






人类智能有四个基本特征:推理、计划、持久记忆和理解物理世界,这些是当前 AI 系统无法做到的。
没有这些能力,AI 应用会受到限制并且容易出错。不说闲话了,让我们一起探讨 LLM 的复杂世界,通过各种研究论文、推文、新闻报道和讲座,深入了解 LLM 的能力和局限性。
在开始之前,我先说明一下,LLM 很棒,它们实现了那些我没想到能这么快就能实现的事情。但是现在关于 LLM 的炒作太多了,完全没有必要。因此,这篇文章将更多地批判 LLM,而不是夸大它们的智能水平。
#01
什么是 LLM?
LLM 即大语言模型,是一种生成式 AI,它基于大量数据(以 PB 计)进行训练,可以对任何类型的问题生成新颖的回答,这就是 “生成式” 名称的由来。
**这些模型基于 Transformer 架构,需要非常大的 GPU 数据中心。**这儿要提一下,训练 ChatGPT 花费了大约 1 亿美元。这些模型非常庞大,无法安装在任何一台服务器上;它们的参数数量以万亿计。
认识这些模型的方式是将它们视为一个创意生成机器。它们可以生成或给出任何文本查询的近似答案,即使它们在之前没有见过类似的东西。
鉴于模型数据的规模,这些模型在某种程度上捕捉到了语言的本质,在某些情况下,它们甚至学习了训练数据中没有的语言。有些人可能会问,这怎么可能?这被称为 “突现行为”。研究表明,随着模型规模的增加,这些模型可能会发展出全新的能力和功能。我们稍后深入探讨这一点。
#02
如何看待 LLM 和生成式 AI?
众所周知,神经网络是通用函数逼近器。所以,我们知道这些函数确实在尝试对世界建模(假设真实世界有某种函数)。但如果真实世界不仅仅是一个无法建模的函数呢?有很多事情是人类会做但无法解释的。
几年前,我说过,只有当我们能够完美地写下它们时,当前的 AI 系统才能捕获流程或智能行为的细节。
但有很多事情是人类会做但无法描述的;所有这些都是我们世界模型的一部分,而 AI 对此一无所知。语言只是我们思考的一部分,它无法捕捉到我们头脑中世界模型的许多细微之处。
例如,我为什么爱我的狗?我真的没有理由。或者为什么我希望看到贫困消除?所有这些都只是感觉,没有逻辑。即使是我们喜欢的一件好的艺术品,大多数艺术家也无法描述他们是如何创作出来的。
当前的 AI 在某种程度上正在尝试学习不同的数据分布,有些容易,有些复杂。现在有时它可以弄清楚智能任务或活动背后的基本规则。例如,机制可解释性 (Mechanistic Interpretability) 研究揭示了模型可以学习数学算法,但即使是最好的 LLM 也无法进行基本的乘法运算,在这方面它们都失败了。

GPT-4o 在做基本乘法时失败了
如前所述,这些 LLM 可以学习一些基本规则和结构,但有时它们只是通过记忆来回答问题。在深度学习中有一个概念叫 “Grokking”,它指的是网络从记住一切到泛化的过程。测试准确率的突然跳跃是模型 “grok” 的标志。当你训练一个网络时,训练损失会不断减少,但测试损失却不会。但在某个时刻,测试损失会成指数级下降,这时模型就从记忆转向了泛化。
Grokking 表明 LLM 实际上可以学习算法,但我们无法预测模型会记住数据的哪些部分,泛化哪些部分。对此我们无法控制。
LLM 部分是记忆,部分是泛化。现在,对于那些简单且具有明确数据分布的概念,LLM 可能会选择这些结构并创建它们的内部模型,但我们并不确定。
问题仍然存在,我们如何控制这种行为,目前我们没有一个好的答案。我们最接近的是 Bhargava 的 LLM 控制理论。
LLM 控制理论
目前,我们还不能确定 LLM 的内部世界模型足够好,以至于可以创建出类人智能。
LLM 最大的问题在于评估它们,它们甚至非常擅长欺骗研究人员,表现得好像它们很聪明。
这些模型往往看起来一切都正确,甚至表现出泛化能力,但当从不同视角提问时,它们会完全失败,这在一篇名为《LLM 反转诅咒》的论文中有介绍。
论文链接:https://medium.com/aiguys/paper-review-llm-reversal-curse-41545faf15f4
我们将在博客的后面部分再次探讨这个世界模型的概念。
让我们总结一下:
-
我用一个类比来思考 LLM。生物学家可以解释花的细胞和结构,但无法描述它的美丽,但诗人可以描述。很多人类的体验是如此直观,它们不仅仅是一个映射问题。大多数神经网络只是将一组信息映射到另一组信息,这就是为什么它们从根本上缺乏智能的原因。
-
我们不知道 LLM 记住了什么,泛化了什么。目前,没有办法控制这种行为。
-
它们非常善于表现得好像很聪明。
-
使用大量数据,它们可以模仿智能行为,但没有任何真正的计划或推理能力。
#03
神经扩展定律的信奉者
支持 LLM 将变得真正智能的论点基于神经扩展定律。
论文链接:https://arxiv.org/abs/2001.08361
简单来说,该定律基本上表明,随着我们不断增加计算量、数据并增加模型的规模,系统的智能能力将无限增加,并最终超越人类极限。
乍一看,确实如此,但深入挖掘我们可以发现这个定律及其支持论点中存在许多缺陷。该定律认为更大的模型会自动变得具有突现性,这意味着它们会突然发展出新的能力,这些是研究人员未预见或计划的。
就 LLM 而言,它们可能对一些具有良好数据分布的概念有世界模型。但谁说这些世界模型是正确的呢?我们不知道。
目前,大多数 LLM 的行为似乎更像是某种奇怪的记忆形式而非泛化。即使它们有这些世界模型,它们仍然不知道两个内部世界模型如何相互作用。
如果世界模型呈现出两个完全相反的观点,它们有能力解决这个问题吗?它们是否具有引导智能深入分析并找到正确答案的意愿或意识体验?它们能否使用 system 2 intelligence 来辩论自己的知识?
