







全文总结
这篇论文《IdeaBench: Benchmarking Large Language Models for Research Idea Generation》探讨了如何使用大规模语言模型(LLMs)生成研究想法,并提出了一个基准系统IdeaBench来评估这些模型的生成能力。
https://anonymous.4open.science/r/IdeaBench-2747/
核心速览
研究背景
-
研究问题:这篇文章要解决的问题是如何评估大型语言模型(LLMs)在生成研究想法方面的能力。尽管LLMs在各项任务中取得了最先进的成果,但缺乏一个全面和系统的评估框架来衡量它们在科学研究想法生成中的表现。
-
研究难点:该问题的研究难点包括:如何构建一个包含高质量目标论文及其参考文献的数据集,如何设计一个能够模拟人类研究人员生成研究想法的提示模板,以及如何开发一个能够量化生成想法质量的评估框架。
-
相关工作:该问题的研究相关工作包括基于文献的发现(LBD)方法,这些方法通过挖掘文献来识别生物医学概念之间的隐含关联。最近的研究还探索了使用LLMs进行假设生成,但这些研究缺乏统一的评估标准。
研究方法
这篇论文提出了IdeaBench,一个用于评估LLMs生成研究想法能力的基准系统。具体来说,
-
数据集构建:首先,构建了一个包含2374篇目标论文摘要及其29408篇参考文献摘要的数据集。这些目标论文是从生物医学研究领域中精心挑选的高质量初级研究论文。通过使用Semantic Scholar API提取目标论文及其参考文献的摘要,确保数据的完整性和相关性。
-
提示模板设计:为了生成研究想法,设计了一个提示模板,将LLMs定位为特定领域的研究人员,并提供相关的背景信息。提示模板如下:
You are a biomedical researcher. You are tasked with creating a hypothesis or research idea given some background knowledge. The background knowledge is provided by abstracts from other papers.
Here are the abstracts:
Abstract 1:{reference_paper_1_abstract}
Abstract 2:{reference_paper_2_abstract}
Abstract n:{reference_paper_n_abstract}
Using these abstracts, reason over them and come up with a novel hypothesis. Please avoid copying ideas directly, rather use the insights to inspire a novel hypothesis in the form of a brief and concise paragraph. -
评估框架:提出了一个评估框架,包括个性化质量排名和相对质量评分。个性化质量排名允许用户指定任何质量指标(如新颖性、可行性等),并使用GPT-4o对生成的想法进行排名。相对质量评分通过计算目标论文想法在所有生成想法中的相对排名来量化所选质量指标。
实验设计
-
数据集:从2024年发表的生物医学初级研究论文中精心挑选了2374篇高质量目标论文,并通过Semantic Scholar API提取了这些论文及其29408篇参考文献的摘要。
-
模型选择:测试了几种最受欢迎的商业和开源LLMs系列,包括Meta LLama Series、Google Gemini Series和OpenAI GPT Series。所有模型均在2024年1月1日之前的数据上进行训练,以确保公平比较。
-
基线比较指标:为了展示Insight Score的优势,将其与两种相似性度量进行比较:语义相似性和想法重叠。使用BERTScore(F1分数)测量语义相似性,使用GPT-4o测量想法重叠。
-
资源场景:考虑了高低资源场景,以评估LLMs在研究人员面临计算约束和资源充足时的能力。在低资源场景中,LLMs输入过滤后的五个参考文献;在高资源场景中,LLMs输入所有未过滤的参考文献,除了GPT-3.5 Turbo,它截断了无法适应其上下文窗口的参考文献。
结果与分析
-
生成想法的能力:大多数LLMs能够生成与研究目标论文相似的想法。高资源场景生成的想法比低资源场景具有更高的相似性得分,表明LLMs能够理解背景信息并生成类似的想法。
