






一、Yolov1
1、统一检测
不同于CNN或者Fast-CNN,YoloV1的目标检测的定位和分类是同时完成。
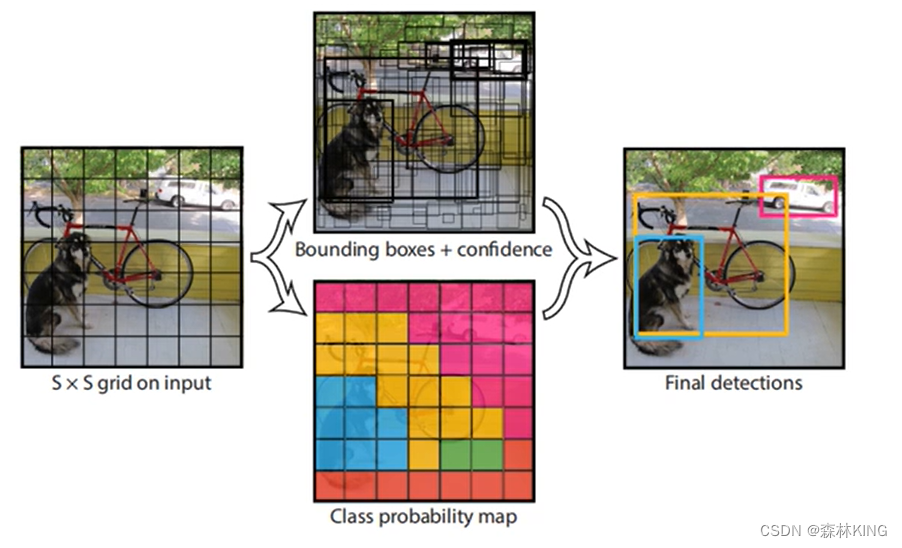
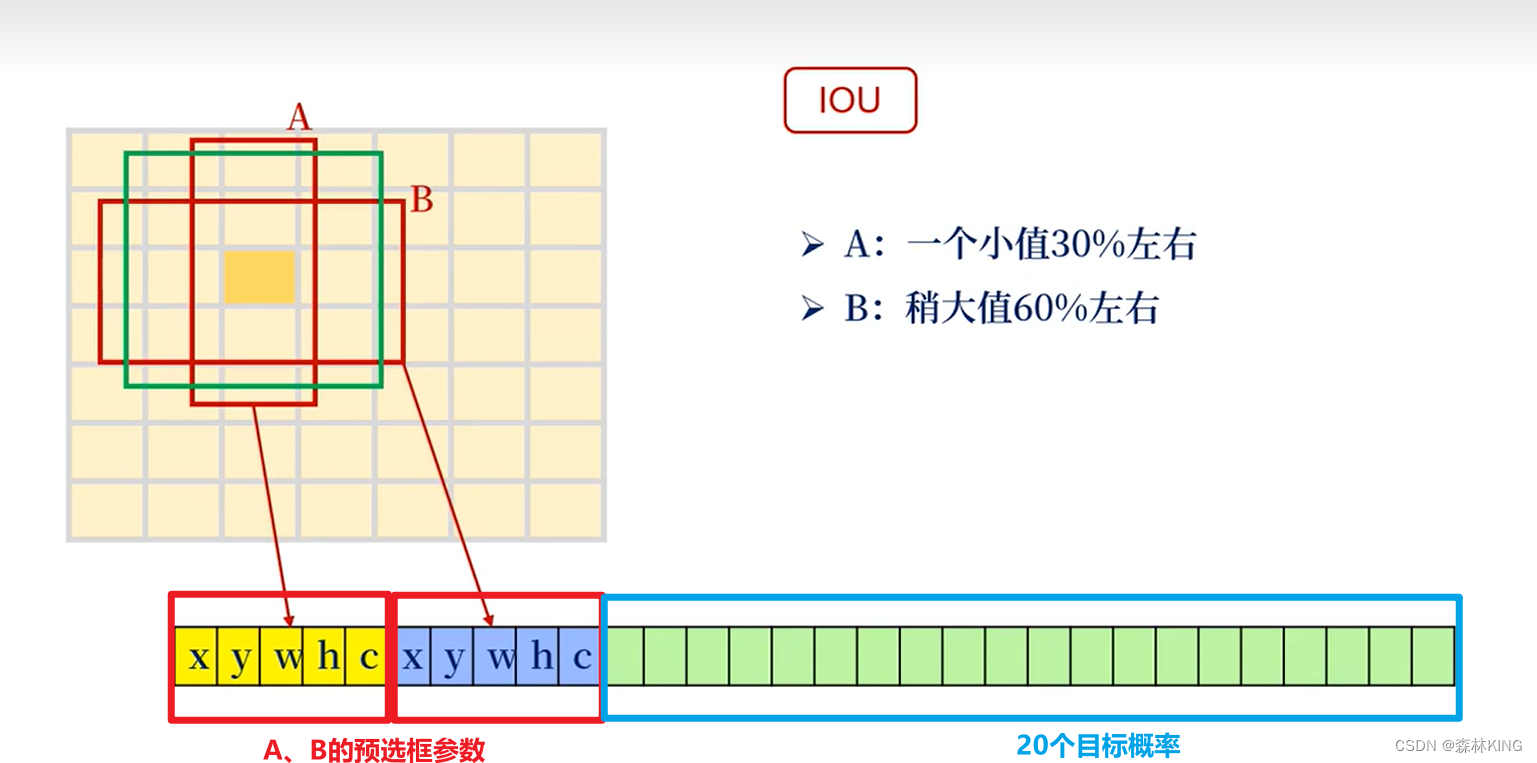
S×S×(B*5+C)YOLO将图像分成7x7的格子,每个格子预测两个框,总共预测98个框;即每个cell有B个bounding box,B=2,每个格子两个预测,对20个物体类别进行检测的预测概率,C=20;
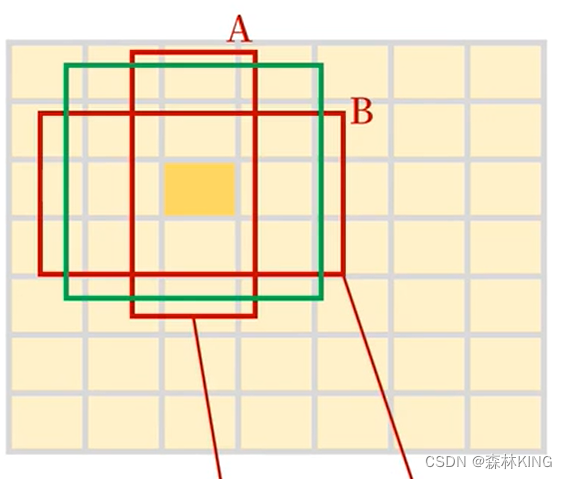
**预测框(bounding box)和真实框(ground truth box)**如下:预测框A、预测框B、绿色标注框(真实框)
2、定位参数bounding box
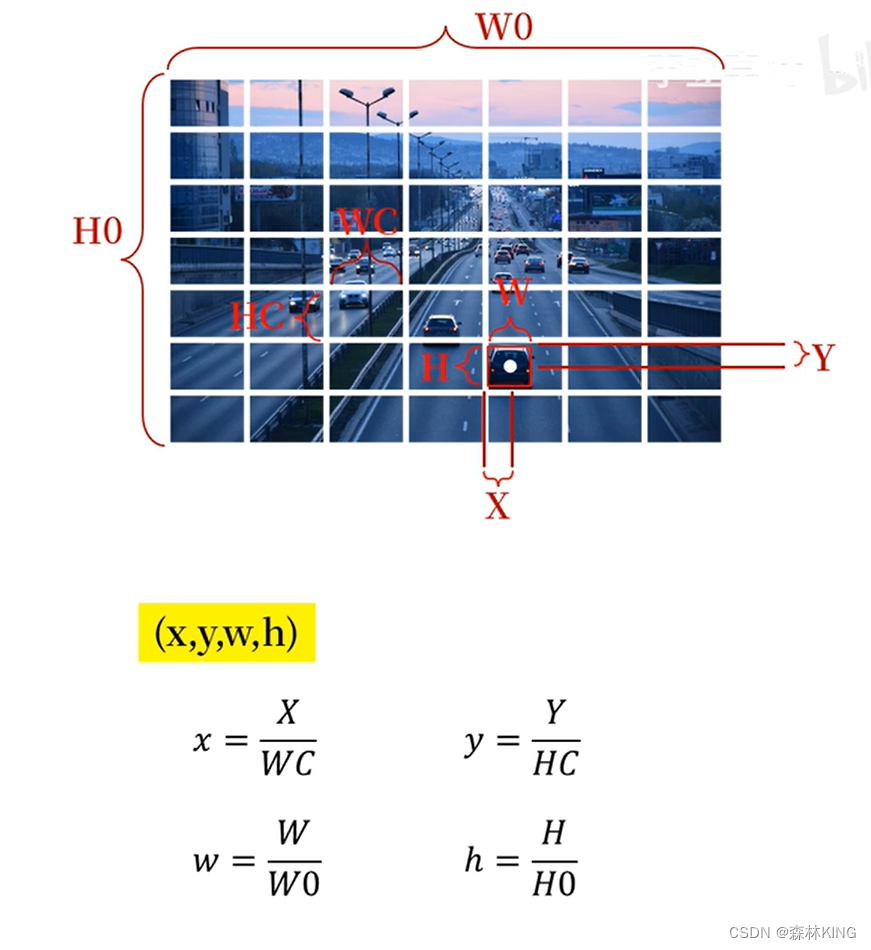