我认为不会。因此,扩展肯定有帮助,但不会到 LLM 成为 AGI 或超智能的地步。
这些更大的模型可以存储大量信息,因此总是显得更智能,但实际上它们可能只是通过记忆而不是泛化来回答。
乍一看,神经扩展定律似乎表明这些模型变得更聪明了,因为它们的基准数量不断增加,但更多时候,它只是模型在基准测试中的行为记忆,它有一个更大的样本分布来形成答案。
不仅如此,甚至基准测试数据也被泄露并被大型 LLM 公司使用,这使得评估泛化与记忆的问题更加困难。
简而言之,LLM 没有任何机制来知道该问什么问题以及何时问。这通过下图得到了很好的表达。当前的 LLM 系统只有在提示者已经了解响应正确性时才似乎能进行推理和计划。
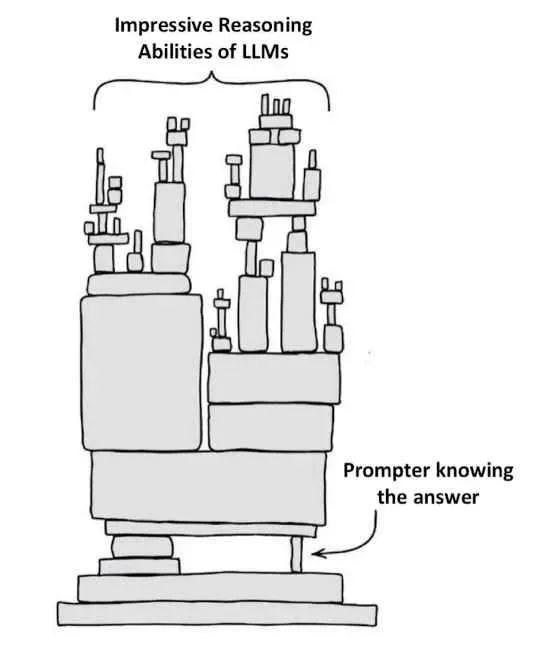
LLM 只有提示者知道答案
#04
LLM 无法做到的事

我强烈建议在查看更多例子之前,先看看这篇关于 LLM 推理和规划能力的文章。在下面的文章中,我们涵盖了许多研究论文,证明了 LLM 的各种低效之处。
链接:https://medium.com/aiguys/can-llms-really-reason-and-plan-50b0ac6addd8
系好安全带,我将展示许多关于 LLM 能力的推文,并向你展示 LLM 在简单任务上表现得多么不稳定。如果它们真的在学习世界模型,就不应该出现这种情况。
PS:很多人确实相信 LLM 正在创建非常复杂的世界模型,无论这些世界模型有什么问题,都将通过扩展自动修复,但我不这么认为。
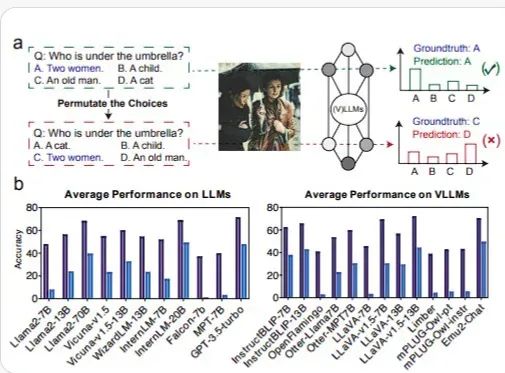
视觉语言模型在改变选项顺序后性能下降(https://arxiv.org/pdf/2402.01781)
如果这些模型像许多人相信的那样智能,那么模型的性能就不应该随着选项顺序的改变而下降。这看起来相当奇怪,因为这并不是难以理解的事情,而且这直接违背了更大的 LLM 正在创建非常复杂的世界模型这一说法,因为它们无法理解顺序在这里没有任何关系。上图显示了当我改变选项顺序时,视觉语言模型的答案发生了变化。
还有另一篇论文显示,所有 LLM 的表现都会随着选项顺序的变化而发生明显变化。而且,不可思议的是,没有一个 LLM 在这一点上表现稳定。即使是像 Yi34b 这样的模型,虽然保持了原位,但准确度也下降了几个百分点。阅读论文以了解更多。
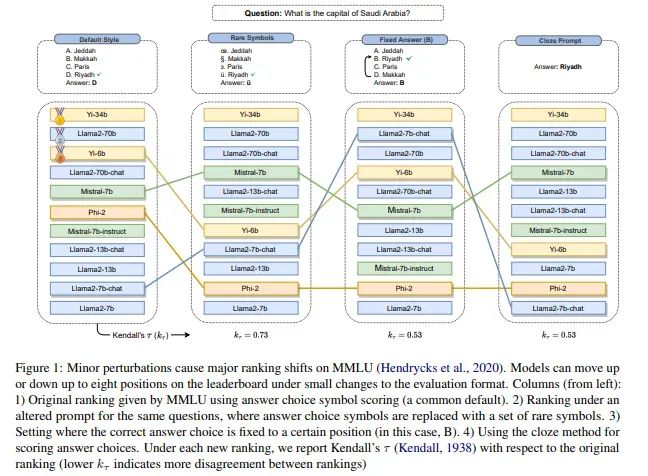