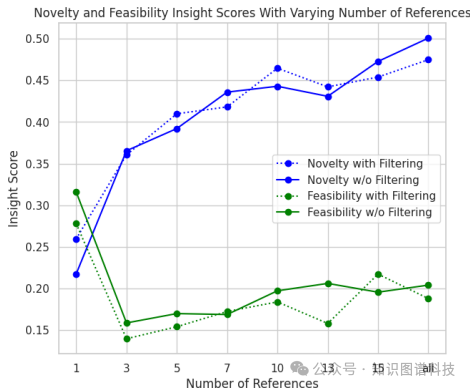
-
新颖性:大多数LLMs能够生成至少与目标论文一样新颖的想法。Insight Score显示,大多数LLMs的新颖性得分超过0.6,其中GPT-4o的高资源场景得分最高,为0.766。
-
可行性:大多数LLMs生成的想法的可行性低于目标论文。尽管LLMs可以生成新颖的想法,但其可行性通常不如人类生成的想法。
-
参考过滤的效果:参考过滤对于帮助低容量模型生成更具新颖性的想法至关重要。在低资源场景中,GPT-3.5 Turbo和Llama 3.1 70B-Instruct模型的新颖性Insight Score高于高资源场景。
总体结论
这篇论文介绍了IdeaBench,一个用于评估LLMs生成研究想法能力的基准系统。通过构建一个包含高质量目标论文及其参考文献的数据集,设计一个模拟人类研究人员生成研究想法的提示模板,并提出一个能够量化生成想法质量的评估框架,IdeaBench为学术界提供了一个衡量和比较不同LLMs的工具,最终推动了科学发现自动化进程。
论文评价
优点与创新
-
构建了IdeaBench数据集:该数据集包含2,374篇有影响力的生物医学目标论文及其29,408篇参考文献,为评估LLMs生成研究想法的能力提供了坚实的基础。
-
提出了“Insight Score”评估框架:该框架通过个性化质量排名和相对质量评分,提供了一种可扩展且全面的度量方法,能够量化新颖性、可行性等用户定义的质量指标。
-
模拟人类研究者的研究过程:通过将LLMs定位为特定领域的研究者,并使其沉浸在与研究者相同的上下文中,最大限度地利用了LLMs的参数知识,从而生成更具深度和洞察力的研究想法。
-
广泛的实验验证:论文对多种流行的LLMs(如Meta LLama Series、Google Gemini Series和OpenAI GPT Series)进行了广泛的实验,展示了它们在生成研究想法方面的能力。
-
低资源场景下的评估:考虑了LLMs在面对计算约束时的表现,评估了其在低资源场景下的生成能力。
不足与反思
-
参考过滤的有效性:尽管参考过滤在高资源场景下有效,但在低资源场景下仍需进一步验证其有效性,以确保LLMs能够专注于最相关的信息,从而生成更具创新性的研究想法。
-
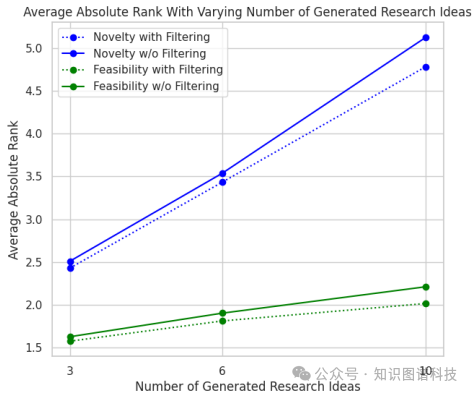
生成想法数量的限制:实验中每次查询生成的研究想法数量为3个,这一数量可能会影响Insight Score的公平性。未来可以探索不同生成数量对Insight Score的影响,以提供更全面的比较。
-
模型能力的局限性:较小的LLMs(如Llama 3.1 8B-Instruct)在生成连贯且有相关性的研究想法方面表现不佳,这表明这些模型在支持研究想法生成方面仍有改进空间。
关键问题及回答
问题1:IdeaBench数据集的构建过程是怎样的?
IdeaBench数据集是通过以下步骤构建的:
-
数据收集:从2024年发表的生物医学初级研究论文中精心挑选了2374篇高质量目标论文。这些论文是从顶级生物医学会议或其他生物医学期刊中检索到的,确保其学术质量和影响力。
-
参考文献提取:通过Semantic Scholar API提取了这些目标论文及其29408篇参考文献的摘要。这些参考文献提供了生成新研究想法所需的背景知识。
-
过滤和筛选:为了确保数据的相关性和重要性,进行了基于引用次数、非主要研究类型和背景部分相关性的过滤。具体来说,排除了引用次数少于五次、非主要研究类型的参考文献(如综述、社论等),以及未在目标论文背景部分引用的参考文献。
问题2:IdeaBench评估框架中的个性化质量排名是如何实现的?
个性化质量排名的实现步骤如下:
-
创建想法集合:对于每个目标论文和参考论文对,创建一个包含生成的想法和目标论文原始想法的想法集合。
-
提示模板:使用特定的提示模板,引导LLMs根据用户指定的质量指标(如新颖性、可行性等)对生成的想法进行排名。例如,如果用户希望按新颖性排名,提示模板会将质量指标替换为“新颖性”。
-
GPT-4o排名:利用GPT-4o模型对生成的想法进行排名。LLMs根据提示模板提供的背景和用户指定的质量指标,生成对每个想法的评价。
-
结果分析:GPT-4o模型生成的排名结果用于评估每个想法的质量,确保评估过程的一致性和可解释性。
问题3:实验结果表明LLMs在生成研究想法方面有哪些优势和局限性?
