







✨ 前言 ✨
💥本专栏旨在为初学者和希望深化理解的技术从业人员提供一个系统的深度学习知识平台。深度学习是机器学习的重要分支,近年来在计算机视觉、自然语言处理、语音识别等领域取得了显著成就。通过本专栏,读者将能够掌握深度学习的基本概念、算法、技术及其应用。💥
💥项目环境:💥
python: 3.8.18
torch 2.0.1
torchvision 0.15.2
torchviz 0.0.2
scikit-learn 1.3.2
numpy 1.24.4
pandas 2.0.3
matplotlib 3.5.1
🎉目录🎉
📌前言
🚀一、什么是xlstm神经网络✈️
🚀xLSTM 架构✈️
🚀sLSTM✈️
🚀mLSTM✈️
🚀二、导包✈️
🚀三、下载数据集✈️
🚀四、构建xLSTM模型✈️
🚀五、完整代码✈️
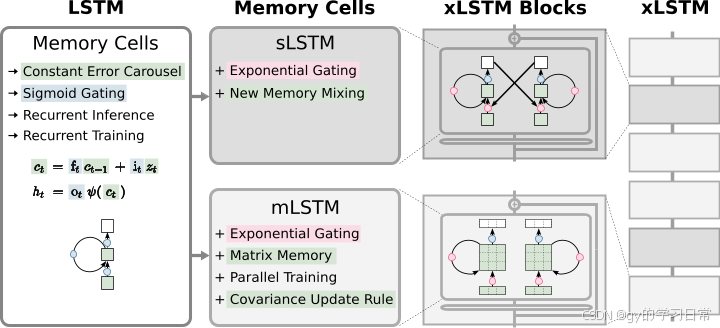
💫一、什么是xlstm神经网络💫
🙏X-LSTM(扩展长短期记忆网络)是一种改进的LSTM(长短期记忆网络)架构,旨在更好地处理时间序列数据和捕捉长期依赖关系。与传统LSTM相比,X-LSTM在门控机制和记忆单元方面进行了调整,使其具备更强的模型表现力和泛化能力。🙏
💫xLSTM 架构💫
🌟🌟xLSTM 的核心是对传统 LSTM 框架的两项主要修改:指数门控和新颖的记忆结构。这些增强引入了两种新的 LSTM 变体,即 sLSTM (标量 LSTM)和 mLSTM (矩阵 LSTM。🌟🌟
💫sLSTM💫
☀️指数化门控:sLSTM 为输入和遗忘门引入了指数激活函数,从而实现对信息流更加灵活的控制。归一化与稳定性:为了防止数值不稳定,sLSTM 引入了一个归一化状态,该状态跟踪输入门和未来遗忘门的积。
内存混合:sLSTM 支持多个内存单元,并允许通过递归连接进行内存混合,从而提取复杂模式和状态跟踪能力。☀️
💫mLSTM💫
☀️矩阵记忆:mLSTM 使用矩阵记忆代替标量记忆单元,增加了存储容量,并提高了信息检索效率。
协方差更新规则:mLSTM 借鉴双向联想记忆(BAM)的灵感,采用协方差更新规则来高效地存储和检索键-值对。
并行化:通过放弃内存混合,mLSTM 实现了完全并行化,使其在现代硬件加速器上能够高效计算。
这两个变种,sLSTM 和 mLSTM,可以集成到残差块架构中,形成 xLSTM 块。通过残差堆叠这些 xLSTM 块,研究人员可以建立强大的 xLSTM 架构,以针对特定任务和应用领域。☀️
💫 二、导包💫
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import swanlab
from copy import deepcopy as dc
import os
from model import Model, LSTMModel
from data import get_dataset
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import numpy as np
💫三、下载数据集💫
💥我们使用的数据集为Google股价数据集,Google股价数据集通常是包含一段时间内Google公司股票价格的详细数据集合。这些数据通常包含股票的买卖价格、买卖数量、时间戳以及股票价格的开盘价、最高价、最低价和收盘价等信息。这些数据对于财务分析师、投资者以及研究人员来说非常有价值,他们可以利用这些数据来研究股价趋势、进行市场分析和制定投资策略。💥
💥下载数据集的方式是前往Kaggle💥
四、构建xLSTM模型
模型框架如下:
这里我们使用了一个简单的模型可以参考其他文章:
💥五、完整代码💥
✨ model.py代码如下:✨
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self, num_heads, layers, input_size=1, hidden_size=64, fc1_size=32, fc2_size=16, fc3_size=8
,output_size=1):
super(Model, self).__init__()
self.num_heads = num_heads
self.layers = layers
self.xLSTM1 = xLSTM(self.num_heads, self.layers, input_size, hidden_size,
)
self.xLSTM2 = xLSTM(self.num_heads, self.layers, hidden_size, fc1_size)
self.fc1 = nn.Linear(fc1_size*hidden_size, fc2_size)
self.fc2 = nn.Linear(fc2_size, fc3_size)
self.fc3 = nn.Linear(fc3_size, output_size)
def forward(self, x):
x = self.xLSTM1(x)
output = self.xLSTM2(x)
# Apply non-linear activations
output = F.relu(self.fc1(output[:, -1, :]))
output = F.relu(self.fc2(output))
output = self.fc3(
output) # It's often a good idea to leave the last layer without non-linearity for regression tasks
return output
class xLSTM(nn.Module):
def __init__(self, num_heads, layers, input_size, output,
hidden_size=64,
batch_first=True, proj_factor_slstm=4 / 3,
proj_factor_mlstm=2):
super(xLSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_heads = num_heads
self.layers = layers
self.num_layers = len(layers)
self.batch_first = batch_first
self.proj_factor_slstm = proj_factor_slstm
self.proj_factor_mlstm = proj_factor_mlstm
self.layers = nn.ModuleList()
self.fc1 = nn.Linear(input_size, output)
for layer_type in layers:
if layer_type == 's':
layer = sLSTMBlock(input_size, hidden_size, num_heads, proj_factor_slstm)
elif layer_type == 'm':
layer = mLSTMBlock(input_size, hidden_size, num_heads, proj_factor_mlstm)
else:
raise ValueError(f"Invalid layer type: {layer_type}. Choose 's' for sLSTM or 'm' for mLSTM.")
self.layers.append(layer)
def forward(self, x, state=None):
assert x.ndim == 3
if self.batch_first: x = x.transpose(0, 1)
seq_len, batch_size, _ = x.size()
if state is not None:
state = torch.stack(list(state))