https://arxiv.org/pdf/2402.01781
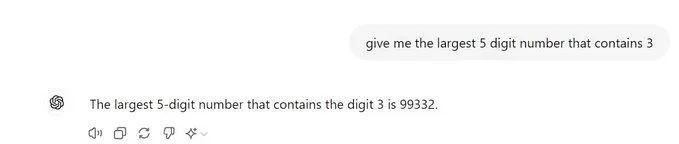
居然无法找到包含 3 的最大五位数。一个五年级学生可以很轻松地回答这个问题。世界模型怎么了?不要告诉我即使看到了这么多数据 LLM 仍然无法完成这种基本的任务。
模型无法理解世界的物理法则。为什么?因为我们希望模型会自动学习世界的物理法则,但我们没有在其中建立任何内在机制来学习物理。这些机器缺乏常识,需要大量数据才能粗略理解世界的物理法则。但视频质量如此之好,我们往往会迷失其中。
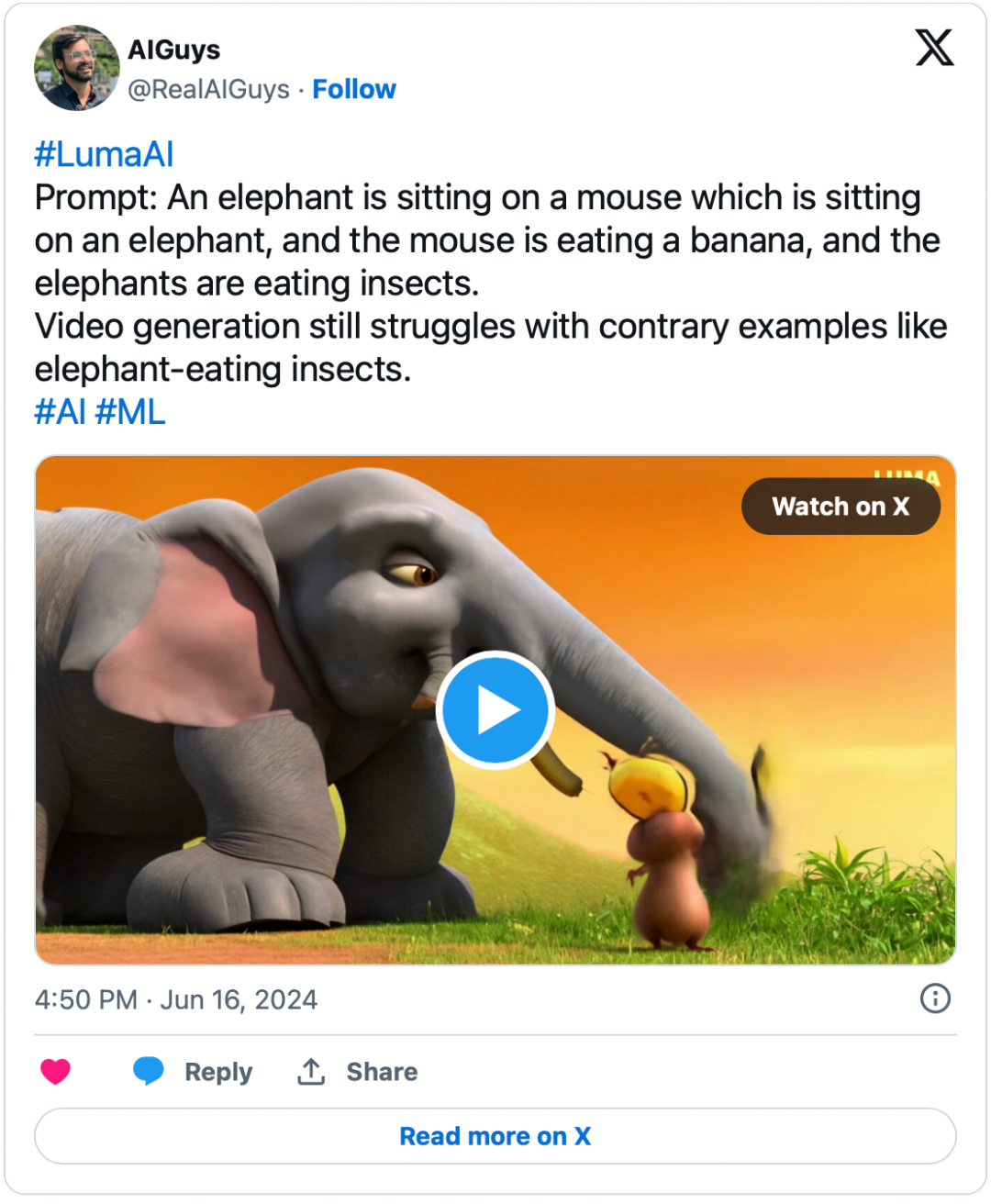
https://x.com/RealAIGuys/status/1802262416912228838
蚂蚁的梦想
当 Sora 发布时,这段详精细到极致的蚂蚁视频在互联网上广为传播。看起来确实很惊人,但等等,你注意到了吗?蚂蚁少了两条腿,这种情况模型经常出错,而且很难在每个生成的视频中找出错误所在。问题不在于模型没有正确绘制剩下的两条腿,而是完全忽略了它们,这表明了与其数据和知识完全不一致。
更多的数据不会解决偏见和知识表示不一致的问题。如果我们不断投放更多数据,而不加以清理和结构化,这些模型不会自动变得聪明。为什么?因为这些模型无法本质上知道什么是对的,什么是错的,它们没有任何层次化的信念系统,它们所做的只是建模数据。
而如果我们真正想要创建一个超级智能的机器,不能仅仅依靠通过数据建模世界。我们需要在这种机器中建立某种真理、美和许多其他概念的范式。
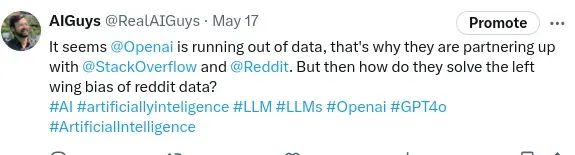
同样的,LLM 在解决带人和山羊过河的简单问题时失败了,它只是与狼、山羊和卷心菜问题混淆了。为什么?因为它多次见到这个例子,只是重复同样的旧信息,而不是思考被问到的问题。
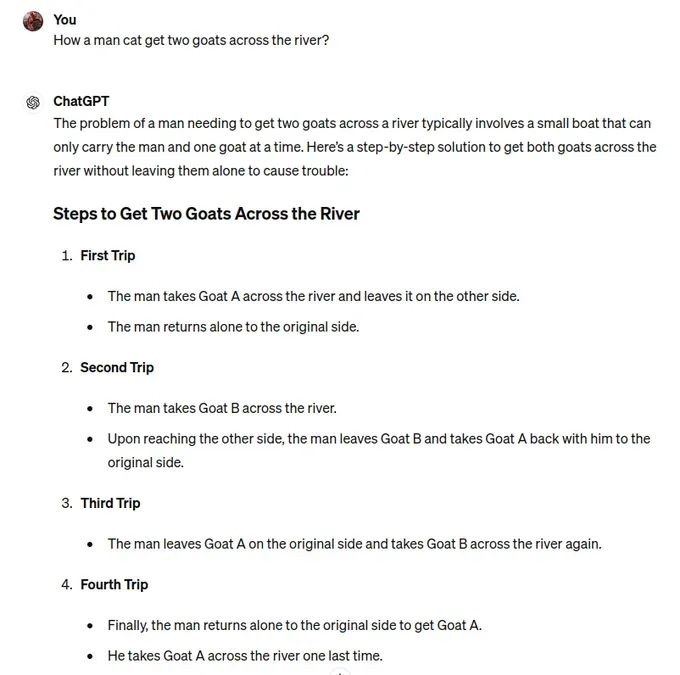
即使是 GPT-4o ,在规划基准测试(神秘积木世界)中得分也几乎为零。这是最有趣的一个,在规划任务中,它们表现得很糟糕,即使是最新的模型。
人们认为它们可以制定计划,但计划只有在可以验证时才算是计划。例如,有一些 AI 旅行规划器,但它们不会检查博物馆是否在特定日期开放,有论文指出这些规划器看起来提供了合理的计划,但如果执行,大多数不会达到预期目标。