- 优势:
-
生成相似的想法:大多数LLMs能够生成与目标论文相似的研究想法,特别是在高资源场景下,生成的想法具有更高的语义相似度和想法重叠度。
-
生成新颖的想法:大多数LLMs能够生成与目标论文相当甚至更具新颖性的研究想法。许多LLMs的新颖性Insight Score超过0.6,其中GPT-4o(高资源)得分最高,为0.766。
- 局限性:
-
可行性问题:大多数LLMs生成的想法的可行性低于目标论文。尽管LLMs可以生成新颖的想法,但其可行性通常较差,所有LLMs的可行性Insight Score均低于0.5。
-
新颖性与可行性的权衡:对于所有LLMs,新颖性与可行性之间存在差距。除GPT-3.5 Turbo(高资源)外,所有模型的可行性Insight Score均低于新颖性Insight Score。
-
参考过滤的重要性:参考过滤对于帮助低容量模型生成更具新颖性的研究想法至关重要。在低资源场景下,GPT-3.5 Turbo和Llama 3.1 70B-Instruct模型的新颖性Insight Score高于高资源场景。
案例研究
在本节中,我们包含了一系列案例研究,以说明LLMs在生成研究思想方面的能力,支持我们主要基准的发现。每个案例研究包括10个示例,展示LLMs如何生成与其目标论文相似、更具创新性且在可行性上可比较的研究思想。此外,还有两个示例突出了较小的LLM如何产生不连贯和无关的文本。通过这些示例,我们展示了LLMs在与目标论文对齐方面的优势,有时在新颖性上甚至超越它们,同时保持相似的可行性。我们还强调,较小的模型可能无法生成连贯且相关的研究思想。
生成的研究思想与目标论文相似。
我们发现,当提供相同的背景信息时,LLMs可以通过生成与其目标论文中的研究思想相似的研究思想来模拟人类研究人员。我们展示了LLM生成的研究思想与其目标论文之间表现出显著重叠的示例,尽管这些论文在LLM的训练期间没有被看到。这些示例在图7至图16中展示。每个示例包括目标论文的摘要、LLM生成的思想,以及思想重叠评级的解释,强调了两者非常相似的原因。人类研究人员用绿色突出显示目标论文摘要和生成的研究思想之间的重叠关键点。通过这些示例,我们注意到LLMs能够识别并利用目标论文所有未过滤参考文献中最相关的思想,使其能够生成解决与目标论文类似问题的研究思想。此外,这些模型可以生成预测与原始工作中呈现的发现相关或非常接近的思想。这表明LLMs不仅能够识别关键研究问题,还能预测结果,与目标论文的结论紧密对齐。
生成的研究思想的新颖性。
我们的主要结果表明,LLMs可以生成与其目标论文中的思想一样新颖,甚至更具新颖性的研究思想。我们提供了LLM生成的研究思想在新颖性方面超越其目标论文的示例,见于图17至图26。这些图包括目标论文的研究思想、生成的研究思想,以及Insight Score对生成思想在新颖性上排名更高的理由。人类研究人员用绿色突出显示生成思想新颖性的贡献方面,用红色突出显示目标论文思想新颖性较低的原因。这些示例展示了LLMs生成新颖研究思想的能力。
从这些示例中,我们观察到LLMs通过创造性地建立不同概念或发现之间的联系,生成新颖的研究思想。当生成的研究思想在新颖性上排名高于目标论文的思想时,通常是因为目标论文的思想是在现有研究的基础上逐步构建的,而LLM生成的思想则提出了来自参考论文的不同概念或科学发现之间的新联系。这表明,当提供适当的背景信息时,LLMs可以生成大胆而新颖的研究思想。
生成的研究思想的可行性。
生成的研究思路的可行性。
尽管我们的结果表明,LLM(大型语言模型)往往无法生成比目标论文中更可行的研究想法,但仍然有一些例子表明,LLM生成的研究想法在可行性上与目标论文的想法相当。我们在图27到36中提供了一些例子,展示LLM生成的研究想法在可行性上与目标论文的想法相当。这些图包括目标论文的研究想法、生成的研究想法以及对生成想法可行性的Insight Score的理由。人类研究人员用绿色标出有助于生成想法可行性的元素。这些例子展示了LLM生成可行研究想法的能力。通过分析这些例子,我们观察到当LLM生成可行的研究想法时,这些想法通常是直接的,并依赖于已有的技术和方法。
为了评估小型LLM在生成研究想法方面的有效性,我们在低资源和高资源条件下测试了LLama 3.1 8B-Instruct。结果见表5。LLama 3.1 8B-Instruct报告了高的想法重叠率和新颖的Insight Score,但由于生成大量无关或不连贯的文本,其可行性Insight Score较低。我们的LLM基础评估(想法重叠和Insight Score)未能处理这种情况,因为LLM并未在低质量文本上进行训练,而我们的提示模板也未考虑不连贯的文本。因此,无关和劣质文本在我们的评估中引入了偏差。LLama 3.1 8B-Instruct生成的无关和不连贯文本的例子见图37和38,其中人类研究人员用红色高亮的部分表示模型生成的问题文本。
由于LLama 3.1 8B-Instruct生成了大量无关和无意义的文本,并且我们的LLM评估不适用于这些输出,我们选择不将其结果纳入主要发现中。我们呈现这些结果是为了告知社区,小型LLM不足以生成连贯的研究想法。




如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

















 1688
1688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









