






大语言模型需要消耗巨量的GPU内存。有可能一个单卡GPU跑推理吗?可以的话,最低多少显存?
70B大语言模型仅参数量就有130GB,仅仅把模型加载到GPU显卡里边就需要2台顶配100GB内存的A100。
进行推理时,还需要加载整个输入序列,在显存中进行复杂的“注意力”计算。这个注意力机制内存量是输入长度的平方级别的。在模型的130GB基础之上还需要大量的内存。
究竟是什么样的技术可以节省这么多的内存,甚至4GB单卡跑推理呢?
注意,这里的内存优化技术,不需要任何损失模型性能的量化和蒸馏,剪枝等模型压缩。
今天一文把各种大模型的极致内存优化关键技术讲清楚。
如果您是身家百卡的土豪,请自行跳过。。。

文章最后我们也开源了推理的代码,免费取用!
01
分层推理
最关键的一个技术是分层推理。其实就是计算机领域最基本的divide and conquer思路。

我们先来看一下大语言模型的模型架构。今天的大语言模型,都是采用Google在《Attention is all you need》论文中提出的Multi-head self-attention结构。也就是后来大家称为transformer的结构。
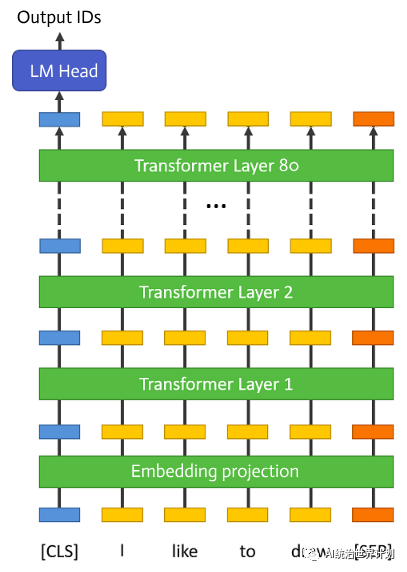
大语言模型开始是一个embedding投影层。这之后有80层结构完全相同的transformer层。最后是归一化和全连接层,预测输出token ID的概率。
执行推理的时候一层一层顺序执行。上一层的输出会作为下一层的输入。同一时间只有一层在执行。
因此完全没必要把模型的所有层维持在显存中。可以执行到哪一层的时候从硬盘加载哪一层,进行所有的计算。计算完成就可以把内存完全释放掉。
这样其实显存的需要模型上就仅仅是大约一层transformer的参数量,整个模型的1/80,大约1.6GB。
另外显存中还有一些模型的输出结果缓存,包括最大的是用来避免重复计算的KV cache。
做一个简单的计算,对于70B大模型,需要的kv cache缓存量约为:
2 * 序列长度 * 模型层数 * 注意力头数 * 向量维数 *
序列长度为100时,这个缓存 = 2 * 100 * 80 * 8 * 128 * 2 = 30MB的显存。
根据我们的监控,推理过程全程不超过4GB的显存占用!
02
单层推理优化——flash attention
Flash attention可能是大语言模型发展到今天最重要,最关键的优化之一。
今天所有的各种大语言模型层出不穷,其实底层代码基本上变化不大,最大的一个改进就是flash attention。
flash attention的优化思想其实并不是首创的,要提到另一篇paper《Self-attention Does Not Need O(n^2) Memory》。
本来self attention机制是需要O(n^2)内存的。(n为序列长度)。
这篇论文提出其实我们并不需要保存O(n^2)个中间结果。可以序列执行,过程中不断更新一个中间结果,其他全部丢掉。可以把内存降低到O(logn)。
Flash attention本质上也是类似,内存复杂度其实略高,为O(n),但是flash attention深度优化了cuda高速显存访问次数,从而可以数倍提升推理和训练速度。
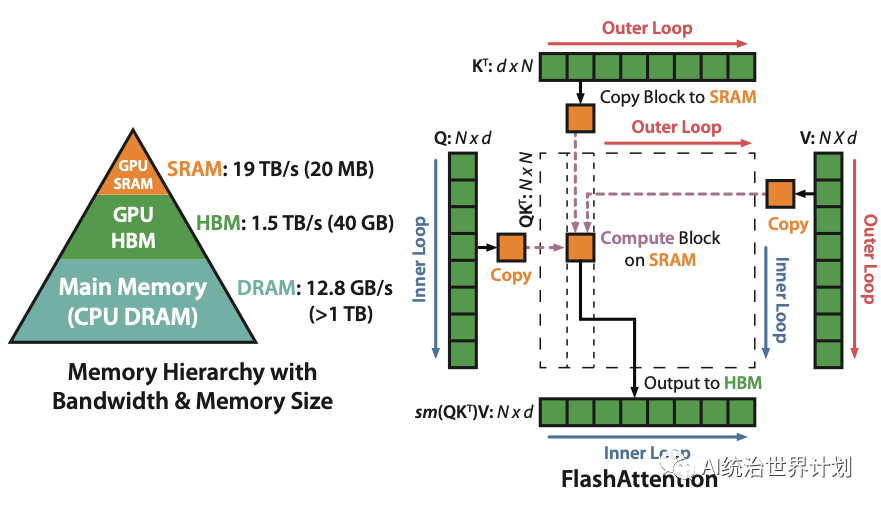
如上图所示,本来原始的self attention计算保存O(n^2)的中间结果。flash attention把计算拆成很多小block,一个block一个block的计算,内存占用降低到一个block的大小。
03
模型文件拆解
原始的模型文件一般会分拆成若干块(shard)存储。每个shard常见的大小是10GB。
我们执行会按照transformer层进行执行。每层只有1.6GB。如果基于原始的shard大小,执行每一层都需要重新加载整个10GB文件,但只读取其中的1.6GB。
这个过程会浪费很多的内存加载和硬盘读取。而硬盘读取速度其实是整个推理过程最慢的瓶颈部分,我们希望尽量降低硬盘读取。
因此我们会首先将原始huggingface模型文件进行预处理,按照每一层拆解存储。
存储我们会用到safetensor技术(https://github.com/huggingface/safetensors)。
safetensor会保证存储格式和加载到内存中的数据格式尽量接近,另外会通过内存映射直接加载文件,保证模型加载速度最大化。
