用多数投票等方法来估计真实标签,从而计算奖励信号,进而指导模型的自我优化过程。
具体步骤
-
生成候选输出:对于给定的输入问题,LLM生成多个候选回答。这些候选回答是通过重复采样模型得到的。
-
估计真实标签:使用多数投票等方法从候选回答中估计出最可能的真实标签。这一步是奖励估计的关键,因为它决定了模型在后续优化过程中应该追求什么样的目标。
-
计算奖励信号:根据估计出的真实标签和候选回答之间的差异,计算每个候选回答的奖励信号。奖励信号的大小反映了候选回答与真实标签之间的接近程度。
-
优化模型参数:利用计算出的奖励信号,通过梯度上升等方法优化LLM的参数,使模型在未来生成更接近于真实标签的回答。
-
重复迭代:上述过程不断重复,直到模型性能达到收敛或达到预设的训练轮次。
奖励函数设计
在TTRL方法中,奖励函数的设计至关重要。本研究采用了一种基于规则的奖励函数,即如果候选回答与估计出的真实标签相匹配,则给予正奖励;否则,给予负奖励。这种奖励函数简单有效,能够引导模型朝着正确的方向进行优化。
研究结果
性能提升
实验结果表明,TTRL方法在各种任务和模型上都能显著提升性能。特别是在AIME 2024数学推理基准测试上,TTRL将Qwen-2.5-Math-7B模型的pass@1性能提高了约159%。此外,TTRL的性能还超过了初始模型的上限(Maj@N),并接近了直接在带有地面真实标签的测试数据上训练的模型的性能。
泛化能力
TTRL方法不仅在当前任务上取得了显著的性能提升,还表现出了良好的泛化能力。实验结果表明,经过TTRL优化的模型在其他未参与训练的基准测试上也取得了更好的性能。这说明TTRL方法不仅提高了模型在当前任务上的表现,还增强了模型的整体泛化能力。
兼容性和可扩展性
TTRL方法具有良好的兼容性和可扩展性。实验表明,TTRL可以与不同的RL算法相结合,如GRPO和PPO等,并在各种规模和类型的模型上取得显著效果。此外,随着模型规模和计算资源的增加,TTRL的性能有望进一步提升。
研究局限
尽管TTRL方法在实验中取得了显著效果,但仍存在一些局限性:
-
对初始模型性能的依赖:TTRL方法的性能在很大程度上依赖于初始模型的性能。如果初始模型的性能较差,那么TTRL可能无法取得显著的效果。
-
对任务复杂度的敏感性:对于过于复杂或新颖的任务,TTRL方法可能无法准确估计奖励信号,从而影响模型的优化效果。
-
超参数设置的敏感性:TTRL方法的性能对超参数设置较为敏感。不同的超参数设置可能导致截然不同的优化效果。
-
计算资源的消耗:TTRL方法在训练过程中需要生成多个候选输出并计算奖励信号,这可能会消耗大量的计算资源。
未来研究方向
针对上述局限性,未来的研究可以从以下几个方面展开:
-
提高初始模型的性能:通过引入更先进的预训练技术和更丰富的训练数据,提高初始模型的性能,从而为TTRL方法提供更好的起点。
-
设计更复杂的奖励函数:针对复杂任务,设计更复杂的奖励函数,以更准确地反映候选回答与真实标签之间的差异。
-
自动化超参数调整:利用贝叶斯优化等方法自动调整超参数设置,以减少对人工调参的依赖并提高模型的优化效果。
-
优化计算资源的使用:通过引入更高效的算法和更强大的计算资源,降低TTRL方法的计算成本,使其能够在更大规模的模型和数据集上得到应用。
-
探索更广泛的应用场景:将TTRL方法应用于更多类型的任务和领域,如文本生成、对话系统等,以验证其普遍有效性和实用性。
总之,TTRL方法作为一种新的测试时间强化学习方法,为利用未标注数据训练大型语言模型提供了新的思路。未来的研究将进一步探索其潜力和应用前景,并努力克服其局限性,以推动自然语言处理领域的发展。

















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