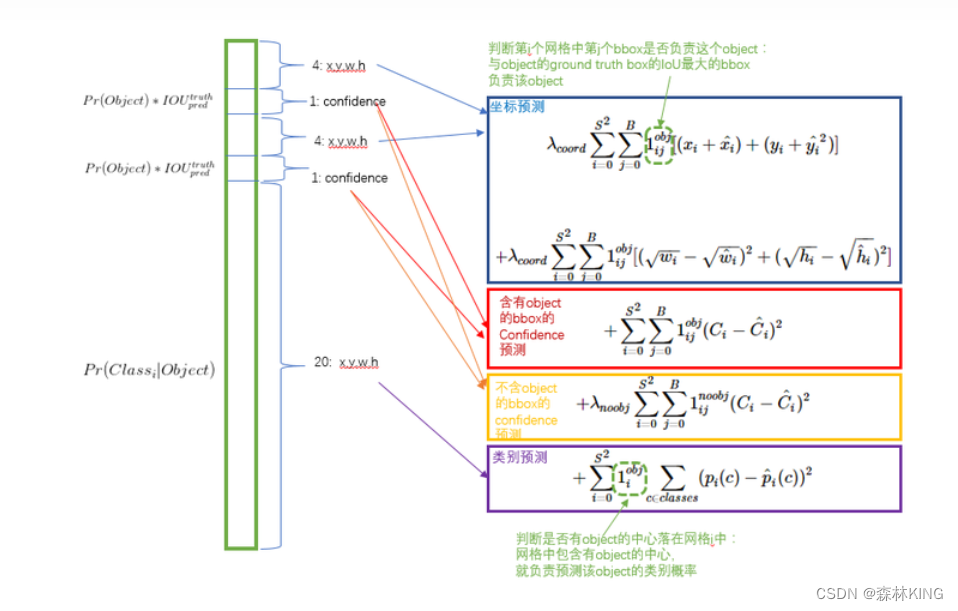
2个bounding box就是定位作用,判断定位的准确度有5个参数—x,y,w,h,c
(x,y):bounding box的中心点位置,其值相对于单元格归一
化到0·1之间。
(w,h):bounding box的宽和高,相对于整张图像归一化到0·
1之间。
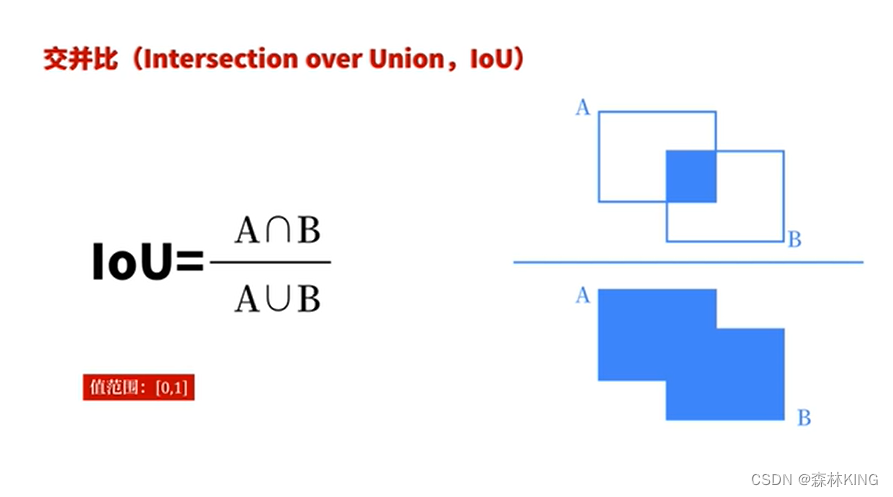
c为置信度confidence
Confidence:Pr(Object) * IOU

1、Pr(Object):
有20个目标其中一个目标即为有目标;Pr(Object)=1
2、IOU:
A为标注框;B为预测框
3、分类参数:
分类参数就是看预测框预测的目标概率,获得预测框同时进行预测目标类别;需要检测目标有20个,所以需要对每个目标给出概率;
