






为什么需要微调数据集?
大型预训练语言模型(如GPT、BERT等)通常是在通用语料库上进行预训练的,这些语料库可能涵盖广泛的领域,但未必包含足够的特定领域数据。将领域文献批量转换为可供模型微调的数据集是一种常见的做法,尤其是在需要构建特定领域的语言模型或解决特定任务时。这种转换的核心目的是让模型能够更好地理解和处理与该领域相关的内容。
那么怎么基于特定的领域文献来合成数据集呢?
此时请出我们的大神Code秘密花园,作者通过三天时间完成了整个项目的构建和部署,但是前一段时间只支持本地部署,对于代码基础不是很强的小伙伴来说还是有点头疼,但是好消息是,作者通过后期维护发布可以直接下载安装的APP,使用起来就更加方便了!!!
下面是easydataset的GitHub项目链接:
https://github.com/ConardLi/easy-dataset?tab=readme-ov-file
这里有作者的相关公众号二维码等等联系方式,宝藏博主欢迎大家关注!

那么接下来就说说这个怎么用吧!
下载安装
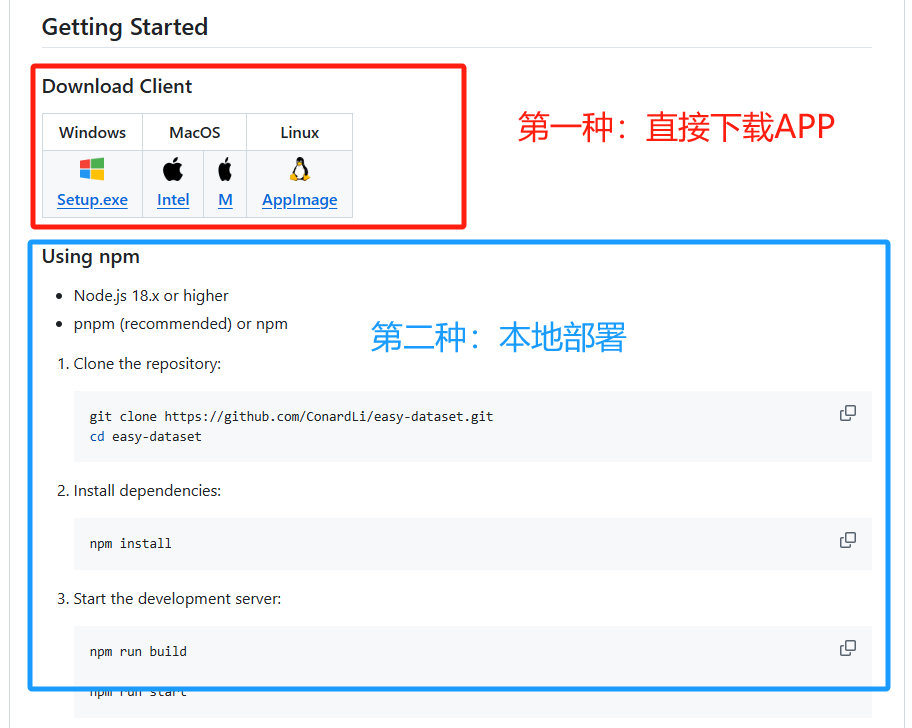
第一种方式较为简单直接下载安装使用即可

第二种是本地部署,适合有代码基础或者特殊需求需要修改源码的
如果有需要大家可以去看博主的视频
如何把领域文献批量转换为可供模型微调的数据集?_哔哩哔哩_bilibili
使用方式
1、搜索公开数据集模块
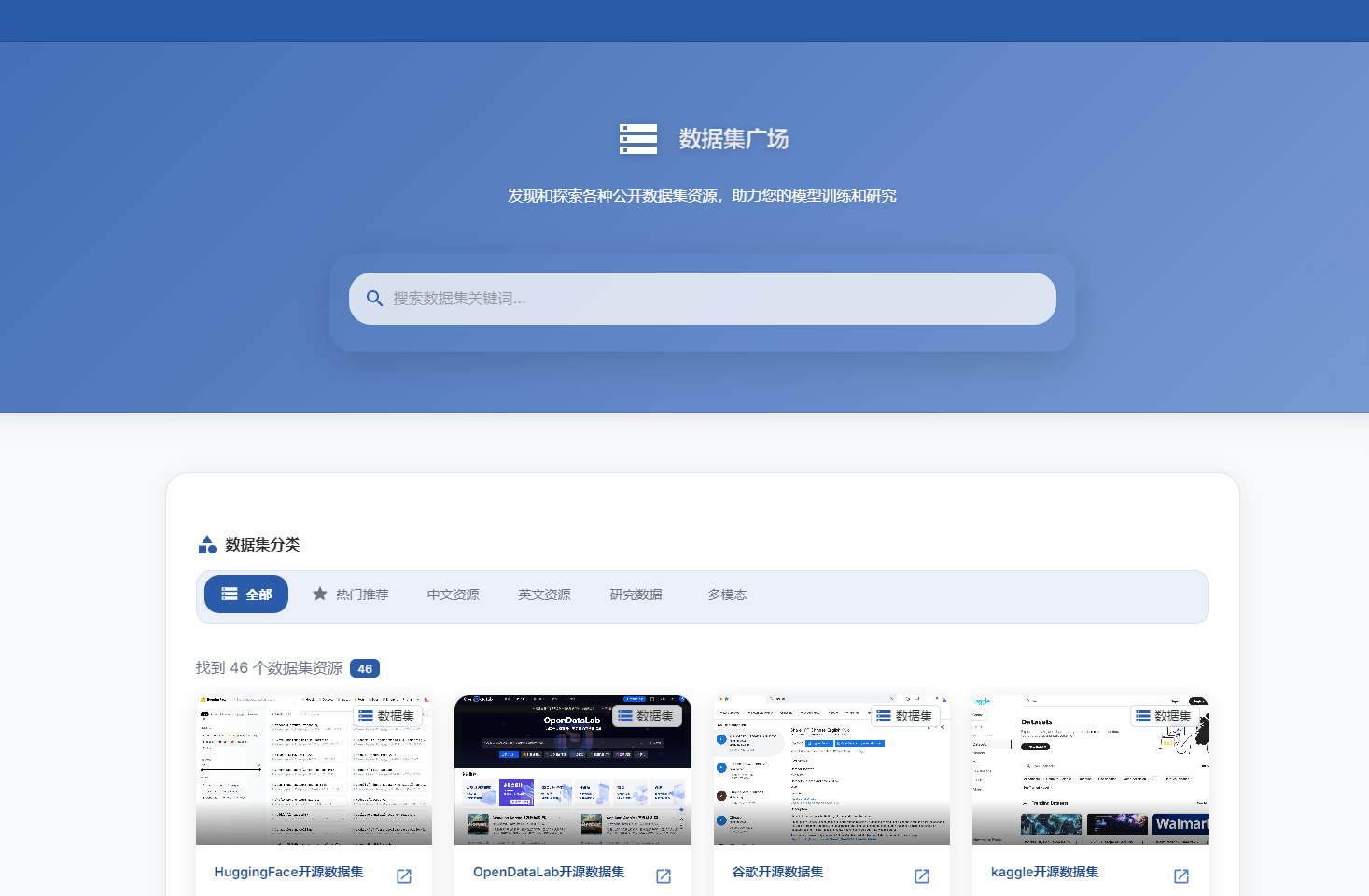
只需要在这里搜索输入关键字就可以在多个平台上进行检索
2、创建项目生成数据集
