








目录
ECA是通道注意力机制的一种实现形式,是基于SE的扩展。
作者认为SE block的两个FC层之间的降维是不利于channel attention的权重学习的,并且捕获所有通道之间的依存关系是效率不高且是不必要的。权重学习的过程应该直接一一对应。
ECA 注意力机制模块直接在全局平均池化层之后使用1x1卷积层,去除了全连接层。该模块避免了维度缩减,并有效捕获了跨通道交互。并且ECA只涉及少数参数就能达到很好的效果。
ECA通过一维卷积 layers.Conv1D 来完成跨通道间的信息交互,卷积核的大小通过一个函数来自适应变化,使得通道数较大的层可以更多地进行跨通道交互。
⭐欢迎大家订阅我的专栏一起学习⭐
🚀🚀🚀订阅专栏,更新及时查看不迷路🚀🚀🚀
YOLOv5涨点专栏:http://t.csdnimg.cn/CNQ32YOLOv8涨点专栏:http://t.csdnimg.cn/tnoL5
YOLOv7专栏:http://t.csdnimg.cn/HsyvQ
💡魔改网络、复现论文、优化创新💡
最近,通道注意力机制已被证明在提高深度卷积神经网络(CNN)性能方面具有巨大潜力。然而,大多数现有方法致力于开发更复杂的注意力模块以实现更好的性能,这不可避免地增加了模型的复杂性。为了克服性能和复杂性权衡的悖论,(ECA)模块一种高效通道注意,该模块仅涉及少量参数,同时带来了明显的性能增益。通过剖析 SENet 中的通道注意力模块,凭经验证明避免降维对于学习通道注意力非常重要,适当的跨通道交互可以保持性能,同时显着降低模型复杂性。因此,一种无需降维的局部跨通道交互策略,可以通过一维卷积有效实现。此外,一种自适应选择一维卷积核大小的方法,确定局部跨通道交互的覆盖范围。ECA 模块高效且有效,
原理简介
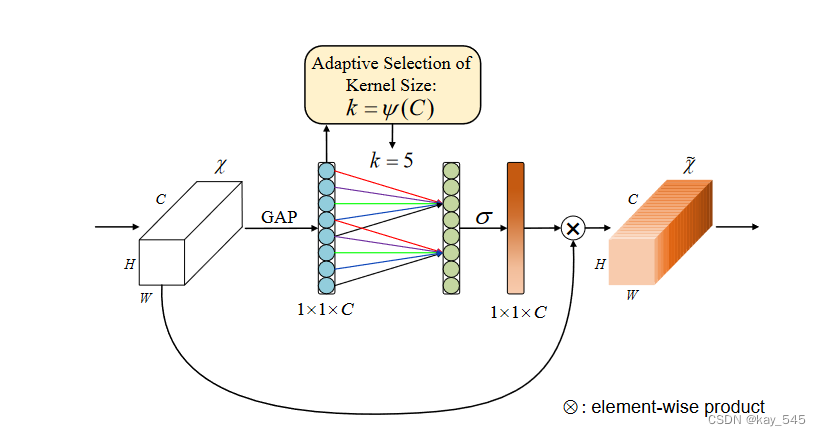
给定通过全局平均池化 (GAP) 获得的聚合特征,ECA 通过执行大小为 k 的快速一维卷积来生成通道权重,其中 k 通过通道维度 C 的映射自适应确定。
首先回顾 SENet 中的通道注意模块(即 SE 块)。然后,我们通过分析降维和跨渠道交互的影响,对 SE 区块进行实证诊断。这促使我们提出 ECA 模块。此外,一种自适应确定 ECA 参数的方法,并最终展示如何将其应用于深度 CNN。
在重新审视SE块之后,进行了实证比较,分析通道降维和跨通道交互对通道注意力学习的影响。根据这些分析,提出了高效的通道注意力(ECA)模块。
为了验证其效果,我们将原始 SE 块与其三个变体(即 SE-Var1、SE-Var2 和 SEVar3)进行比较,所有变体均不执行降维。结果表明通道注意力有能力提高深度CNN的性能。同时,SE-Var2独立学习每个通道的权重,在涉及的参数较少的情况下略优于SE块。这可能表明通道及其权重需要直接对应,同时避免降维比考虑非线性通道依赖性更重要。此外,采用单个 FC 层的 SEVar3 的性能优于在 SE 块中进行降维的两个 FC 层。所有上述结果都清楚地表明,避免降维有助于学习有效的通道注意力。因此,我们开发了没有通道降维的 ECA 模块。
代码实现
class ECAAttention(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, c1, k_size=3):
super(ECAAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)我们专注于学习模型复杂度较低的深度 CNN 的有效通道注意力。为此,我们提出了一种高效的通道注意力(ECA)模块,它通过快速一维卷积生成通道注意力,其内核大小可以通过通道维度的非线性映射自适应地确定。实验结果表明,我们的 ECA 是一种极其轻量级的即插即用模块,可提高各种深度 CNN 架构的性能,包括广泛使用的 ResNet 和轻量级 MobileNetV2。此外,我们的 ECA-Net 在对象检测和实例分割任务中表现出良好的泛化能力。将来,我们将把我们的 ECA 模块应用到更多的 CNN 架构中(例如 ResNeXt 和 Inception),并进一步研究 ECA 与空间注意力模块的结合。
