






没有知识库喂养的AI,就像一个刚出大学校门的学生,有潜力但很多实际问题无法回答,而经过本地知识库加持的AI,那才是特定领域的专家,可以成为你的良师益友,协助你更好的解答实际问题。
现在的ChatGPT和Claude等AI都支持上传文档回答问题,但不是每个人都能使用。国内的大模型也有文档功能,测试下来效果不是很好。还有一点,不管国内还是国外的AI,允许上传的文档数量有限制,一般只允许上传一个文档提问,Claude属于比较慷慨,大概也只能上传10个文档。
抛开这些不说,知识库是数据,一些敏感的数据,现在大家还不是很放心交给别人,所以搭建一个本地的知识库聊天机器人,是很实际的刚需,尤其对于企业来说,就更是如此。
要在本地搭建一套知识库聊天系统,要做的工作真不少,感谢开源的Langchain-Chatchat,它让这一切变得相当简单。
Langchain-Chatchat既支持开源模型(需要硬件,如A6000),也支持OpenAI等开源模型(需要购买OpenAI的key)。
下面进入正题,手把手教大家基于Langchain-Chatchat,在本地搭建一个知识库聊天系统,把我的实践经验分享给你,避免一些踩过坑。
我使用的硬件和模型信息:
显卡:一块英伟达的A6000
LLM:开源的chatglm3-6b
向量模型:开源的jina-embedding-l-en-v1
向量数据库:开源的milvus
搭建本地知识库,并基于其进行AI聊天,原理和流程如下图:
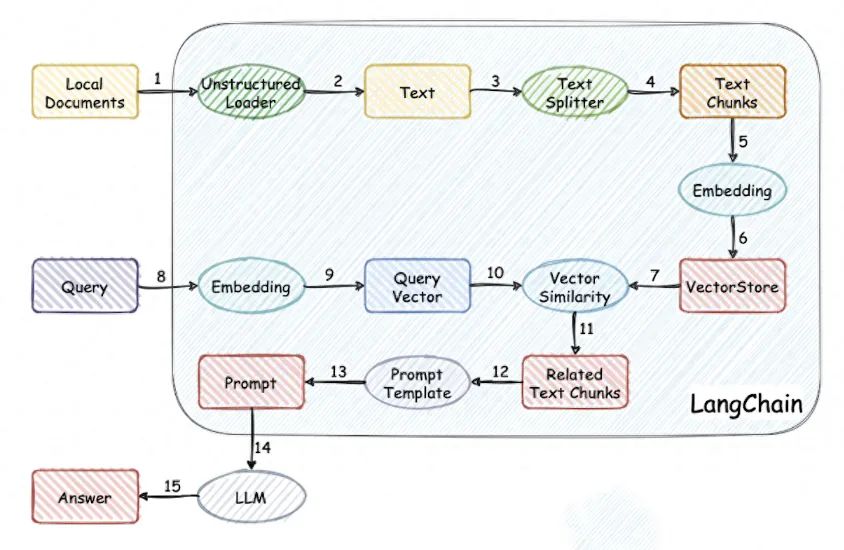
知识库聊天机器人实现流程
===
环境准备
请注意,我搭建时,langchain-chatchat的版本是v0.2.6,不同的版本,相关的环境可能存在变化。
首先,确保你的机器安装了 Python 3.10
`$ python --version Python 3.10.13`
如果未安装3.10,可从官网下载编译安装。
`wget https://www.python.org/ftp/python/3.10.13/Python-3.10.13.tgz sudo apt install wget lzma liblzma-dev build-essential libncursesw5-dev libssl-dev libsqlite3-dev