4、总结:
参数:5+5+20
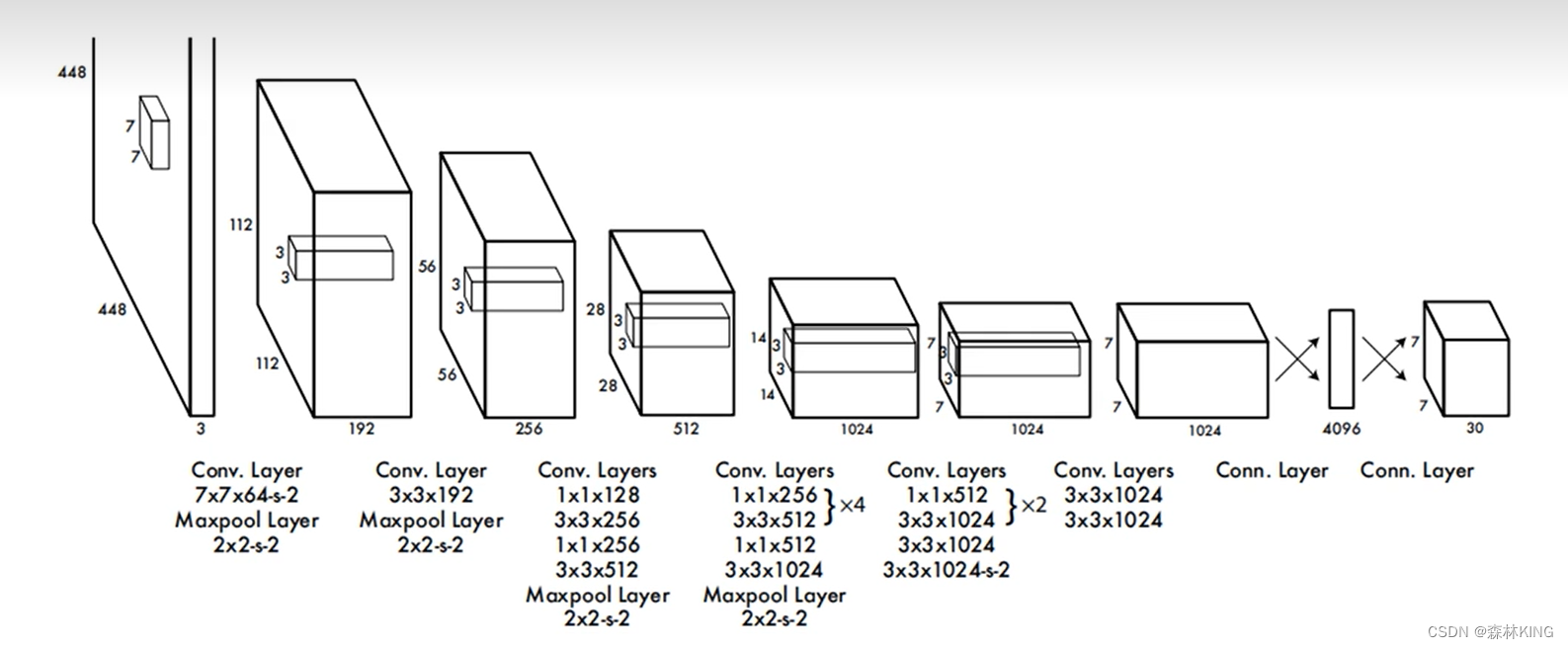
5、网络结构
二、Yolov5
YOLOv5官方代码中,给出的目标检测网络中一共有4个版本,分别是YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个模型。
1、YOLOv5s整体的网络结构图
YOLOv5s网络是YOLOv5系列中深度最小,特征图的宽度最小的网络。其他的三种都是在此基础上不断加深,不断加宽。
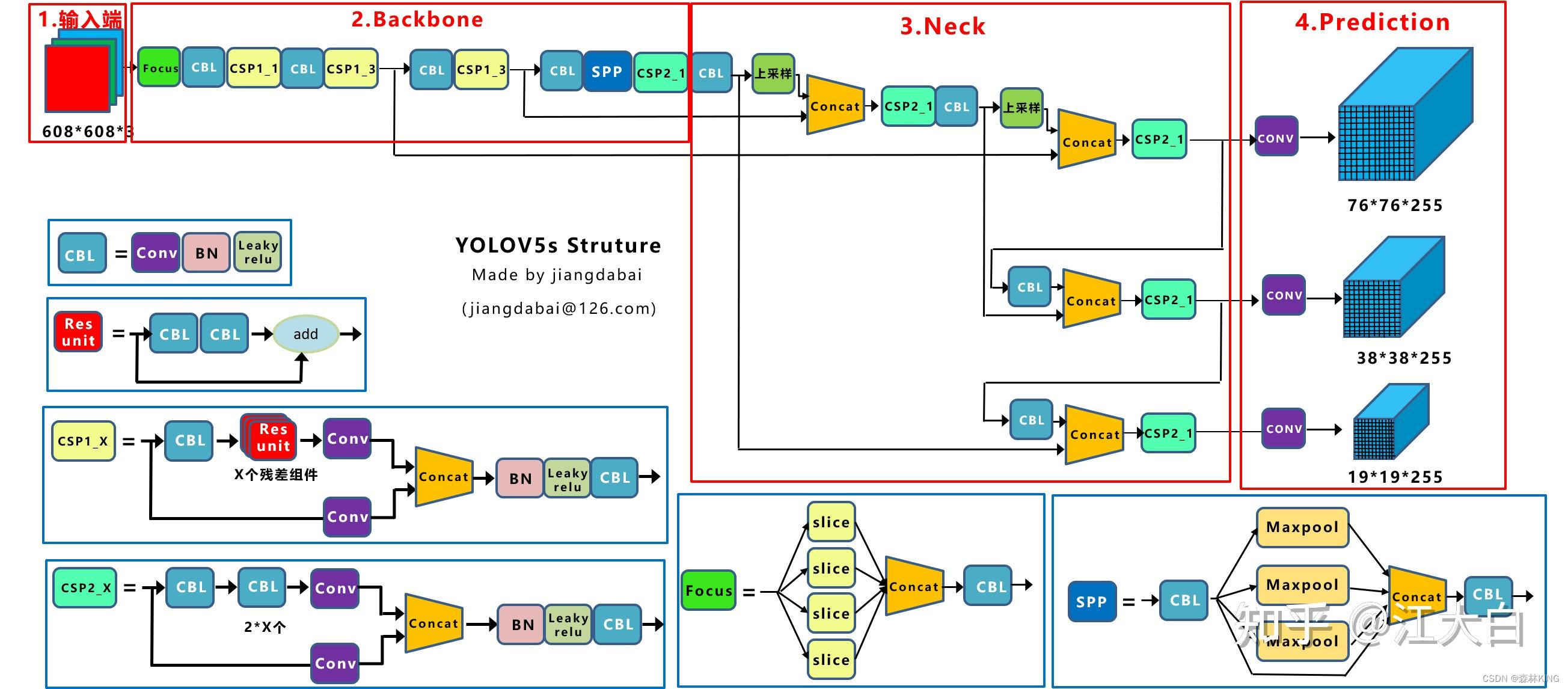
(1)输入端:MosaicQ数据增强、自适应锚框计算、自适应图片缩放
(2)Backbone:Focus结构,CSP结构
(3)Neck:FPN+PAN结构
(4)Head:CIOULoss
基本组件:
·Focus:基朩上就是YOLOv2的passthrougho