assert state.ndim == 4
num_hidden, state_num_layers, state_batch_size, state_input_size = state.size()
assert num_hidden == 4
assert state_num_layers == self.num_layers
assert state_batch_size == batch_size
assert state_input_size == self.input_size
state = state.transpose(0, 1)
else:
state = torch.zeros(self.num_layers, 4, batch_size, self.hidden_size)
output = []
for t in range(seq_len):
x_t = x[t]
for layer in range(self.num_layers):
x_t, state_tuple = self.layers[layer](x_t, tuple(state[layer].clone()))
state[layer] = torch.stack(list(state_tuple))
output.append(x_t)
output = torch.stack(output)
if self.batch_first:
output = output.transpose(0, 1)
state = tuple(state.transpose(0, 1))
output = self.fc1(output)
return output
class sLSTMBlock(nn.Module):
def __init__(self, input_size, hidden_size, num_heads, proj_factor=4 / 3):
super(sLSTMBlock, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_size = hidden_size // num_heads
self.proj_factor = proj_factor
assert hidden_size % num_heads == 0
assert proj_factor > 0
self.layer_norm = nn.LayerNorm(input_size)
self.causal_conv = CausalConv1D(1, 1, 4)
self.Wz = BlockDiagonal(input_size, hidden_size, num_heads)
self.Wi = BlockDiagonal(input_size, hidden_size, num_heads)
self.Wf = BlockDiagonal(input_size, hidden_size, num_heads)
self.Wo = BlockDiagonal(input_size, hidden_size, num_heads)
self.Rz = BlockDiagonal(hidden_size, hidden_size, num_heads)
self.Ri = BlockDiagonal(hidden_size, hidden_size, num_heads)
self.Rf = BlockDiagonal(hidden_size, hidden_size, num_heads)
self.Ro = BlockDiagonal(hidden_size, hidden_size, num_heads)
self.group_norm = nn.GroupNorm(num_heads, hidden_size)
self.up_proj_left = nn.Linear(hidden_size, int(hidden_size * proj_factor))
self.up_proj_right = nn.Linear(hidden_size, int(hidden_size * proj_factor))
self.down_proj = nn.Linear(int(hidden_size * proj_factor), input_size)
def forward(self, x, prev_state):
assert x.size(-1) == self.input_size
h_prev, c_prev, n_prev, m_prev = prev_state
x_norm = self.layer_norm(x)
x_conv = F.silu(self.causal_conv(x_norm.unsqueeze(1)).squeeze(1))
z = torch.tanh(self.Wz(x) + self.Rz(h_prev))
o = torch.sigmoid(self.Wo(x) + self.Ro(h_prev))
i_tilde = self.Wi(x_conv) + self.Ri(h_prev)
f_tilde = self.Wf(x_conv) + self.Rf(h_prev)
m_t = torch.max(f_tilde + m_prev, i_tilde)
i = torch.exp(i_tilde - m_t)
f = torch.exp(f_tilde + m_prev - m_t)
c_t = f * c_prev + i * z
n_t = f * n_prev + i
h_t = o * c_t / n_t
output = h_t
output_norm = self.group_norm(output)
output_left = self.up_proj_left(output_norm)
output_right = self.up_proj_right(output_norm)
output_gated = F.gelu(output_right)
output = output_left * output_gated
output = self.down_proj(output)
final_output = output + x
return final_output, (h_t, c_t, n_t, m_t)
class mLSTMBlock(nn.Module):
def __init__(self, input_size, hidden_size, num_heads, proj_factor=2):
super(mLSTMBlock, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_size = hidden_size // num_heads
self.proj_factor = proj_factor
assert hidden_size % num_heads == 0
assert proj_factor > 0
self.layer_norm = nn.LayerNorm(input_size)
self.up_proj_left = nn.Linear(input_size, int(input_size * proj_factor))
self.up_proj_right = nn.Linear(input_size, hidden_size)
self.down_proj = nn.Linear(hidden_size, input_size)
self.causal_conv = CausalConv1D(1, 1, 4)
self.skip_connection = nn.Linear(int(input_size * proj_factor), hidden_size)
self.Wq = BlockDiagonal(int(input_size * proj_factor), hidden_size, num_heads)