tk-dev libgdbm-dev libc6-dev libbz2-dev libffi-dev zlib1g-dev mkdir -p /home/xaccel/Documents/chatchat/python310/ ./configure --prefix=/home/xaccel/Documents/chatchat/python310/ --with-ssl --enable-optimizations make make install sudo ln -sf ~/Documents/chatchat/python310/bin/python3.10 /usr/bin/python3 sudo ln -sf ~/Documents/chatchat/python310/bin/pip3.10 /usr/bin/pip3`
接着,创建一个虚拟环境,并在虚拟环境内安装项目的依赖
`# 拉取仓库 $ git clone https://github.com/chatchat-space/Langchain-Chatchat.git # 进入目录 $ cd Langchain-Chatchat #创建虚拟环境 $ python3 -m venv myenv $ source myenv/bin/activate # 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。 # 我们需要milvus数据库,修改requirements.txt $ vi requirements.txt # 找到行:# pymilvus==2.1.3,去除注释 # 安装全部依赖 $ pip install -r requirements.txt`
安装并运行milvus数据库
注意requirements.txt中的pymilvus版本是2.1.3,所以milvus也需要安装对应的版本,即milvus 2.1.x。
下载milvus 2.1.x
`wget https://github.com/milvus-io/milvus/releases/download/v2.1.4/milvus-standalone-docker-compose.yml -O docker-compose.yml`
启动向量数据库milvus