·CBL:由Conv+Bn+Leaky_relu*活函数三者组成。
·CSPI—X:借CSPNet网络结构,由三个卷积层和X个Res unint模块Concate 构成。
·CSP2—X:不再用Res unint模块而是改为CBL
·SPP:采用1×1,5x5,9×9,13×13的最大池化的方式,进行多尺度融合。
2、输入端
①MosaicQ数据增强
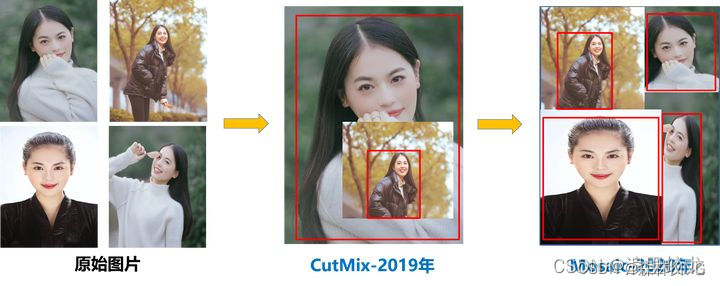
CutMix:将2张图进行拼接
Mosaic:在CutMix基础上进行改进,采用4张图片,按照随机缩放,随机裁剪和随机排布的方式进行拼接
优点:将几张图组合成一张图,不仅可以丰富数据集,极大的提升网络训练速度,降低模型内存
②自适应锚框计算
在YOLO算法中,针对不同的数据集,都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数,因此初始锚框是比较重要的一部分。