self.Wk = BlockDiagonal(int(input_size * proj_factor), hidden_size, num_heads)
self.Wv = BlockDiagonal(int(input_size * proj_factor), hidden_size, num_heads)
self.Wi = nn.Linear(int(input_size * proj_factor), hidden_size)
self.Wf = nn.Linear(int(input_size * proj_factor), hidden_size)
self.Wo = nn.Linear(int(input_size * proj_factor), hidden_size)
self.group_norm = nn.GroupNorm(num_heads, hidden_size)
def forward(self, x, prev_state):
h_prev, c_prev, n_prev, m_prev = prev_state
assert x.size(-1) == self.input_size
x_norm = self.layer_norm(x)
x_up_left = self.up_proj_left(x_norm)
x_up_right = self.up_proj_right(x_norm)
x_conv = F.silu(self.causal_conv(x_up_left.unsqueeze(1)).squeeze(1))
x_skip = self.skip_connection(x_conv)
q = self.Wq(x_conv)
k = self.Wk(x_conv) / (self.head_size ** 0.5)
v = self.Wv(x_up_left)
i_tilde = self.Wi(x_conv)
f_tilde = self.Wf(x_conv)
o = torch.sigmoid(self.Wo(x_up_left))
m_t = torch.max(f_tilde + m_prev, i_tilde)
i = torch.exp(i_tilde - m_t)
f = torch.exp(f_tilde + m_prev - m_t)
c_t = f * c_prev + i * (v * k)
n_t = f * n_prev + i * k
h_t = o * (c_t * q) / torch.max(torch.abs(n_t.T @ q), 1)[0]
output = h_t
output_norm = self.group_norm(output)
output = output_norm + x_skip
output = output * F.silu(x_up_right)
output = self.down_proj(output)
final_output = output + x
return final_output, (h_t, c_t, n_t, m_t)
class CausalConv1D(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, dilation=1, **kwargs):
super(CausalConv1D, self).__init__()
self.padding = (kernel_size - 1) * dilation
self.conv = nn.Conv1d(in_channels, out_channels, kernel_size, padding=self.padding, dilation=dilation, **kwargs)
def forward(self, x):
x = self.conv(x)
return x[:, :, :-self.padding]
class BlockDiagonal(nn.Module):
def __init__(self, in_features, out_features, num_blocks):
super(BlockDiagonal, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.num_blocks = num_blocks
assert in_features % num_blocks == 0
assert out_features % num_blocks == 0
block_in_features = in_features // num_blocks
block_out_features = out_features // num_blocks
self.blocks = nn.ModuleList([
nn.Linear(block_in_features, block_out_features)
for _ in range(num_blocks)
])
def forward(self, x):
x = x.chunk(self.num_blocks, dim=-1)
x = [block(x_i) for block, x_i in zip(self.blocks, x)]
x = torch.cat(x, dim=-1)
return x
✨ data.py✨
import pandas as pd
import numpy as np
import torch
from torch.utils.data import Dataset
from sklearn.preprocessing import MinMaxScaler
from copy import deepcopy as dc
class TimeSeriesDataset(Dataset):
"""
定义数据集类
"""
def __init__(self, X, y):
self.X = X
self.y = y
def __len__(self):
return len(self.X)
def __getitem__(self, i):
return self.X[i], self.y[i]
def prepare_dataframe_for_xlstm(df, n_steps):
"""
处理数据集,使其适用于xLSTM模型
"""
df = dc(df)
df['date'] = pd.to_datetime(df['date'])
df.set_index('date', inplace=True)
for i in range(1, n_steps + 1):
df[f'close(t-{i})'] = df['close'].shift(i)
df.dropna(inplace=True)
return df
def get_dataset(file_path, lookback, split_ratio=0.9):
"""
归一化数据、划分训练集和测试集
"""
data = pd.read_csv(file_path)
data = data[['date', 'close']]
# 将 DataFrame 处理为适合 xLSTM 的形式
shifted_df = prepare_dataframe_for_xlstm(data, lookback)
scaler = MinMaxScaler(feature_range=(-1, 1))
scaled_array = scaler.fit_transform(shifted_df)
X = scaled_array[:, 1:]
y = scaled_array[:, 0]
# Note: X 数据按时间顺序反转,是很多时间序列数据处理的一部分
X = np.flip(X, axis=1).copy() # 加上 .copy() 以避免负步长问题
