






大模型(Large Models)的训练是近年来人工智能领域的核心技术之一,尤其是在自然语言处理、计算机视觉等任务中,如 GPT、BERT 等模型的成功背后,离不开复杂的训练过程。本文将为你介绍大模型是如何训练的,包括数据准备、模型架构、训练方法和硬件支持等方面。
1. 数据准备:海量数据的基础
大模型的训练需要大量的数据,因为它们需要从海量信息中学习模式和规律。数据的质量和数量对模型的性能有着直接影响,以下是数据准备的几个关键步骤:
数据收集:大模型通常依赖于广泛的文本数据,像 GPT-3、BERT 这样的大模型,会从互联网上抓取大量公开可用的数据,涵盖百科、新闻、社交媒体、图书等多种文本来源。
数据预处理:收集到的数据需要进行清洗和整理。比如,去除重复信息、纠正拼写错误、过滤掉不相关或低质量的数据。还需要将文本转换为模型可以理解的格式,如将文字转化为数字表示。
分词和标记化:语言模型会将输入的文本进行分词,转化为一个“词片段”或“子词”。这一过程叫做标记化(tokenization),比如“学习”可以被拆解成“学”和“习”,或按更小的单元来处理。这是大模型理解语言的第一步。
2. 模型架构:基于 Transformer 的核心
自从 2017 年Transformer架构被提出后,几乎所有的大模型都采用了这种架构。Transformer 的核心是自注意力机制(Self-Attention),它允许模型在处理一个单词时,可以“关注”到句子中的其他单词,这使得模型能够更好地理解上下文和复杂的语言关系。
编码器与解码器:Transformer 包括编码器和解码器部分。比如,BERT 模型使用了只包含编码器的部分,它通过双向注意力机制同时考虑上下文信息,适合于理解任务。而 GPT 系列模型则使用了只包含解码器的部分,它更擅长生成文本。
层数和参数量:大模型之所以被称为“大”,主要是因为其包含了极多的层数和参数。比如,GPT-3 拥有 1750 亿个参数,这意味着模型拥有巨大的“容量”去学习复杂的模式和语义。
3. 训练方法:预训练与微调
大模型的训练通常分为两个阶段:预训练(Pre-training)和微调(Fine-tuning)。
预训练:在预训练阶段,模型通过海量的无标签数据进行自监督学习。比如,BERT 使用了掩码语言模型(Masked Language Model)任务,它会随机掩盖一些词,然后让模型去预测这些被掩盖的词是什么。通过这种方式,模型学会了丰富的语义表示。
微调:预训练后的模型会在特定的任务上进行微调。例如,在情感分析、机器翻译或文本分类任务上使用带标签的数据进行训练。这一步骤使得预训练的大模型能够适应各种下游任务。
4. 硬件支持:分布式计算和并行化