我不能不推荐 Rao 教授在规划领域对 LLM 能力的研究工作。
它们不理解人类的知识,而这些公司一直在将它们作为像人类一样智能的工具进行营销。
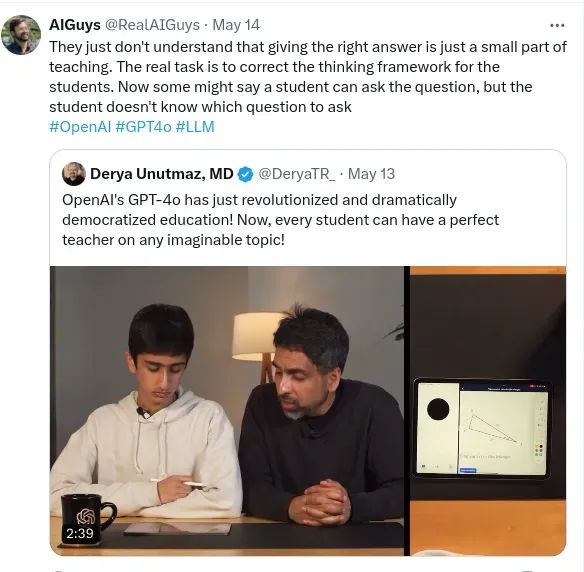
我仍然不知道为什么 LLM 无法进行乘法运算。没有理由 LLM 没有学会其中的规则,它已经看到了数百万个样本,也多次看到了背后的运算。但它就是失败了,如果教它三位数的乘法,它可以学会,但当我要求它进行五位数乘法时它又失败了。
答案是错的
更多的可控性问题。不知为何,模型有时不会预测出访问互联网所需的 Token,即使明确要求它这么做。

Waymo 的自动驾驶汽车失败:一个稍微不同的例子,但我将其包括在内,因为即使是这种系统,基本上也是基于 Transformer 架构的,就像 GPT 和其他 LLM 一样。这表明它们确实不了解现实世界。
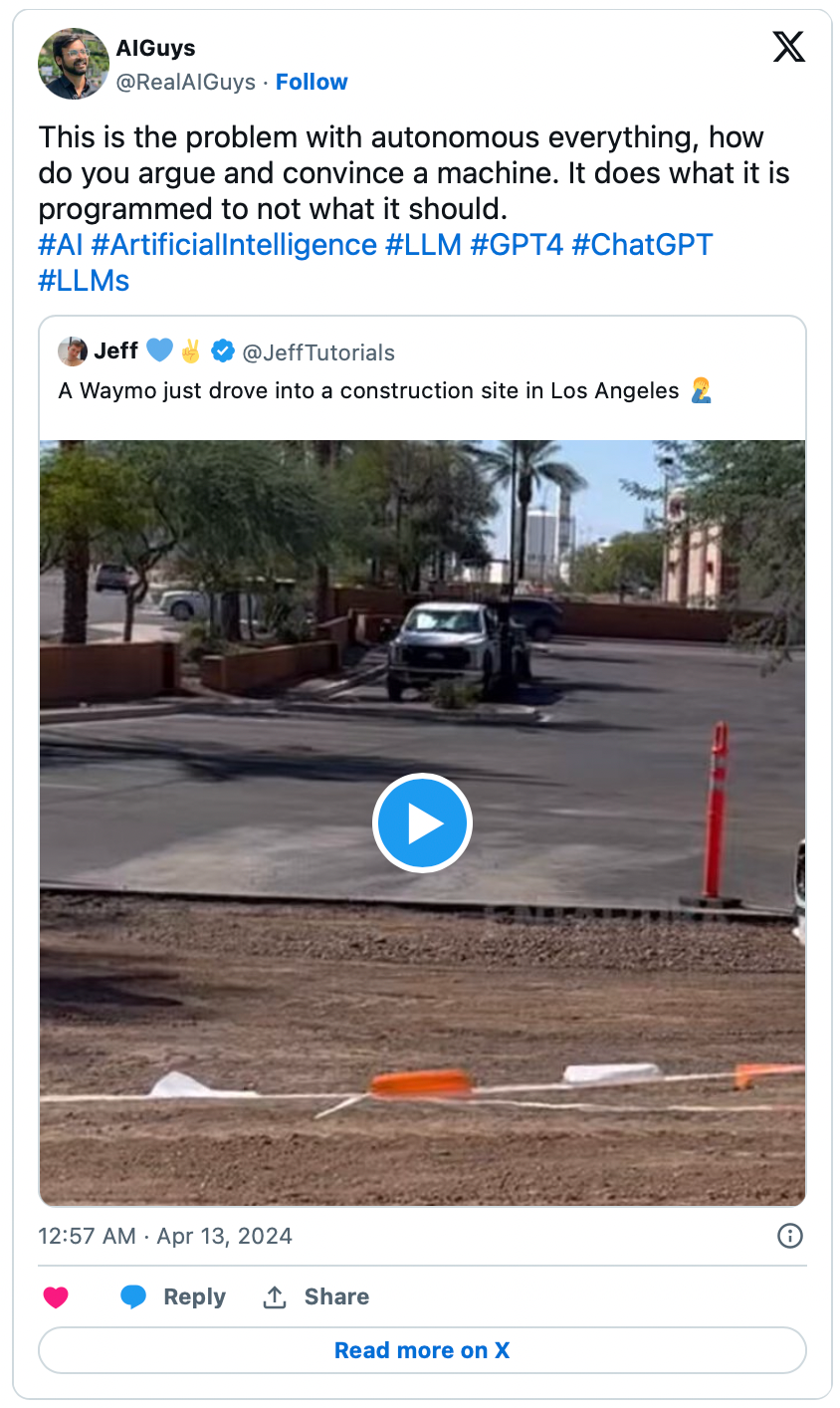
https://x.com/RealAIGuys/status/1778829819238908132
更多这样的简单情况,系统完全崩溃。
https://x.com/andyweedman/status/1382459653863378944
可控性问题。现在有人可能会说这些系统是设计上政治正确的,但我说这是由于架构的性质,它们很难控制,因为它们主要不知道什么是对的,什么是错的,更重要的是,它们不知道在当前词之后的 10 个词会出现什么。由于它们是自回归的,它们只是从样本中选择下一个最高概率的词。
它们永远不会达到 AGI,因为文本世界和现实世界的交互是不同的。文本世界只捕捉到现实世界的本质的一部分。现在有人可能会说 VLM(视觉语言模型)怎么样,我们还没有看到那些问题。我们头脑中的世界模型在于我们与现实世界的互动。
最后说说 ARC-AGI。如果有人告诉你 LLM 实现 AGI,那就问他们为什么它们在 ARC-AGI 上表现如此糟糕。
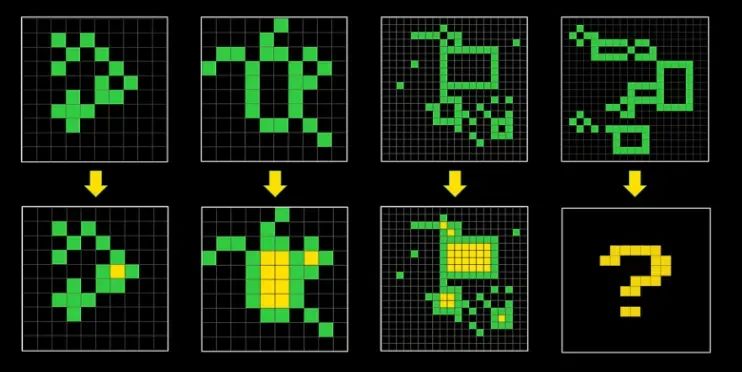
ARC-AGI 的示例挑战。https://arcprize.org/arc
大多数人类可以轻松解决这个任务,但 LLM 却不行。ARC 挑战旨在表明这些 LLM 并没有真正学习,而更多的是在进行上下文行为匹配。34% 是 AI 在这个任务上能完成的。你可以想象我们离目标有多远。