# 划分训练集和测试集
split_index = int(len(X) * split_ratio)
X_train, X_test = X[:split_index], X[split_index:]
y_train, y_test = y[:split_index], y[split_index:]
X_train = X_train.reshape((-1, lookback, 1))
X_test = X_test.reshape((-1, lookback, 1))
y_train = y_train.reshape((-1, 1))
y_test = y_test.reshape((-1, 1))
# 转换为Tensor
X_train = torch.tensor(X_train).float()
y_train = torch.tensor(y_train).float()
X_test = torch.tensor(X_test).float()
y_test = torch.tensor(y_test).float()
# 创建 PyTorch 数据集
train_dataset = TimeSeriesDataset(X_train, y_train)
test_dataset = TimeSeriesDataset(X_test, y_test)
return scaler, train_dataset, test_dataset, X_train, X_test, y_train, y_test
train.py
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import swanlab
from copy import deepcopy as dc
import os
from model import Model, LSTMModel
from data import get_dataset
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import numpy as np
def save_best_model(model, config, epoch):
if not os.path.exists(config.save_path):
os.makedirs(config.save_path)
torch.save(model.state_dict(), os.path.join(config.save_path, 'best_model.pth'))
print(f'Val Epoch: {epoch} - Best model saved at {config.save_path}')
def train(model, train_loader, optimizer, criterion, scheduler):
running_loss = 0
# 训练
for i, batch in enumerate(train_loader):
x_batch, y_batch = batch[0].to(device), batch[1].to(device)
y_pred = model(x_batch)
loss = criterion(y_pred, y_batch)
# print(i, loss.item())
running_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
avg_loss_epoch = running_loss / len(train_loader)
print(f'Epoch: {epoch}, Batch: {i}, Avg. Loss: {avg_loss_epoch}')
swanlab.log({"train/loss": running_loss}, step=epoch)
running_loss = 0
def validate(model, config, test_loader, criterion, epoch, best_loss=None):
model.eval()
val_loss = 0
all_preds = []
all_targets = []
with torch.no_grad():
for _, batch in enumerate(test_loader):
x_batch, y_batch = batch[0].to(device), batch[1].to(device)
y_pred = model(x_batch)
loss = criterion(y_pred, y_batch)
val_loss += loss.item()
all_preds.append(y_pred.cpu().numpy())
all_targets.append(y_batch.cpu().numpy())
avg_val_loss = val_loss / len(test_loader)
print(f'Epoch: {epoch}, Validation Loss: {avg_val_loss}')
# Convert lists to numpy arrays
all_preds = np.concatenate(all_preds)
all_targets = np.concatenate(all_targets)
# Calculate additional metrics
val_mae = mean_absolute_error(all_targets, all_preds)
val_rmse = mean_squared_error(all_targets, all_preds, squared=False)
val_r2 = r2_score(all_targets, all_preds)
print(f'Validation MAE: {val_mae}, RMSE: {val_rmse}, R2: {val_r2}')
swanlab.log({"val/loss": avg_val_loss, "val/mae": val_mae, "val/rmse": val_rmse, "val/r2": val_r2}, step=epoch)
if epoch == 1:
best_loss = avg_val_loss
if avg_val_loss < best_loss:
best_loss = avg_val_loss
save_best_model(model, config, epoch)
return best_loss
def visualize_predictions(train_predictions, val_predictions, scaler, X_train, X_test, y_train, y_test, lookback):
train_predictions = train_predictions.flatten()
val_predictions = val_predictions.flatten()
dummies = np.zeros((X_train.shape[0], lookback + 1))
dummies[:, 0] = train_predictions
dummies = scaler.inverse_transform(dummies)
train_predictions = dc(dummies[:, 0])
dummies = np.zeros((X_test.shape[0], lookback + 1))
dummies[:, 0] = val_predictions
dummies = scaler.inverse_transform(dummies)
val_predictions = dc(dummies[:, 0])
dummies = np.zeros((X_train.shape[0], lookback + 1))