模型配置
首先项目是最小的工作单元,大家可已通过创建项目,创建新的项目需要名称和描述,名字和描述只用来记录和查看,不会影响后续数据集的生成。
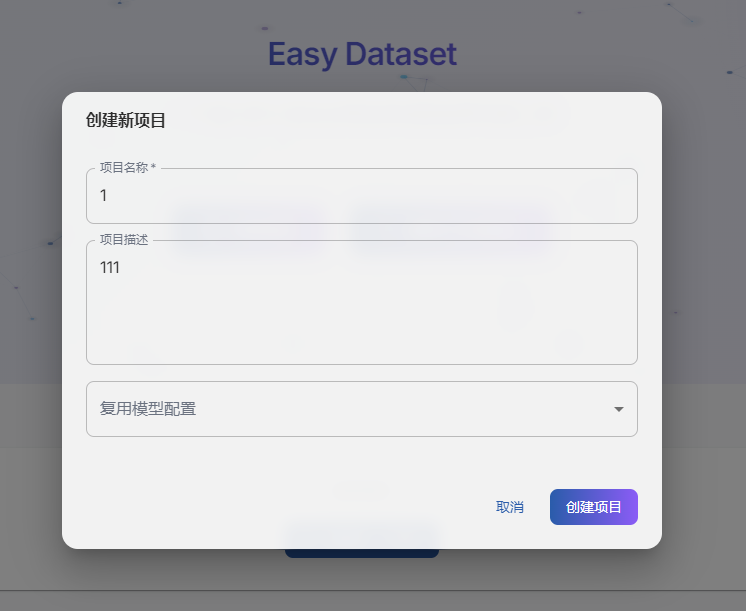
创建完了项目就会来到项目设置-模型配置这里,在这里配置后续生成数据集的模型
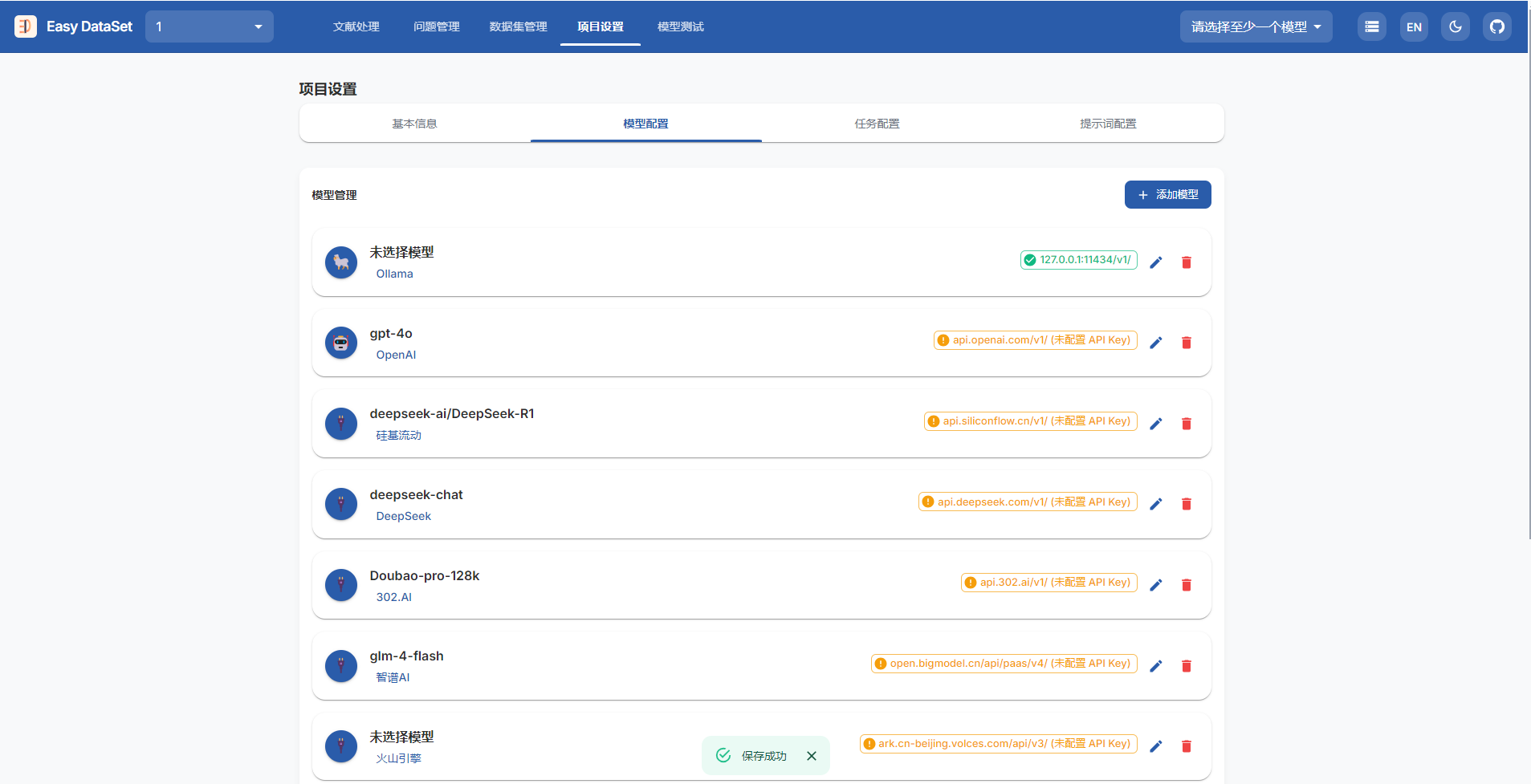
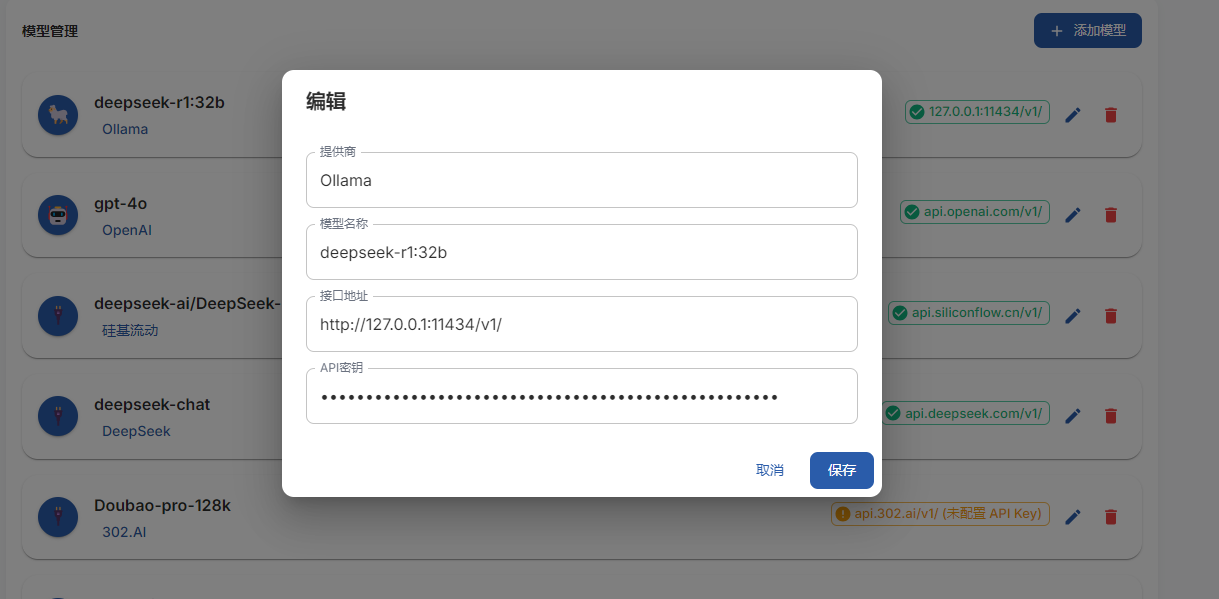