`sudo docker-compose up -d`
下载开源模型
langchain-chatchat支持开源模型和OpenAI等商用模型,我需要开源模型,先将开源大模型下载至本地,通常开源 LLM 与 Embedding 模型可以从 HuggingFace 下载。
以本项目中默认使用的 LLM 模型 THUDM/ChatGLM3-6B 与 Embedding 模型
jinaai/jina-embedding-l-en-v1 为例:
下载模型需要先安装 Git LFS,然后运行
`$ git lfs install # 将大模型下载到以下文件夹 $ cd /xrepo/KDB/LLM/ChatMode # 下载大模型 $ git clone https://huggingface.co/THUDM/chatglm3-6b $ git clone https://huggingface.co/jinaai/jina-embedding-l-en-v1`
初始化知识库和配置文件
复制配置文件,并配置步骤二中下载的大模型
`$ python copy_config_example.py # 修改模型配置文件 $ vi configs/model_config.py # 设置大模型存放路径 MODEL_ROOT_PATH = "/xrepo/KDB/LLM/ChatMode" # embed_model下增加: "jina-embedding-l-en-v1":"jinaai/jina-embedding-l-en-v1", # llm_model下增加: "chatglm3-6b": "THUDM/chatglm3-6b", # 修改默认EMBEDDING_MODEL EMBEDDING_MODEL = "jina-embedding-l-en-v1" # 修改默认LLM LLM_MODEL = "chatglm3-6b"`
初始化数据库
`$ python init_database.py --recreate-vs`
一键启动聊天机器人
安装完成,输入以下命令启动
`$ python startup.py -a`
看到下面画面后,表示正常启动了
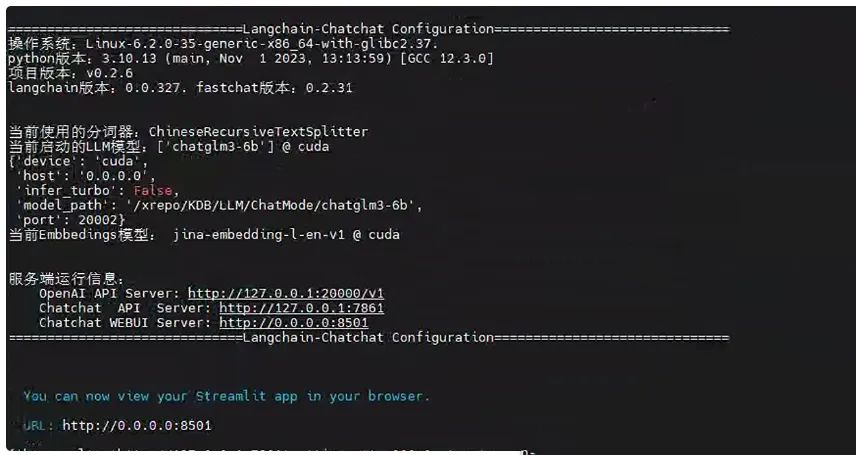
langchain-chatchat启动画面