yaml文件实现(tips:可以添加不同的位置)
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 24
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 29-P4/16
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 37
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 42-P5/32
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 50
[-1, 1, ECAAttention, [1024]],
]
# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 51
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[37, 1, Conv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 63
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[24, 1, Conv, [128, 1, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]], # 75
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 63], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 88
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 51], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-2, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 101
[-1, 1, ECAAttention, [512]],
[75, 1, RepConv, [256, 3, 1]],
[88, 1, RepConv, [512, 3, 1]],
[101, 1, RepConv, [1024, 3, 1]],
[[104,105,106], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
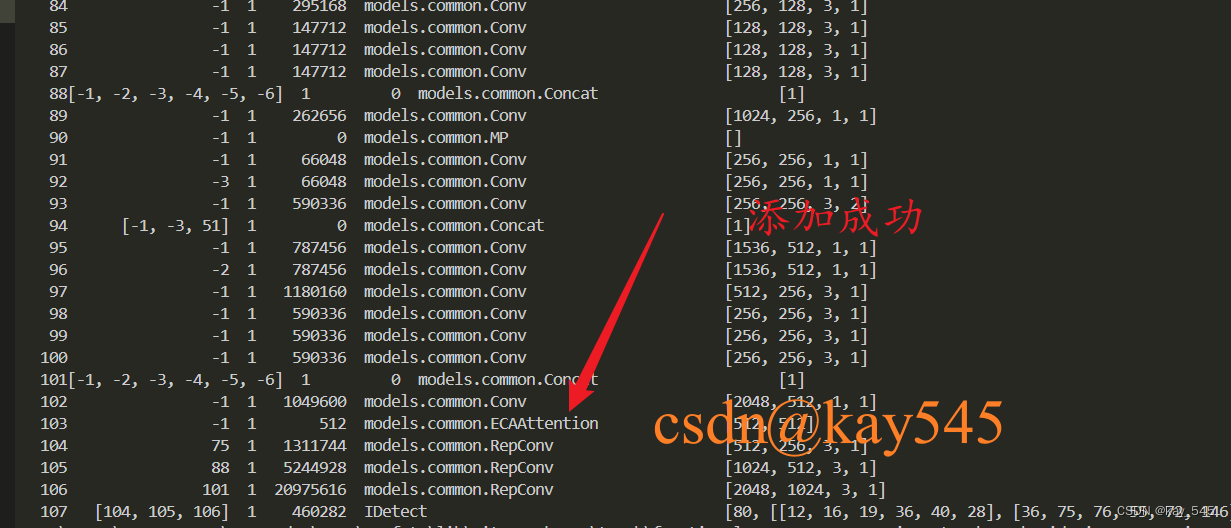
检查是否添加执行成功
出现下图所示的网络结构,则说明添加成功
完整代码分享
https://pan.baidu.com/s/19zHFv0vail_GtinyP7KAgQ?pwd=begm提取码: begm
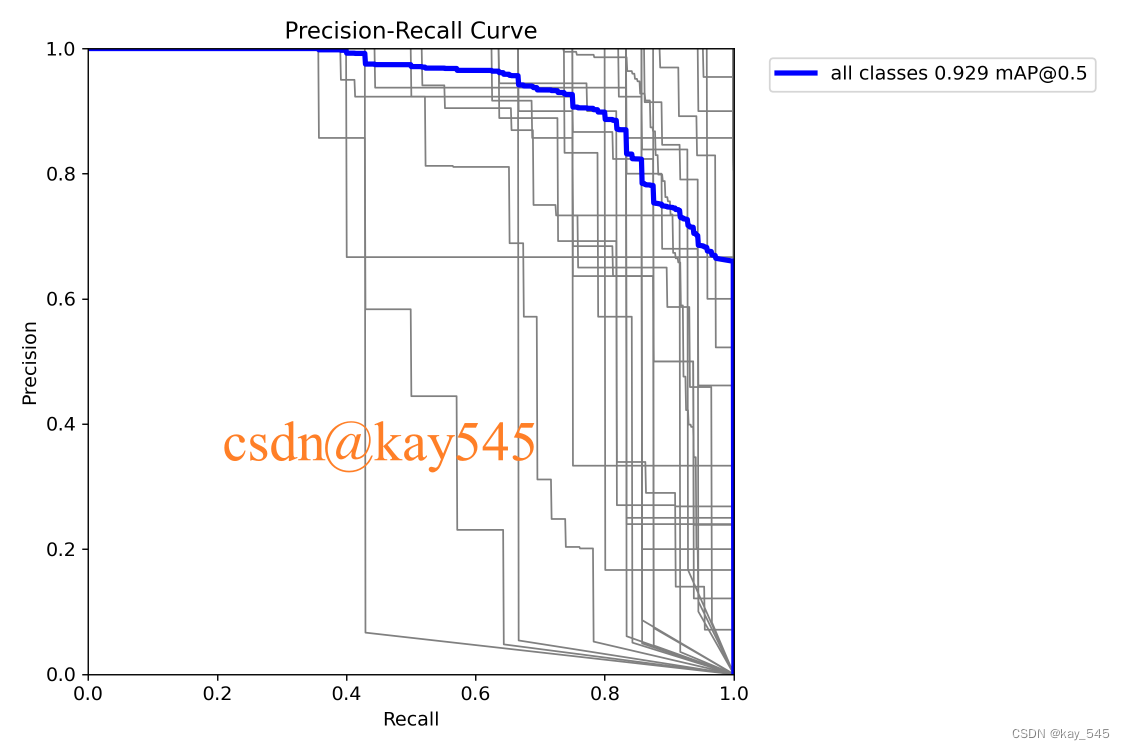
论文创新必备(可帮忙做实验)

启动命令
python train.py --weight --cfg ./path/yolov7.yaml # yolov7的yaml文件修改了网络结构,其他的未修改,可以自行尝试
















 4475
4475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