如果还不会申请APIkey的小伙伴可以参考下面这个博主的文章整理的很详细
DeepSeekAPI Key获取方法及使用教程_deepseek api key-CSDN博客
模型测试
在这里可以选择你配置好的模型然后进行测试,如果能正常返回就可以,大家也可以多试两个模型对比一下,选择速度最快的模型。
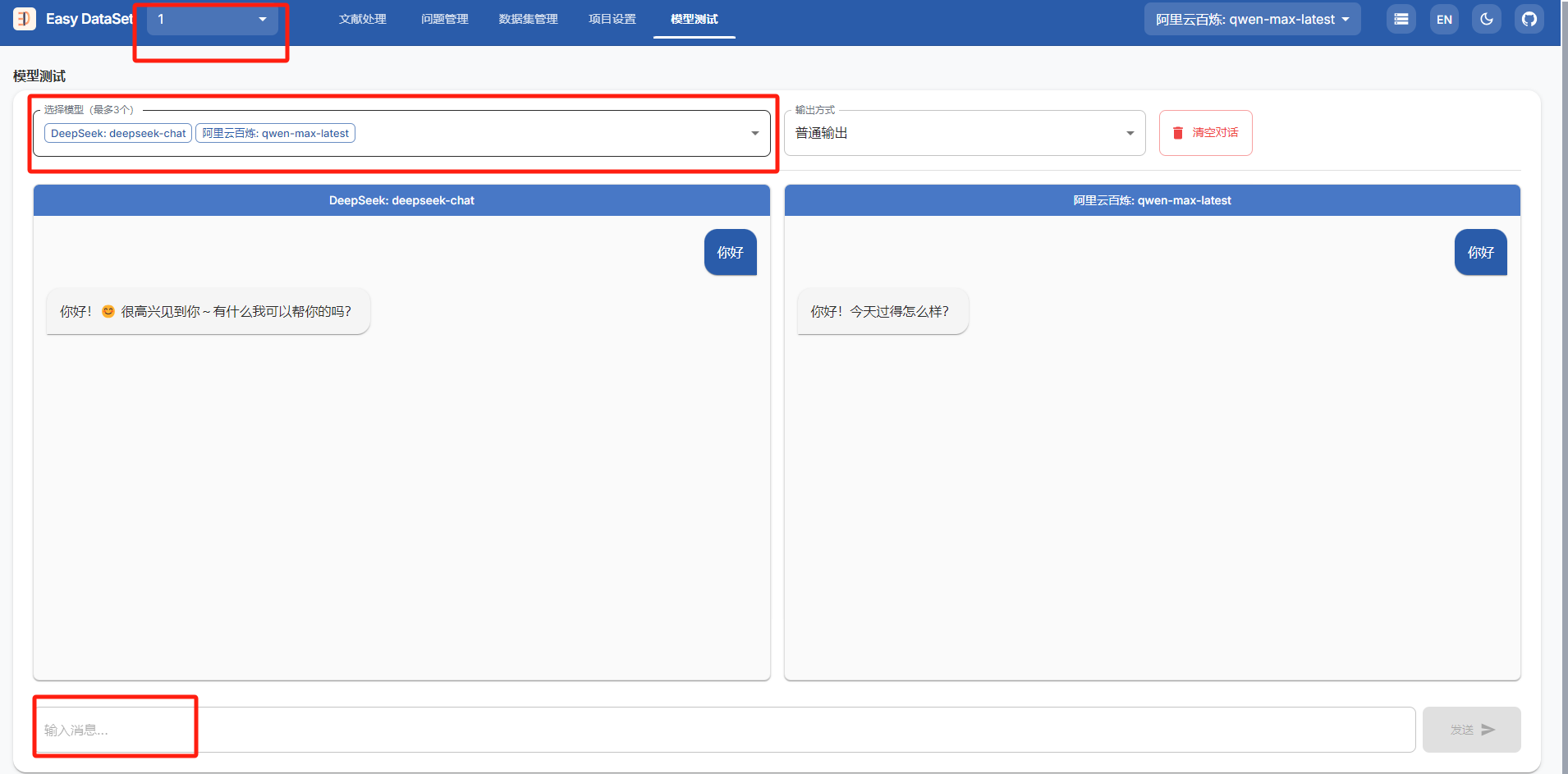
如果这一步没有问题就可以进行下一步了
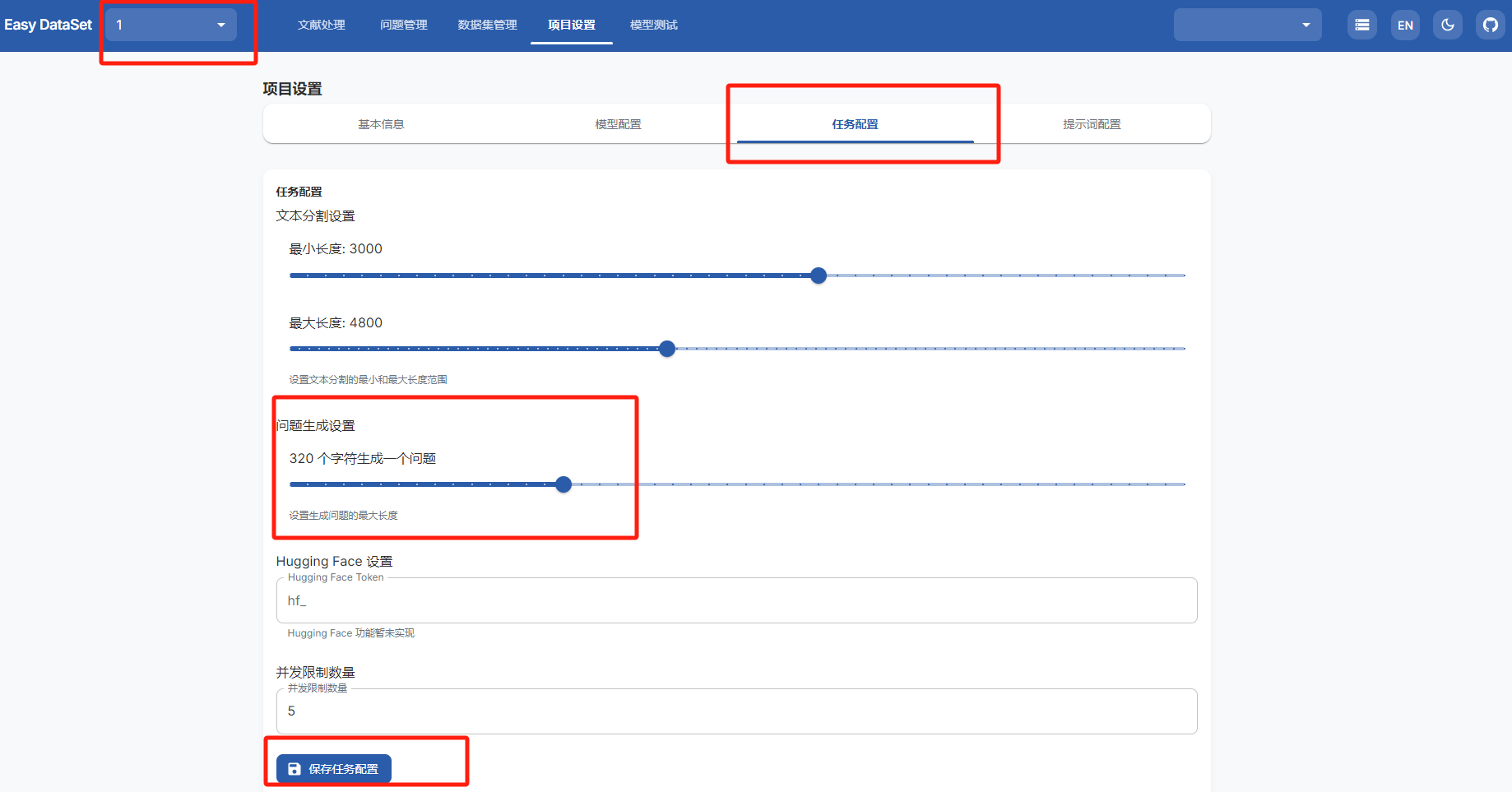
