







1.数据集格式:
一般进行大模型数据集准备时常用的两种数据集格式:ALpaca和shareGPT
ALpaca:
[
{
"instruction": "user instruction (required)",
"input": "user input (optional)",
"output": "model response (required)",
"system": "system prompt (optional)",
"history": [
["user instruction in the first round (optional)", "model response in the first round (optional)"],
["user instruction in the second round (optional)", "model response in the second round (optional)"]
]
}
]shareGPT:
{
"conversations": [
{
"role": "user",
"content": "What is the capital of France?"
},
{
"role": "assistant",
"content": "The capital of France is Paris."
},
{
"role": "user",
"content": "Can you tell me more about Paris?"
},
{
"role": "assistant",
"content": "Paris is the largest city and the capital of France. It is known for its art, culture, and history..."
}
]
}2.数据集标注
在数据集标注这里,我比较推荐 easy-dataset这个开源项目的使用,可以通过github仓库去部署,也可以直接下载安装包进行安装,目前该项目仅仅支持markdown格式的文本,此时自己的文本可以通过百度去搜索在线转换的工具,转换成markdown格式的文本。准备好资料后,启动easy-dataset
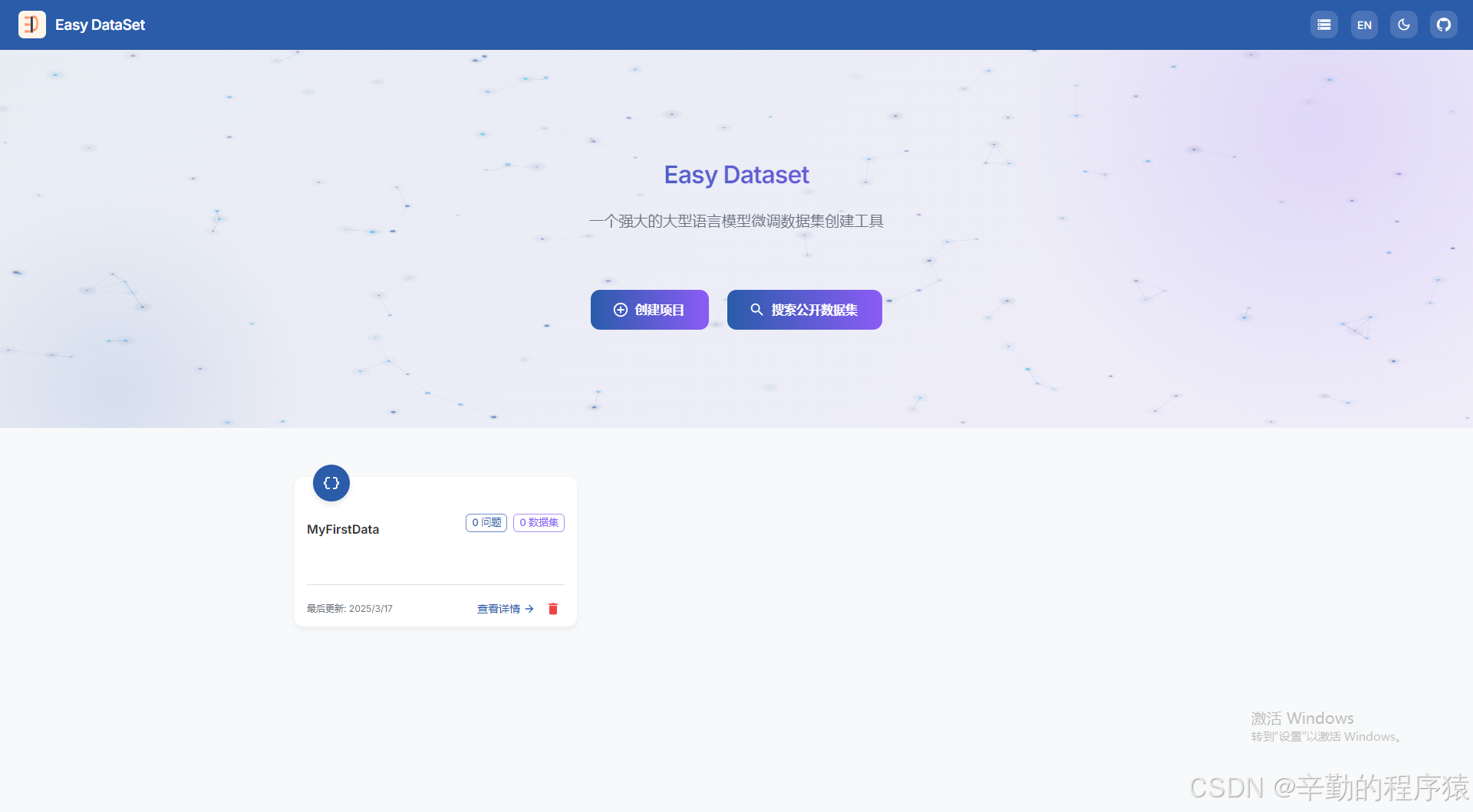
此时可以通过创建项目,创建一个项目,也可以直接搜索公开的数据集,我们这里使用创建新建的项目。
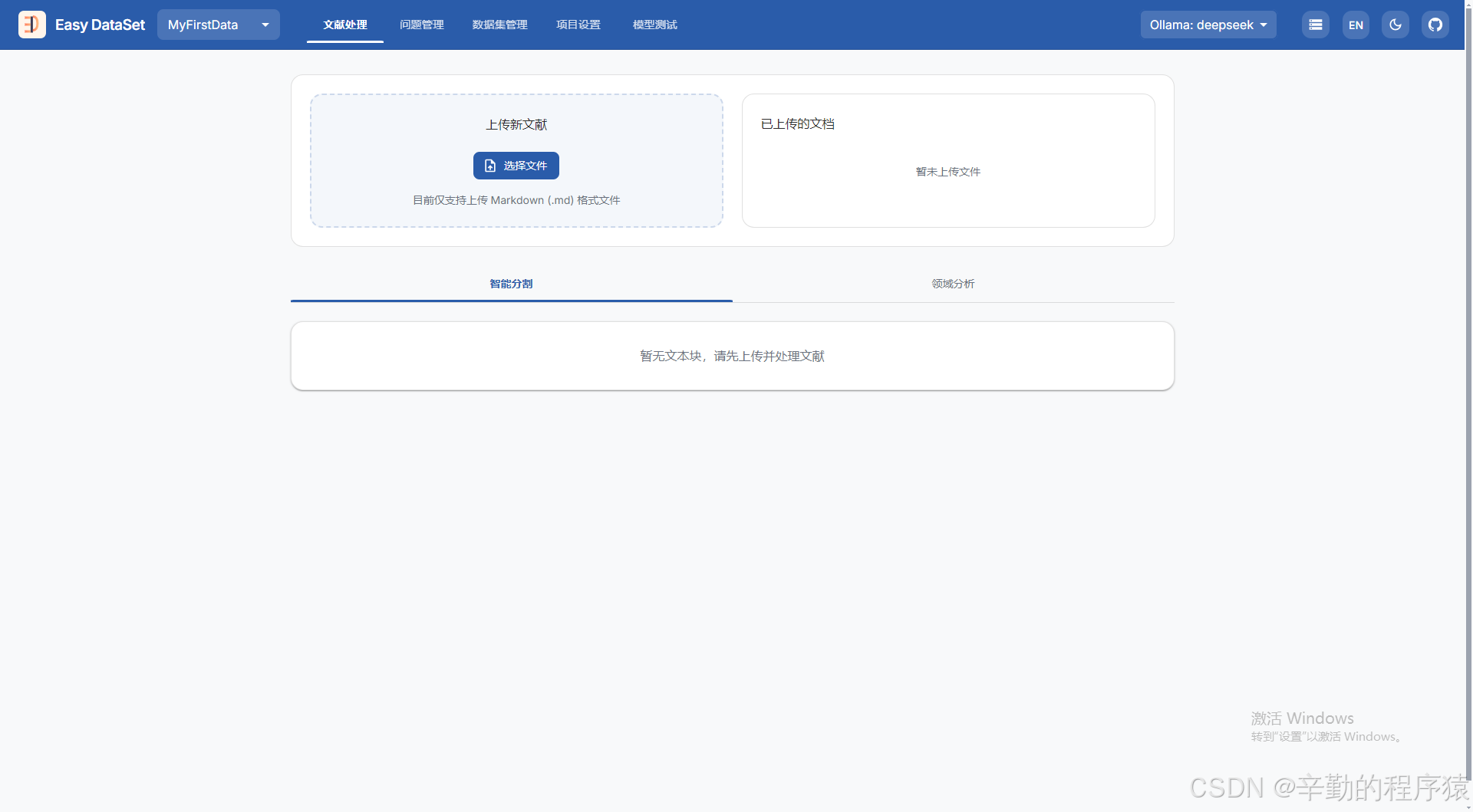