大模型的训练需要强大的计算资源,特别是当模型参数量达到数十亿甚至上千亿时,单台计算机已经无法承担训练任务。因此,分布式计算和并行化技术成为大模型训练的关键。
GPU 和 TPU:图形处理器(GPU)和张量处理单元(TPU)是深度学习模型训练的主要硬件支持。它们可以并行处理大量的矩阵运算,这大大加速了模型的训练过程。像 GPT-3 这样的大模型通常在数千块 GPU 或 TPU 上进行训练。
分布式训练:由于数据和模型参数的规模巨大,模型的训练会采用分布式训练方法,将计算任务分布到多台机器上并行处理。常用的技术包括数据并行(Data Parallelism)和模型并行(Model Parallelism)。
数据并行:将训练数据划分成不同的部分,分别在多台机器上进行训练,每台机器有一个完整的模型副本。
模型并行:将模型本身划分成不同的部分,每台机器负责训练模型的不同部分,这种方法常用于处理非常大的模型参数。
5. 训练挑战:时间、能耗与优化
大模型的训练是一个复杂且昂贵的过程,通常需要耗费数周甚至数月的时间,成本高达数百万美元。除了硬件成本外,训练过程中还面临一些技术挑战:
梯度消失与爆炸:深度模型中可能会出现梯度消失或爆炸的问题,特别是在非常深的神经网络中。这会导致模型无法有效训练。为了解决这个问题,常常采用梯度裁剪或优化算法的调整。
超参数调优:模型的训练涉及到大量的超参数,如学习率、批量大小等。这些超参数的选择对训练效果至关重要。通常,研究人员会进行大量实验,测试不同超参数组合的效果。
能耗问题:大模型的训练消耗大量能源,也引发了对环境影响的讨论。为了应对这一问题,研究人员正在开发更高效的模型架构和算法,以减少能耗。
6. 未来发展方向:高效训练与模型压缩
随着大模型越来越大,研究人员也在探索如何提高训练效率以及如何压缩模型,使其在不显著降低性能的前提下变得更轻量、更高效。
模型蒸馏(Model Distillation):通过训练一个较小的模型去模仿大模型的行为,使得小模型能够以更少的计算资源实现接近大模型的性能。
稀疏训练(Sparse Training):稀疏训练方法通过减少模型中的不必要连接,降低模型的计算复杂度。稀疏性允许模型在不牺牲太多性能的情况下大幅度减少参数数量。
混合精度训练:为了提高计算效率,研究人员使用混合精度训练,即将部分计算转换为更低精度的浮点数,以减少内存占用和计算量。
总结来说,大模型的训练过程涉及海量数据、复杂的模型架构、高效的硬件支持和优化的训练方法。随着技术的不断进步,大模型将变得更加强大和高效,推动 AI 在更多领域取得突破。
网络安全学习路线&学习资源
网络安全的知识多而杂,怎么科学合理安排?
下面给大家总结了一套适用于网安零基础的学习路线,应届生和转行人员都适用,学完保底6k!就算你底子差,如果能趁着网安良好的发展势头不断学习,日后跳槽大厂、拿到百万年薪也不是不可能!