就是确认项目,然后确认文本分割块的大小,以及多少个字符生成一个问题
最后不要忘了保存设置
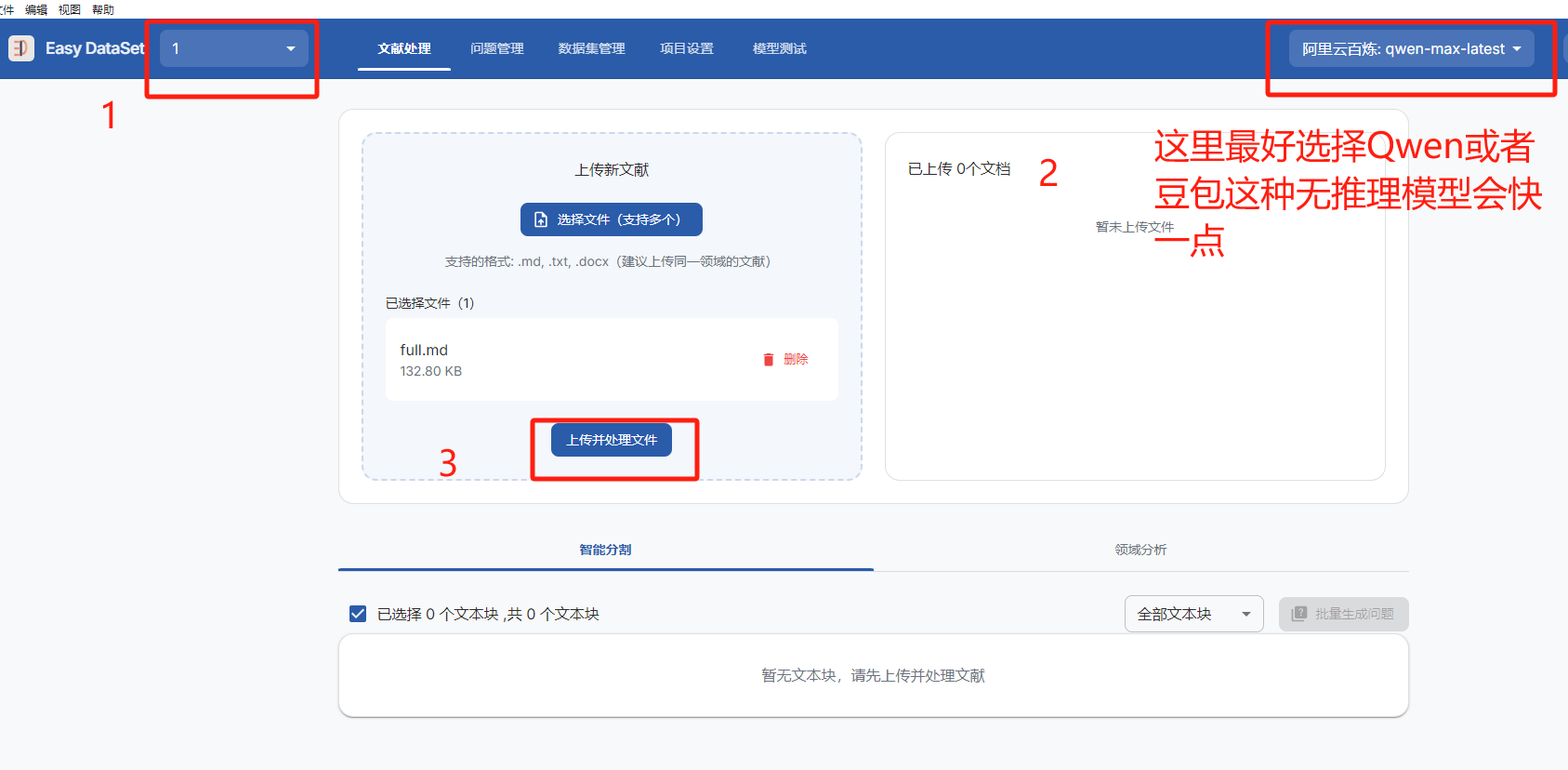
3、文献处理模块
目前呢是支持上传markdown、txt、docx格式的文献,所以如果文献是pdf格式的可以使用其他转换为markdown格式等可上传的格式,这里推荐使用一个软件叫MinerU,可以下载客户端非常方便
然后就是上传文献了