在yoloV3和yoloV4中,训练不同的数据集,都是通过单独的程序运行来获得初始锚点框。而在yoloV5中将此功能嵌入到代码中,每次训练,根据数据集的名称自适应的计算出最佳的锚点框,用户可以根据自己的需求将功能关闭或者打开,指令为:
parser.add_argument("-nuautoanchor", action='store_true', help='disable autoancher check')
# 如果需要打开,只需要在训练代码时增加'-nuautoanchor'选项即可
③自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同。填充的比较多,则存在信息冗余,影响推理速度。因此在YOLOv5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。
2、Backbone
1)Focus模块
Focus模块在YOLOv5中是图片进入Backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长得差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信忠盂失情况下的二倍下采样特征图。
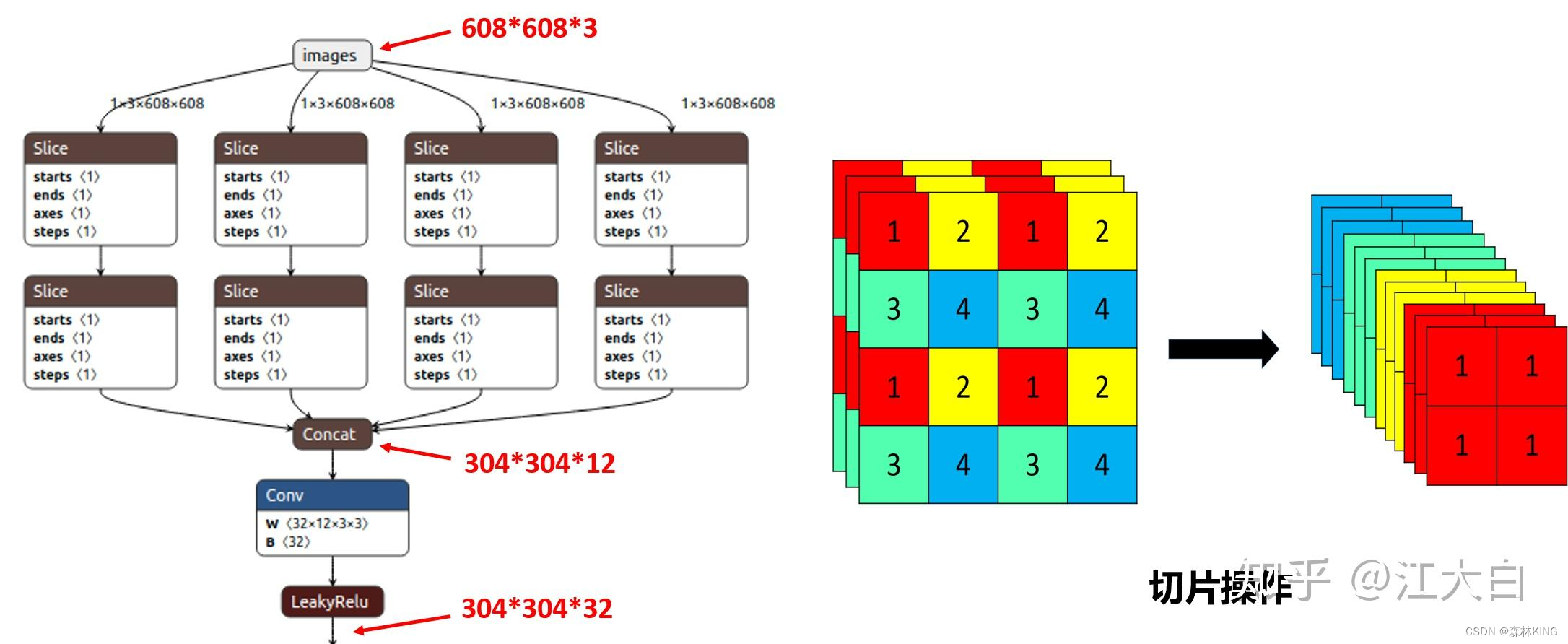
作用:可以便信息不丢失的情况下提高计算力
不足:Focus对某些设备不支持且不友好,开销很大,另夕卜切片对不齐的话模型就崩了。
后期改进:在新版中,YOLOv5%Focus模块替换成了一个6x6的卷积层。两者的计算量是等价的,但是对于一些GPU设备,便用6x6的卷积会更加高效。
2)CSP结构
而Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
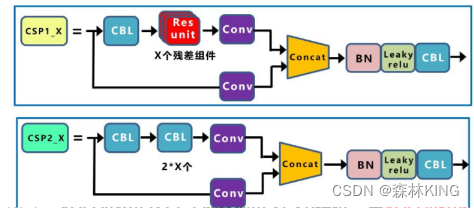
CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。
3、Neck
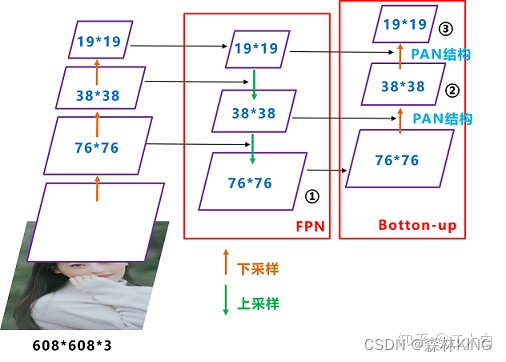
Yolov5现在的Neck和Yolov4中一样,都采用FPN+PAN的结构
3、输出端
Yolov5中采用其中的GIOU_Loss做Bounding box的损失函数。
1)IOU_Loss
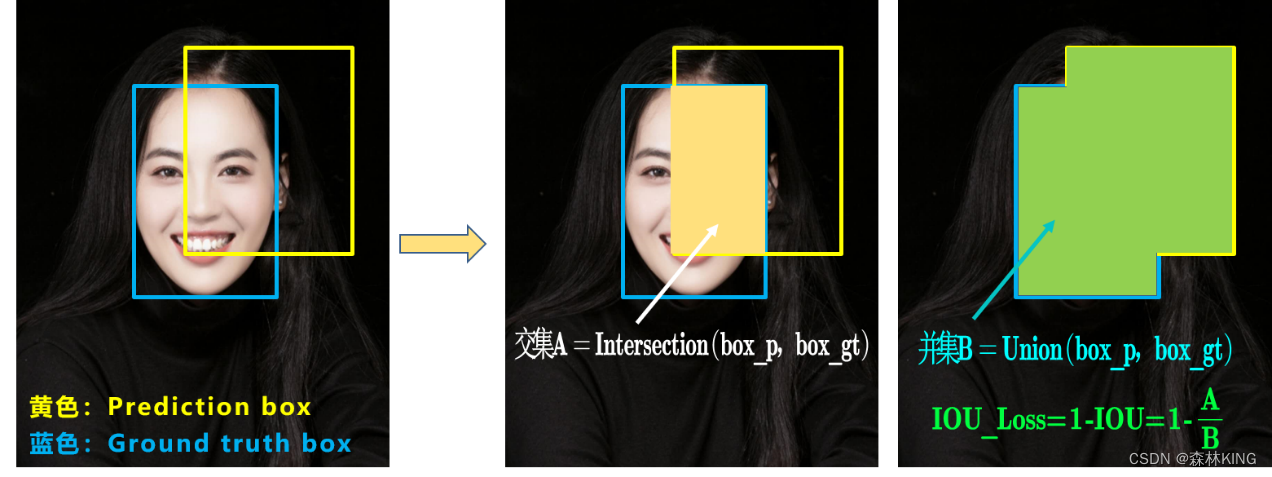
可以看到IOU的loss其实很简单,主要是交集/并集,但其实也存在两个问题。