初级网工
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)

恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
零基础入门,建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习; 搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime; ·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完; ·用Python编写漏洞的exp,然后写一个简单的网络爬虫; ·PHP基本语法学习并书写一个简单的博客系统; 熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选); ·了解Bootstrap的布局或者CSS。
8、超级网工
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,贴一个大概的路线。感兴趣的童鞋可以研究一下,不懂得地方可以【点这里】加我耗油,跟我学习交流一下。
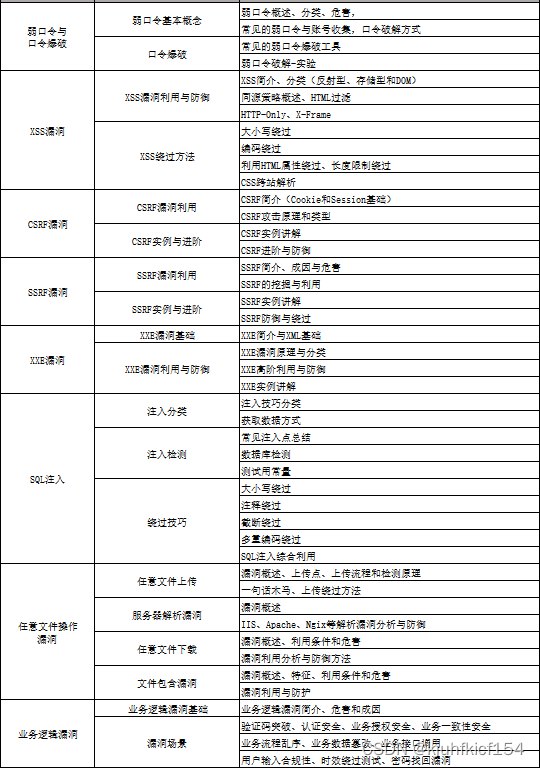
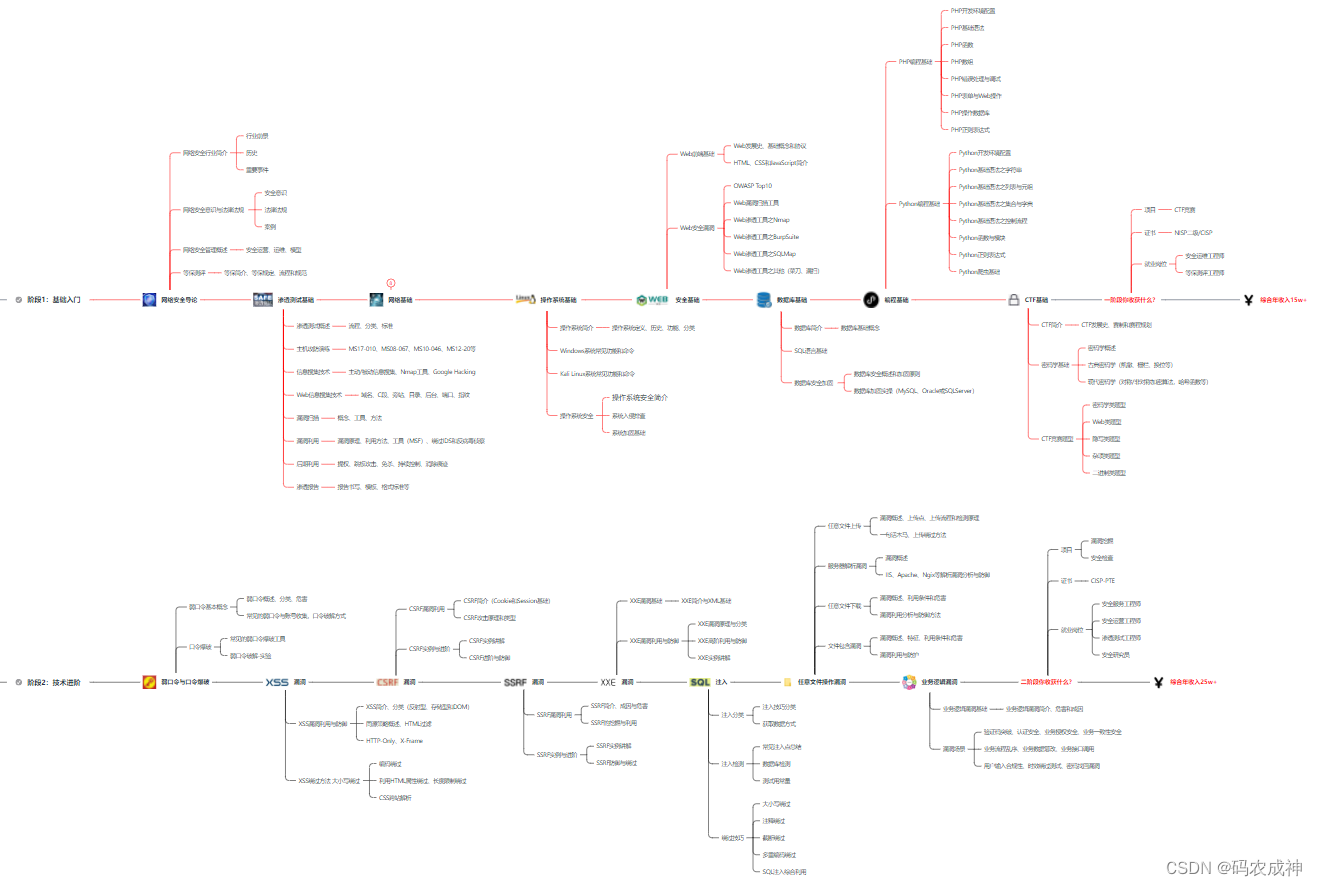
网络安全工程师企业级学习路线
如图片过大被平台压缩导致看不清的话,可以【点这里】加我耗油发给你,大家也可以一起学习交流一下。
一些我自己买的、其他平台白嫖不到的视频教程:

需要的话可以扫描下方卡片加我耗油发给你(都是无偿分享的),大家也可以一起学习交流一下。
网络安全学习路线&学习资源
结语
网络安全产业就像一个江湖,各色人等聚集。相对于欧美国家基础扎实(懂加密、会防护、能挖洞、擅工程)的众多名门正派,我国的人才更多的属于旁门左道(很多白帽子可能会不服气),因此在未来的人才培养和建设上,需要调整结构,鼓励更多的人去做“正向”的、结合“业务”与“数据”、“自动化”的“体系、建设”,才能解人才之渴,真正的为社会全面互联网化提供安全保障。
特别声明:
此教程为纯技术分享!本书的目的决不是为那些怀有不良动机的人提供及技术支持!也不承担因为技术被滥用所产生的连带责任!本书的目的在于最大限度地唤醒大家对网络安全的重视,并采取相应的安全措施,从而减少由网络安全而带来的经济损失!!!

















 1676
1676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