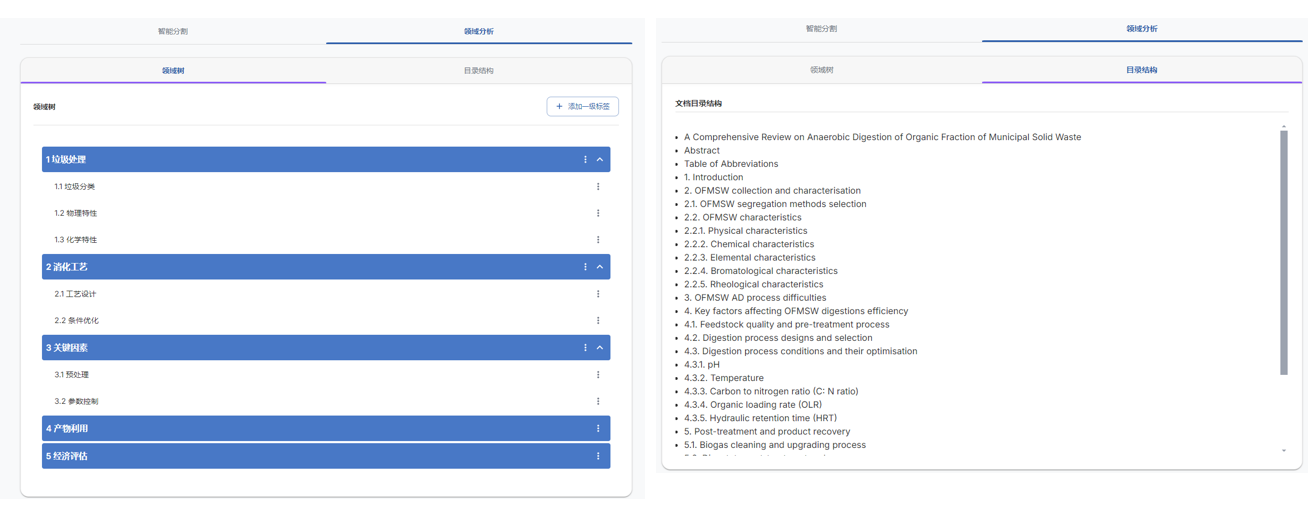
处理完就可以看到分割的文本块,以及领域分析里生成的领域树还有根据文献提出来的目录结构
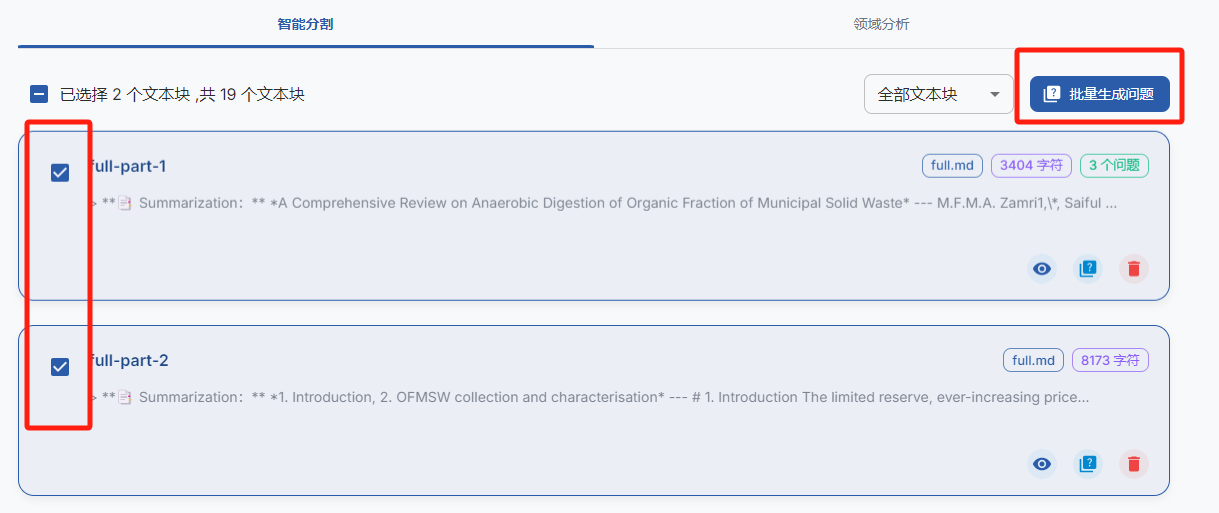
然后就到了最关键的生成问题

还有一个更方便好用的就是批量生成问题
下一步进入问题管理页面
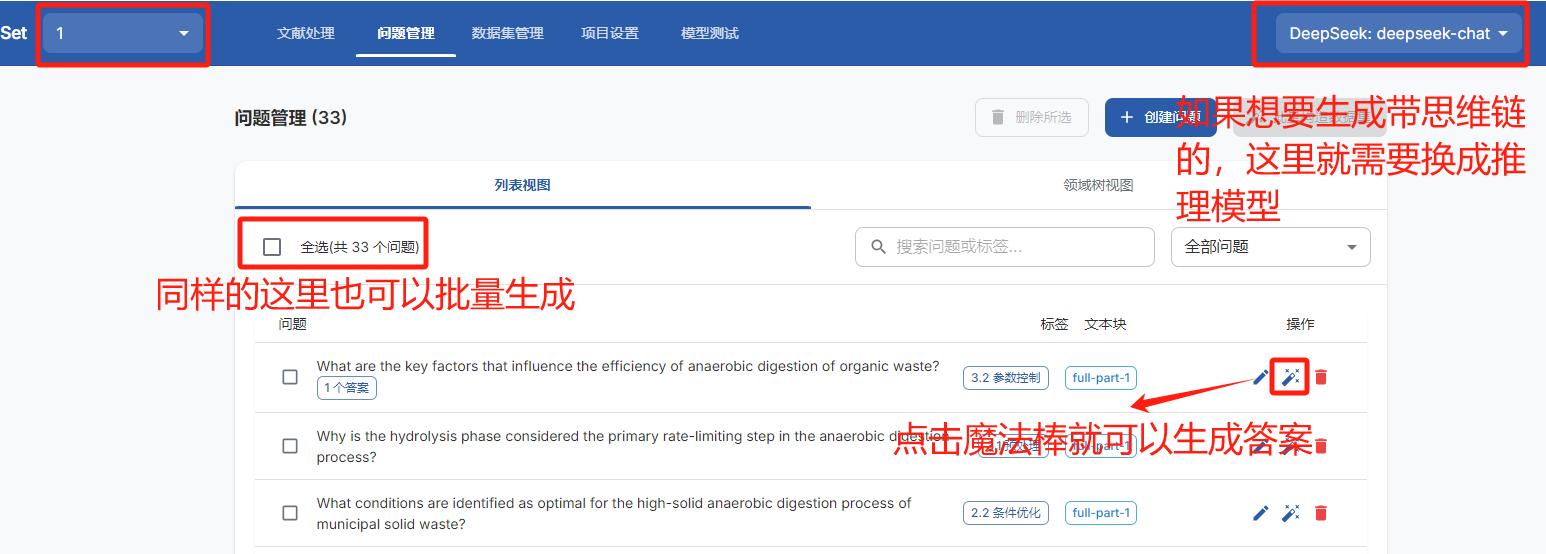
然后就是数据集管理,这里可以看到问题回答以及标签还有使用的模型和是否有思维链,如果不满意的详情里可以修改或者删除