在过去几个月里,ARC-AGI 被广泛讨论。突然间,我们用这个新提议的解决方案达到了 50%,但这有点像是一个黑客手段。ARC-AGI 问题是:对于每个问题,我们有两个输入输出对,然后对于第三个样本,我们产生正确的输出。基于 GPT 的解决方案确实达到了 50%,但对于每个问题,首先它生成 6000 个代码样本,希望能找到原始的转换,如果找到了,显然它会产生正确的答案。
这不是智能,只是穷尽搜索,迟早你会用这种方法找到答案。此外,人工精心设计的提示,LLM 并没有自己弄清楚这些。
我希望所有这些例子已经让你相信 LLM 不能做什么。不要误会我的意思,我喜欢 LLM,但它们既不是 AI 的起点,也不是终点。我希望了解更多 LLM 以外的 AI 系统。
#05
大公司谎言和 AI 社区的问题
大公司非常善于炒作,他们策划了很多令人难以置信的炒作,然后就会有人在社交媒体上到处兜售课程。他们中的大多数人对这个主题一无所知,只是在增加噪音。
任何声称在 6 个月内让你成为专家的人都是在撒谎。
我非常清楚地记得,直到几个月前,提示工程(Prompt Engineering)都很火热。整个就业市场充斥着提示工程师的角色,但现在已经不这样了。提示工程既不是艺术也不是科学,只是一个聪明的汉斯效应,人类为系统提供必要的上下文,以便它更好地回答问题。人们甚至写了书 / 博客,如《最好的 50 个提示》来充分利用 GPT,等等。
但是大规模实验清楚地表明,没有一种提示或策略适用于所有类型的问题,只是一些提示在单独分析时表现得更好,但在综合分析时却是碰运气。
在过去两年左右的时间里,我看到了很多生成式 AI 的概念验证,老实说,超过 90% 都是垃圾、无用的或者是噱头。
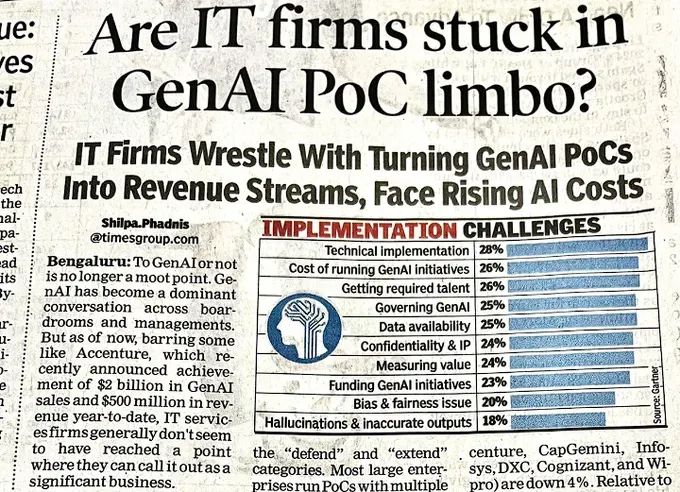
https://x.com/RealAIGuys/status/1808414773316292765
这些概念验证(POC)无法产生足够的收入来维持自己。
我给你几个无用的 POC 的例子。
-
一个在办公室里可以对话的 AI 化身。听起来很酷,但实际并不好,为什么呢?没有人想被你的问题打扰,所以你应该通过打字而不是说话来与系统互动。
-
一个基于 LLM 的聊天机器人,用来打破作家的思维阻塞,这个想法有些道理。但创始人没有理解问题。作家的思维阻塞是通过提出深刻的不同角度的问题来解决的,但 LLM 主要是设计来回答问题,而不是生成新颖的问题。LLM 在生成任何超越政治正确性或寻找新观点的问题方面表现很差。