**问题1:**即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。
**问题2:**即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同
因此2019年出现了GIOU_Loss来进行改进。
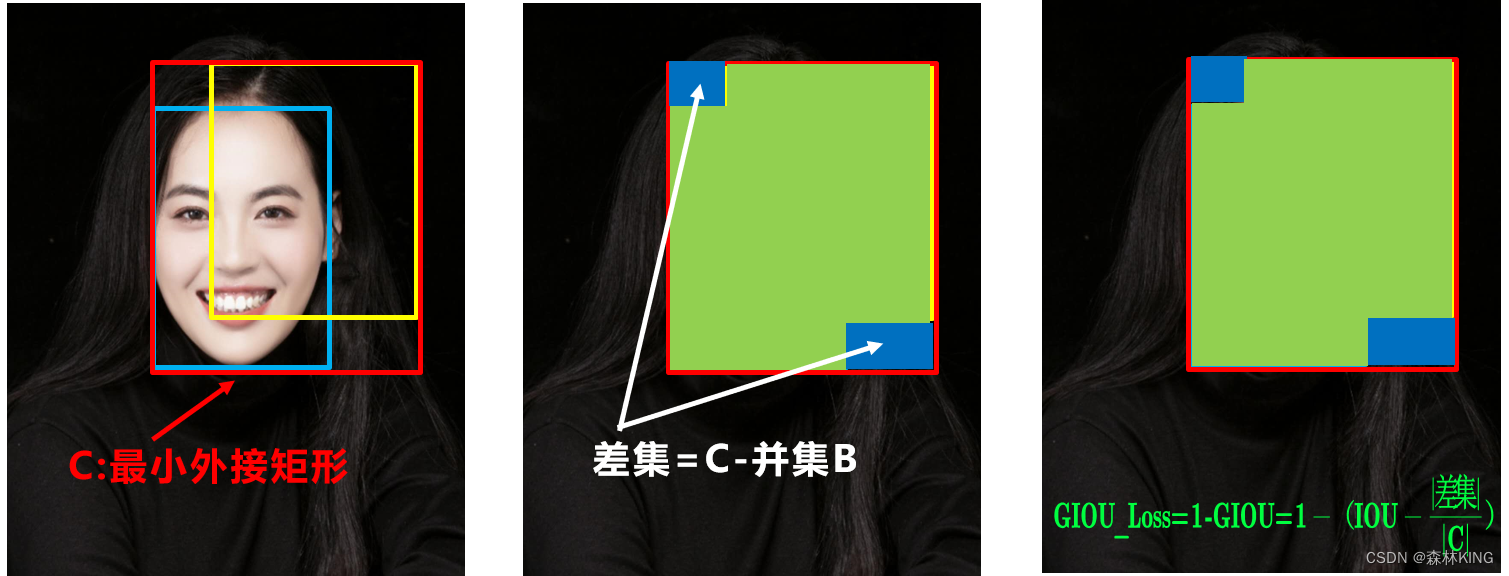

C是包含A和B的最小的面积。
可以看到上图GIOU_Loss中,增加了相交尺度的衡量方式,缓解了单纯IOU_Loss时的尴尬。
目标检测任务的损失函数一般由分类损失函数和回归损失函数构成,回归损失函数的发展过程主要包括:最原始的Smooth L1 Loss函数、2016年提出的IoU Loss、2019年提出的GIoU Loss、2020年提出的DIoU Loss和最新的CIoU Loss函数。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