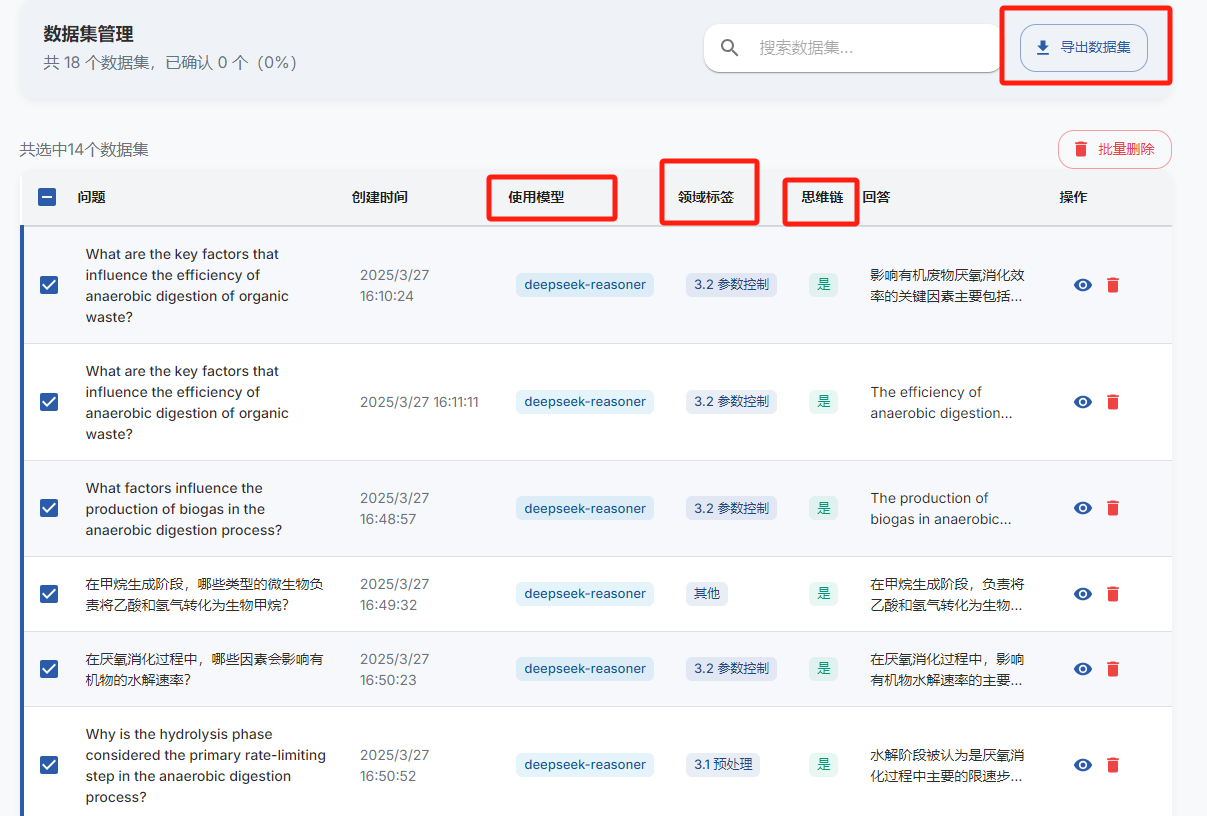
最后就是批量导出了
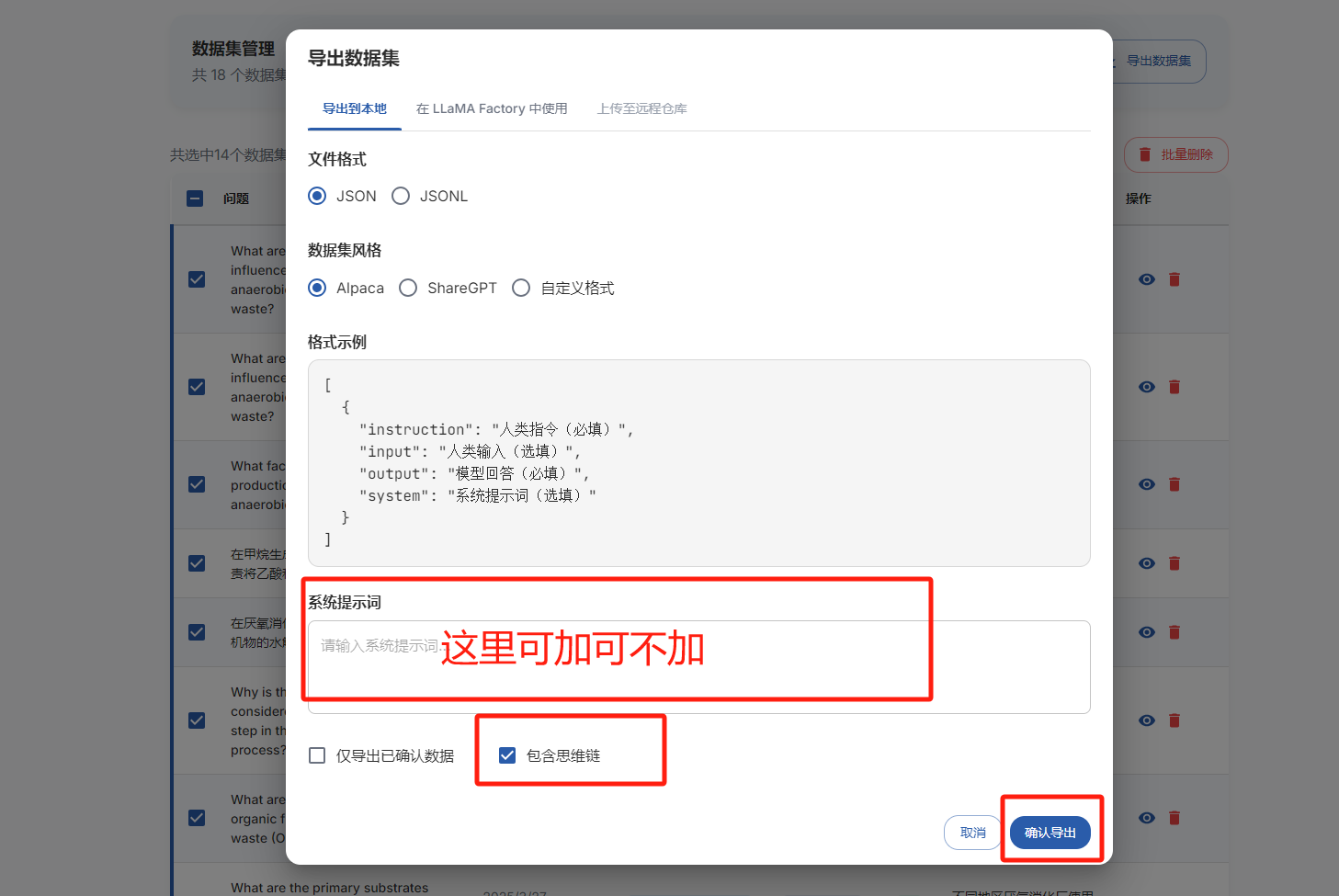
大家可以看看生成的数据的样子!

然后你就拥有可以微调模型的数据啦!

















 26万+
26万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