-
关系机器人,绝对是一场灾难,这些人不了解人类的细微差别和需求。即使长时间与真人通过视频交谈,也会变得表面化。
-
用于银行业聊天机器人的生成式 AI。你不需要基于生成式 AI 的聊天机器人,它引入了不必要的问题,需要大量的保护措施。创建一个只关注银行相关问题的简单聊天机器人会更好。
-
用于物体跟踪和检测的大型视觉模型。视觉语言模型在定位方面仍然很差。如果我问它是否确定,它肯定会出问题。
Yannick 对生成式 AI 在法律中的应用以及为什么大多数公司无法理解这一点提出了很好的观点。
对大公司的信任问题。
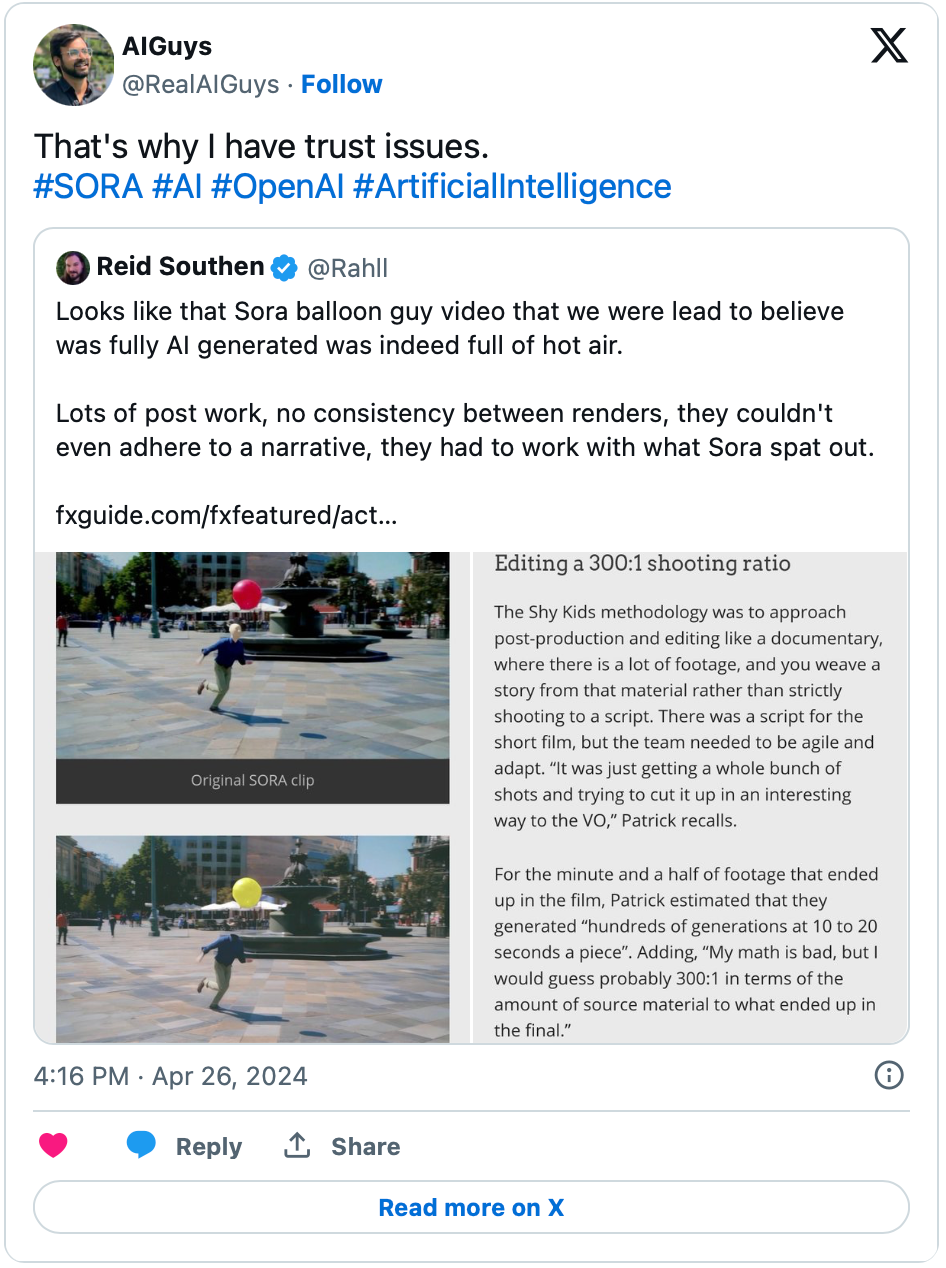
Sora Text2Video 的谎言
Devin AI 软件工程师是另一个谎言。这个时长半小时的视频分析了 Devin AI 如何愚弄了互联网上的所有人。
Google 的 Gemini 谎言。整个营销视频都是假的。
但比这些大公司的谎言更糟糕的是那些传播关于 AI 的虚假、无知和愚蠢想法的人。
我多次发帖指出,LinkedIn 是最糟糕的 AI 相关内容平台之一。每个人在那里都是专家。主要问题是每天都有大量人发布内容只是为了增加互动。他们从未发布过一个自己的想法,但像 LinkedIn 这样的平台会奖励这种行为。没有衡量原创性的标准。LinkedIn 上很多内容纯粹是 AI 生成的,没有原创性。
这导致了一个更大的问题,下一代语言模型被灌输了非常低质量的数据。我称之为语言和互联网的 “糟粕化”(借用 Dr.Tim Scarfe,MLST 的词语)。
**我恳请每一个人停止发布 AI 生成的内容,只有当你有自己的想法时再发布。**我看到很多人确实已经形成了每天发布 3-4 条内容的习惯,还有很多视频敦促人们这样做以获得更多关注,就是这些糟糕的人污染了 AI 领域。
停止使用生成式 AI 进行你的 POC,大多数时候你不需要它。尝试从基本原理构建产品。生成式 AI 应该是最后的手段,而不是首选。
我对 LLM 最大的意见是我们在它上面投入的资源。
仅在 LMSYS 聊天机器人竞技场,我们就有 114 个 LLM。相信我,这可能还不到现有 LLM(从头训练)的 10%。除了前五名,没人使用这些 LLM,它们只是在积灰,它们几乎没有比更大更有名的 LLM 提供更多的优势。