创建完一般是如上图所示,注意一定要引入一个大模型,通过现有的大模型进行文本的分析拆分等。
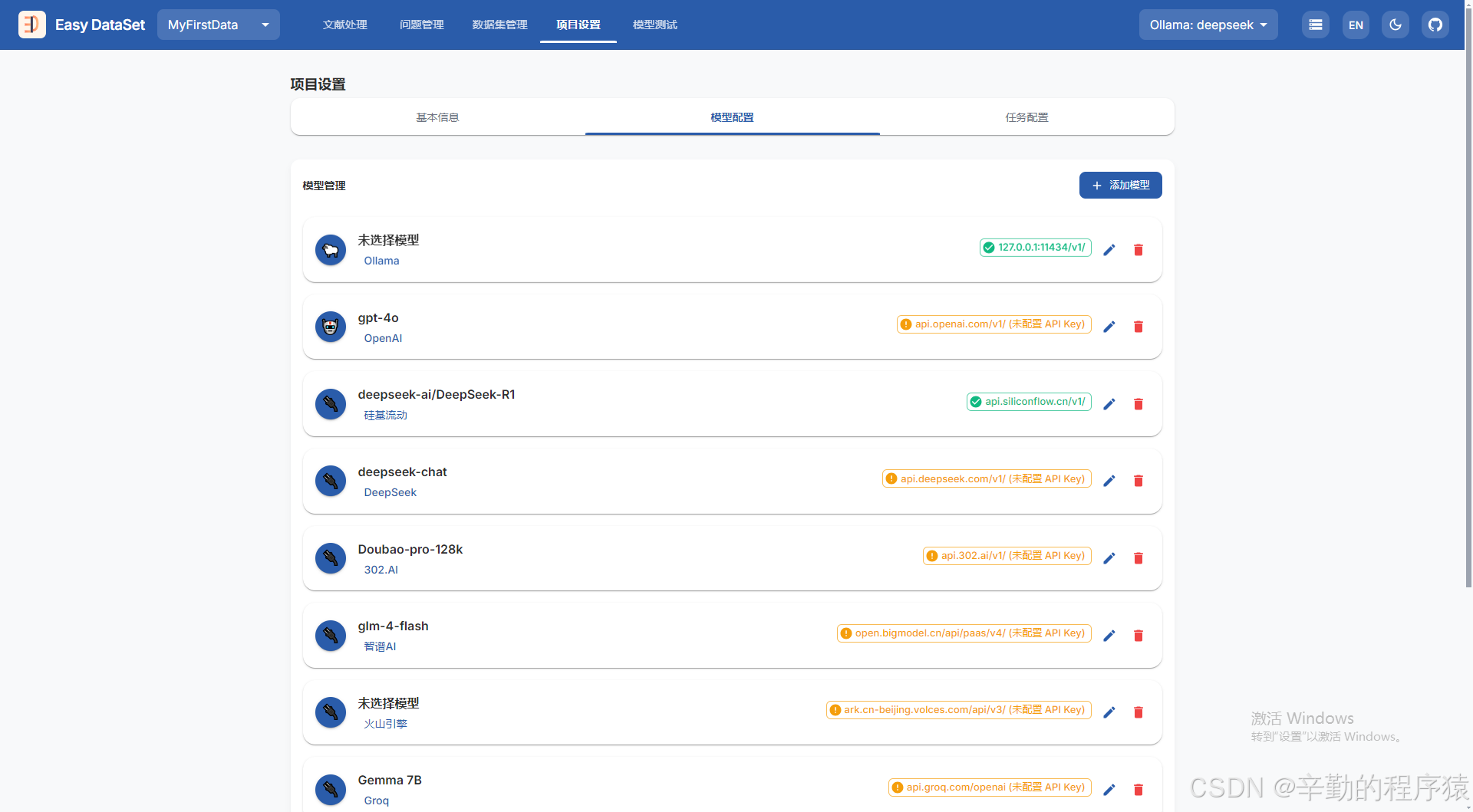
可以在上图所示的位置进行大模型api配置,其中这里推荐一个平台获取Deepseek-R1免费5百万token的api,注册链接:https://cloud.lanyun.net/#/registerPage?promoterCode=0005,注册完进入后访问MaaS平台 | GPU智算云平台文档中心去查看如何使用api。
3.微调训练
工具:LLama Factory、modelscope、transformer、huggingface、unsloth
微调方式:指令性微调,对话性微调,适应性微调,推理性微调,强化学习微调,蒸馏微调
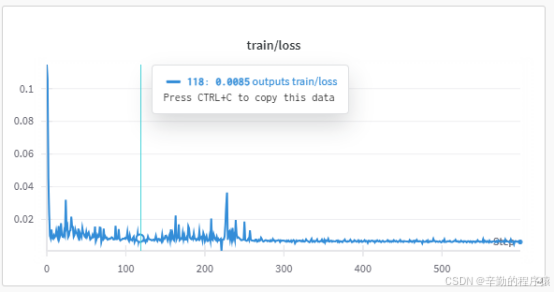
这里我们使用单机单卡进行微调训练,并采用指令性微调,我们采用unsloth进行微调,缺点时仅支持单卡,如果需要多卡训练建议采用LLama Factory。


















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