在浏览器输入聊天机器人地址:http://127.0.0.1:8561

本地知识库聊天机器人
===
聊天机器人使用说明
打开Web地址后,左侧可看见两个菜单,分别是“对话”和“知识库管理”
1、对话
即和AI聊天对话,可选择对话模式,LLM模型,prompt模板,温度参数设定以及记忆保留次数。对话模式有四个选项:LLM对话、知识库问答、搜索引擎问答、自定义Agent。

可选四种对话模式
LLM对话是和大模型直接聊天,基于大模型的通用能力。
知识库问答需要先创建知识库,每次可选择一个知识库进行聊天,切换到知识库问答后,在底部“知识库配置”中选择要对话的知识库。
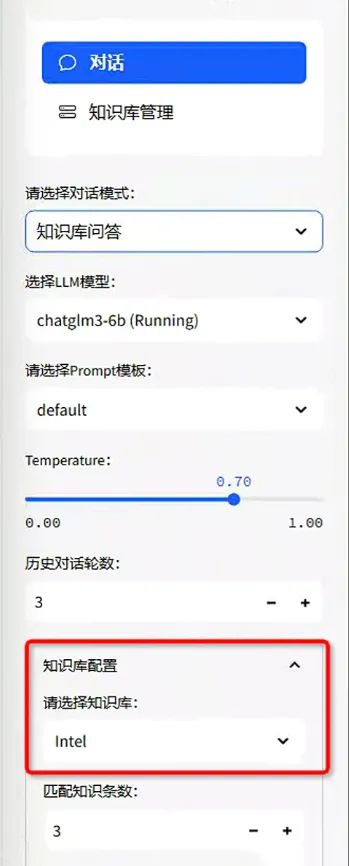
选择对话知识库
搜索引擎问答和自定义Agent,需要进行相应配置和开发,才能使用。
2、知识库管理
切换到知识库管理后,可以查看和删除已创建知识库、新增知识库,也可以对知识库进行文件增减。

知识库管理
新建知识库:点击“新建知识库”,输入知识库名称和简介,选择向量数据库和模型,再点击新建即可。
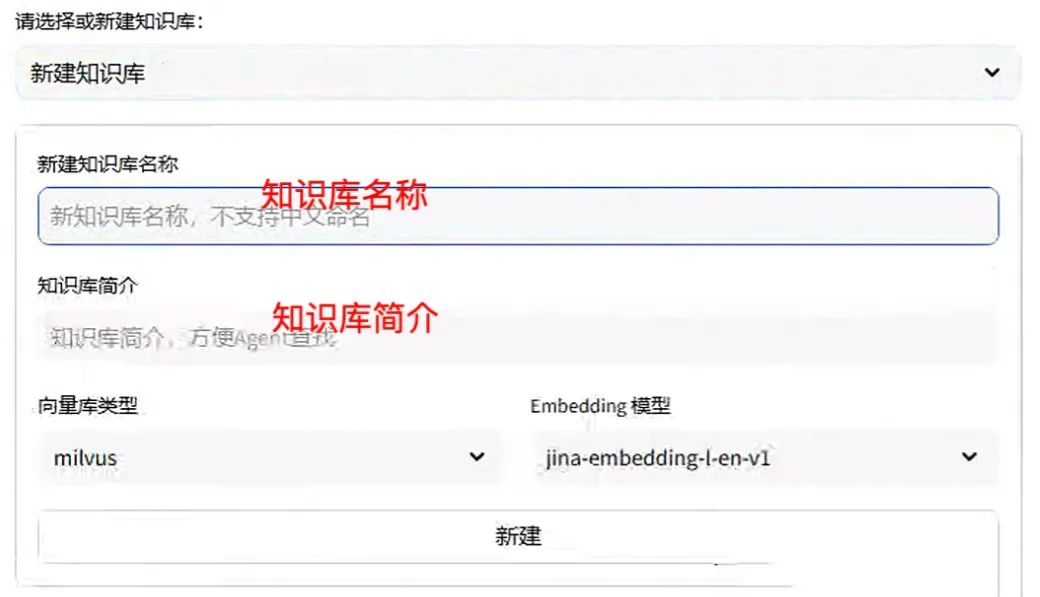
新建知识库
上传文件到知识库:选择已创建知识库,选择上传文件,点击“添加文件到知识库”

上传文件到知识库
删除知识库/删除知识库文件:见下图
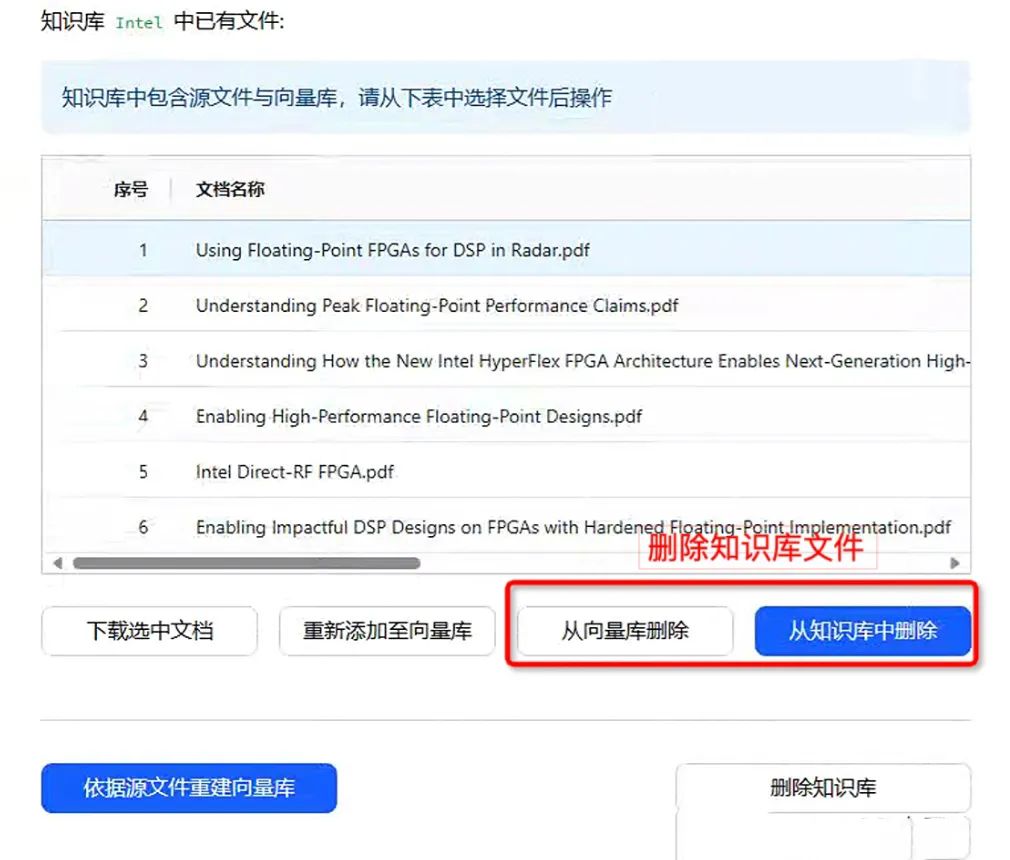
删除知识库
创建好知识库后,可以切换菜单到“对话”,选择对话模式为“知识库问答”,并选择要对话的知识库,即可开启和特定知识库聊天。
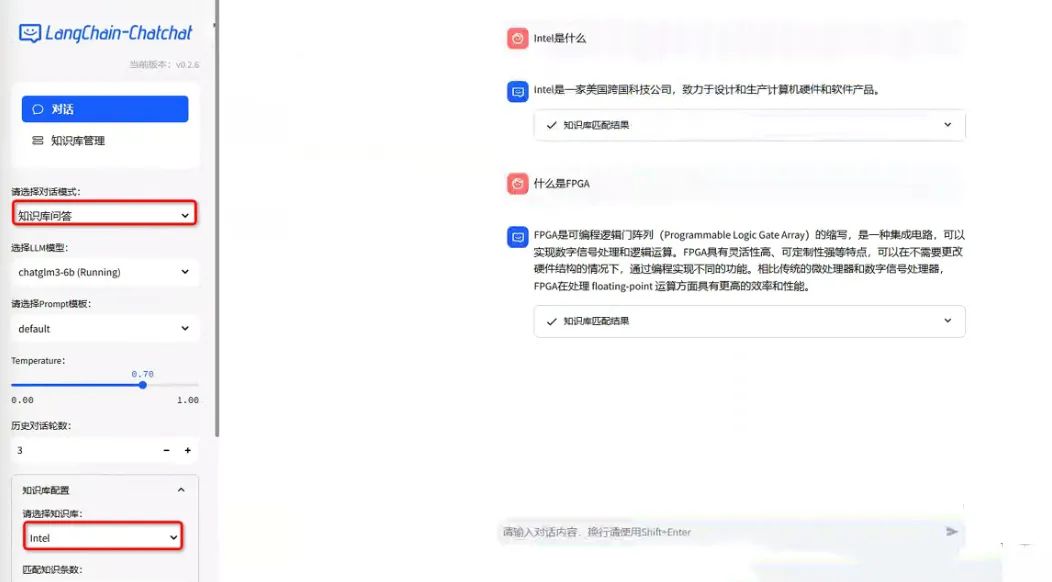
和知识库聊天
大功告成,本地知识库聊天系统搭建完成,想用别的模型,可以直接在界面上切换,大部分开源模型都支持,只要你的硬件够牛~
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
最后,感谢每一个认真阅读我文章的人,礼尚往来总是要有的,下面资料虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:


















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









