







注:数据集描述
| 变量 | 中文翻译 | 变量解释 |
|---|---|---|
| dt | 订单创建时间 | 顾客创建订单时间(以天为单位) |
| order_id | 订单id | 顾客创建订单id |
| waybill_id | 运货单id | 骑手接受订单生成的运货单id |
| courier_id | 骑手id | 骑手id |
| da_id | 地区id | 商业区id |
| is_courier_grabbed | 骑手是否接受了订单 | 骑手是否接受了订单 |
| is_weekend | 下单时间是否为周末 | 下单时间是否为周末 |
| estimate_arrived_time | 预计到达时间 | 餐品预计到达顾客所在位置的时间 |
| is_prebook | 该订单是否为预定订单 | 该订单是否为预定订单 |
| poi_id | 商家id | 商家id |
| sender_lng | 商家所在位置经度 | 商家所在位置经度 |
| sender_lat | 商家所在位置维度 | 商家所在位置维度 |
| recipient_lng | 顾客所在位置经度 | 顾客所在位置经度 |
| recipient_lat | 顾客所在位置维度 | 顾客所在位置维度 |
| grab_lng | 骑手所在位置经度 | 骑手未取餐前所在位置经度 |
| grab_lat | 骑手所在位置维度 | 骑手未取餐所在位置维度 |
| dispatch_time | 系统分配订单时间 | 订单进入分配系统的时间 |
| grab_time | 骑手接受订单时间 | 骑手接受订单时间 |
| fetch_time | 骑手取餐时间 | 骑手取餐时间 |
| arrive_time | 餐品到达时间 | 餐品实际达到顾客所在位置时间 |
| estimate_meal_prepare_time | 预计备餐时间 | 商家预计备餐时间 |
| order_push_time | 订单推送时间 | 将运单分配给快递员的时间(快递员可以拒绝派遣) |
| platform_order_time | 平台订单创建时间 | 平台订单创建时间(以小时为单位) |
该数据集可以分为离散型变量、时间型变量和经纬度型变量,在描述性统计中,我们对离散型数据进行频数分析,对时间性数据进行集中趋势、离散趋势和分布形态分析,对经纬度型数据通过聚类方法,对数据进行分析。
import pandas as pd
import matplotlib.pylab as plt
from pyl7vp import L7VP
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
from matplotlib.cm import ScalarMappable
from IPython.display import Image
from sklearn.cluster import KMeans一、时间型变量
(一)集中趋势
关于集中趋势,我们可以通过中位数指标,众数指标进行分析。在本数据集的时间型变量中,结合下面的研究内容,我们只对['platform_order_time'],即平台创建订单时间绘制直方图,进行集中趋势分析。
注:该数据集中的数据既有已接单订单的数据,又有未接单订单的数据。我们在下述的分析中,将数据集中未结单数据排除,支队已接单数据进行分析。
#导入数据
df = pd.read_csv('Meituan-INFORMS-TSL-Research-Challenge-main/Meituan-INFORMS-TSL-Research-Challenge-main/all_waybill_info_meituan_0322.csv/all_waybill_info_meituan_0322.csv',encoding='utf-8')
#df['platform_order_time'] = pd.to_datetime(df['platform_order_time'], unit='s')
after_df=df[df['is_courier_grabbed'] != 0].copy()
next_df = df[df['is_courier_grabbed'] != 0].copy()
after_df['platform_order_time'] = pd.to_datetime(after_df['platform_order_time'],unit='s')# 提取订单时间的小时部分
order_hour = after_df['platform_order_time'].dt.hour
# 统计每个小时的订单数量
hourly_order_count = order_hour.value_counts().sort_index()
# 绘制直方图
plt.bar(hourly_order_count.index, hourly_order_count.values)
plt.xlabel('Hour of the day')
plt.ylabel('Order count')
plt.title('Order count by hour')
# 设置 x 轴刻度标签为时:00:00
plt.xticks(hourly_order_count.index, [f"{hour}:00:00" for hour in hourly_order_count.index], rotation=90)
plt.show()运行结果:
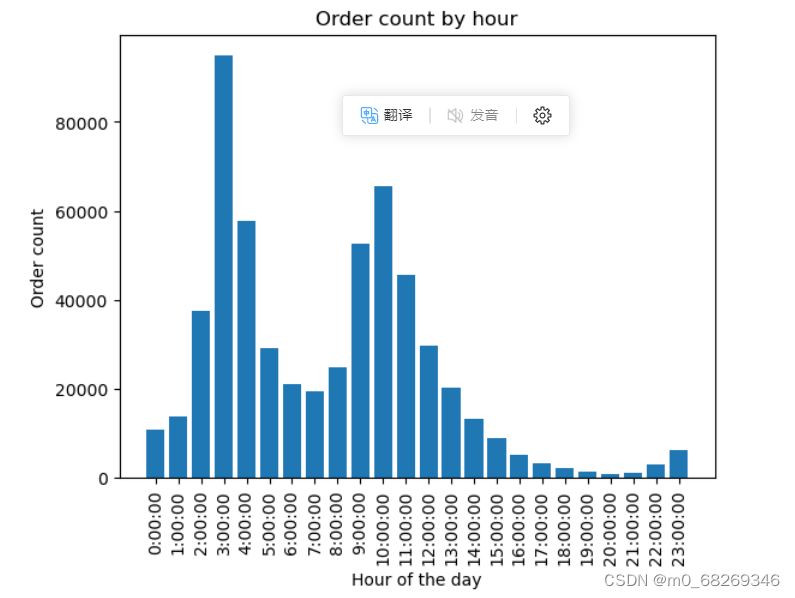
#计算时间的平均数
mean_value = next_df['platform_order_time'].mean()
mean_value = round(mean_value, 2) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1967
1967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