dummies[:, 0] = y_train.flatten()
dummies = scaler.inverse_transform(dummies)
new_y_train = dc(dummies[:, 0])
dummies = np.zeros((X_test.shape[0], lookback + 1))
dummies[:, 0] = y_test.flatten()
dummies = scaler.inverse_transform(dummies)
new_y_test = dc(dummies[:, 0])
# 训练集预测结果可视化
plt.figure(figsize=(10, 6))
plt.plot(new_y_train, color='red', label='Actual Train Close Price')
plt.plot(train_predictions, color='blue', label='Predicted Train Close Price', alpha=0.5)
plt.xlabel('Date')
plt.ylabel('Close Price')
plt.title('(TrainSet) Google Stock Price Prediction with xLSTM')
plt.legend()
plt_image = []
plt_image.append(swanlab.Image(plt, caption="TrainSet Price Prediction"))
# 测试集预测结果可视化
plt.figure(figsize=(10, 6))
plt.plot(new_y_test, color='red', label='Actual Test Close Price')
plt.plot(val_predictions, color='blue', label='Predicted Test Close Price', alpha=0.5)
plt.xlabel('Date')
plt.ylabel('Close Price')
plt.title('(TestSet) Google Stock Price Prediction with LSTM')
plt.legend()
plt_image.append(swanlab.Image(plt, caption="TestSet Price Prediction"))
swanlab.log({"Prediction": plt_image})
if __name__ == '__main__':
# 初始化一个SwanLab实验
swanlab.init(
project='Google-Stock-Prediction',
experiment_name="xlstm",
description="基于LSTM模型对Google股票价格数据集的训练与推理",
config={
"learning_rate": 4e-3,
"epochs": 50,
"batch_size": 32,
"lookback": 60,
"trainset_ratio": 0.95,
"save_path": f'./checkpoint/{pd.Timestamp.now().strftime("%Y-%m-%d_%H-%M-%S")}',
"optimizer": "AdamW",
},
# mode="disabled",
)
config = swanlab.config
device = torch.device('cpu')
lookback = config.get('lookback') # 提取lookback值
# ------------------- 定义数据集 -------------------
scaler, train_dataset, test_dataset, X_train, X_test, y_train, y_test = get_dataset('./GOOG.csv', lookback)
train_loader = DataLoader(train_dataset, batch_size=config.batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=config.batch_size, shuffle=False)
num_heads = 1
layers = ['s', 'm', 's']
model = Model(num_heads, layers)
# model = LSTMModel(input_size=1, output_size=1)
model = model.to(device)
optimizer = optim.AdamW(model.parameters(), lr=config.learning_rate)
criterion = nn.MSELoss()
# ------------------- 定义学习率衰减策略 -------------------
def lr_lambda(epoch):
total_epochs = config.epochs
start_lr = config.learning_rate
end_lr = start_lr * 0.01
update_lr = ((total_epochs - epoch) / total_epochs) * (start_lr - end_lr) + end_lr
return update_lr * (1 / config.learning_rate)
scheduler = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)
# ------------------- 训练与验证 -------------------
for epoch in range(1, config.epochs + 1):
model.train()
swanlab.log({"train/lr": scheduler.get_last_lr()[0]}, step=epoch)
train(model, train_loader, optimizer, criterion, scheduler)
if epoch == 1: best_loss = None
best_loss = validate(model, config, test_loader, criterion, epoch, best_loss=best_loss)
# ------------------- 使用最佳模型推理,与生成可视化结果 -------------------
with torch.no_grad():
# 加载最佳模型
best_model_path = os.path.join(config.save_path, 'best_model.pth')
model.load_state_dict(torch.load(best_model_path))
model.eval()
train_predictions = model(X_train.to(device)).cpu().numpy() # 使用 `cpu` 而不是 `GPU`
val_predictions = model(X_test.to(device)).cpu().numpy() # 使用 `cpu` 而不是 `GPU`
# 可视化预测结果
visualize_predictions(train_predictions, val_predictions, scaler, X_train, X_test, y_train, y_test, config.lookback)

















 2260
2260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