训练 LLM 是一个耗资百万美元的事情,在大多数情况下是相当无用的。Meta、OpenAI 和许多其他公司花费了数十亿美元,而随着时间的推移,收益正变得越来越少。
除非你从根本上改变了架构,否则停止制造新的 LLM。仅仅改变一些数据,不会创造出一个具有全新能力的 LLM。
甚至 LLM 的基准测试也已经被腐败了,我们甚至不知道现在哪个模型真正排在第一。
我还看到,即使是公开可用的 LLM,随着时间的推移也在不断退化,也许他们是故意的,这样他们就可以推出新模型并收费,当然这只是我的个人猜测。
LLM 已经渗透到每个领域,甚至是我们不需要它们的地方。我们看到了很多带有 AI 生成摘要的论文,这真的很糟糕。
我对一般 AI 社区和这些大科技公司有很多怨言,让我们进入下一部分。
#06
LLM 的更大问题
更大的问题是,即使是研究人员也相当分裂,我见过很多论文不断地驳斥之前论文的结果。这表明人们在发布模型或论文之前没有尽职调查。
例如,在《Sparks of AGI》这篇论文中提出的很多主张后来被证明是半真半假或错误的。这只是误导的一个例子,还有很多类似的论文。这主要是因为每个人都急于搭上 AI 的快车,发布不成熟的产品和研究。Google 为了追上 OpenAI 的步伐,在没有适当测试的情况下发布模型,结果惹下很大麻烦,因为他们的模型是高度种族主义的。

我们不断写新论文,显示这些模型具有这样的或那样的能力,但这不是真的。
为什么 RAG 和 AI Agent 变得流行起来?
RAG 管道变得如此出名是有原因的,我们在某种程度上试图通过投入大量数据来模仿整个推理过程,希望 LLM 会进行上下文学习。
我知道 RAG 有助于让 LLM 回答关于私人数据的问题。但它也有助于模仿智能行为,请记住,它仍然是在模仿,而不是推理。
但是它是怎么做到的呢?RAG 帮助 LLM 使用特定或私人数据回答问题。虽然这些模型看起来在模仿智能行为,但它们并没有真正推理或理解;它们遵循其训练数据中的模式和规则,类似于中文房间(Chinese Room Argument),即一个人似乎通过在没有实际理解的情况下遵循规则来理解语言。
RAG 通过从数据库中检索相关信息并使用它来生成响应。这使 LLM 能够通过记忆和应用推理步骤来给出准确且上下文相关的答案,而无需真正理解。这种方法特别适用于高效地回答涉及私人数据的问题。
那么 AI Agent 呢?我还看到 AI Agent 突然增加,但它们并不比 LLM 更聪明,它们只是为 LLM 带来更多的上下文,以检索更复杂的智能模式,并提供使用工具的能力,这些可能直接在 LLM 中缺失。
AI Agent 很棒,但绝对不比 LLM 更聪明,这只是巧妙地使用不同的技术,如信息匹配和工具使用。它们仍然需要处理为什么响应会因提示的细微变化而完全改变的问题,或者如果两个 Agent 在同一逻辑决策上得出不同结论会怎样。
#07
我对 LLM 能力的看法
我已经使用这些系统很长时间了。甚至在 ChatGPT 发布之前就已经在使用了。随着时间的推移,我发现了这些系统的许多限制。在我的日常工作中,我每天都会遇到 LLM 推理的限制,但它对我来说仍然非常有用。因此,在写了大量文章和阅读了几篇研究论文后,让我告诉你我对 LLM 的看法。
-
LLM 给出非常通用的回答。当要求它给出详细说明时,它表现得非常糟糕。
-
当你要求它给出一些不受欢迎的意见,特别是当它在政治上不正确时,它表现得非常糟糕。
-
它们不能从不同的角度写作,特别是从坏人或反派的角度。
-
它们擅长模仿风格,但它们写的内容平庸。AI 研究人员对此行为感到惊讶,我们认为模仿风格对 LLM 来说会很难,但实际上,模仿风格很容易,但模仿论证的水平和逻辑流对这些系统来说要困难得多。
-
由于它没有信仰,它无法区分结论的好坏。
-
它不知道什么时候该停止。LLM 无法进行自我反思,只是看起来在进行自我反思。
-
当我们谈论多目标问题时,它们表现得非常糟糕。
-
如果你问它们一个非常著名的问题,但版本不同时,它们往往会给出错误答案。无论是第 n 次旋转还是农夫、山羊和草问题。
-
如果你问它们,“你确定吗?” 它们会改变答案。
-
它们可能不是随机鹦鹉,但它们不像我们想象的那么智能。它们更像是风格(有时包括智能行为和过程)模仿机器,具有一些理解能力。
-
它们非常适合创意生成。在 LLM-Modulo 框架中可能会非常有效。
-
当我开始在训练数据的极端操作时,它们真的很挣扎。
-
它们非常适合重复的日常任务。
-
它们在查找某些东西和纠正给定文本中的语法错误方面可以提供很好的帮助。
-
当遇到困难问题时,即使明确要求它们改变答案,它们也会不断重复同样的答案。感觉它们陷入了循环。
这篇文章先写到这里,下一篇,我将更深入地探讨下一阶段的智能系统是什么样子的,感知问题的本质,智能的本质,以及人类大脑是如何工作的。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