04
meta设备
实现过程我们使用了huggingface accelerate提供的meta device功能(https://huggingface.co/docs/accelerate/usage_guides/big_modeling)。
meta device是一种虚拟的设备。专门为运行超大规模的模型设计。当你通过meta device加载模型的时候,模型数据并没有真的被读取进来,而仅仅是代码加载了。内存占用为0。
你可以在运行的时候动态的把模型的一部分从meta device转换为真实设备如CPU或GPU。这时模型才真正加载到显存。
使用with init_empty_weights()就可以让模型通过meta device进行加载。
from accelerate import init_empty_weightswith init_empty_weights():my_model = ModelClass(...)
05
开源代码
我们开源了全部代码——AirLLM。
可以在anima github中找到:https://github.com/lyogavin/Anima/tree/main/air_llm。
使用过程非常简单,首先安装package:
pip install airllm然后就可以通过类似普通transformer模型的方式直接进行分层模型推理:
from airllm import AirLLMLlama2MAX_LENGTH = 128# could use hugging face model repo id:model = AirLLMLlama2("garage-bAInd/Platypus2-70B-instruct")# or use model's local path...#model = AirLLMLlama2("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")input_text = ['What is the capital of United States?',]input_tokens = model.tokenizer(input_text,return_tensors="pt",return_attention_mask=False,truncation=True,max_length=MAX_LENGTH,padding=True)generation_output = model.generate(input_tokens['input_ids'].cuda(),max_new_tokens=2,use_cache=True,return_dict_in_generate=True)output = model.tokenizer.decode(generation_output.sequences[0])print(output)
此代码我们在16GB显存的Nvidia T4 GPU测试通过。测试推理过程全程不超过4GB的显存占用。
注意,如果用比较低端的GPU,比如T4运行过程还是比较慢的。不太适合需要用户交互的场景,比如chatbot。比较适合一些离线的数据分析场景比如RAG,PDF分析之类的。
另外,目前仅支持Llam2内核的模型。如果有需要其他模型支持的可以评论留言!
06
训练可以单卡跑70B吗?
推理可以通过分层优化,那么训练可以类似的单卡跑吗?
看出来了,你是真穷。

因为推理的特点,每次执行下一层transformer的时候,仅仅需要上一层的输出,因此可以分层执行,仅保留有限的数据。
训练需要的数据则更多。训练过程需要首先计算前向传播,计算每一个层每一个tensor的输出结果。然后进行后向传播,计算每一个tensor的梯度。
梯度的计算需要保存之前前向的每一层,每一个tensor的结果,因此没办法通过分层执行的方法节省内存。
当然还有一些其他的技术,比如gradient checkpointing,可以达到比较类似的效果。
如果大家想了解怎么通过gradient checkpointing显著降低训练内存需求,可以在评论区留言告诉我们。
07
本文很多代码参考了kaggle社区的SIMJEG的代码:https://www.kaggle.com/code/simjeg/platypus2-70b-with-wikipedia-rag/notebook。感谢kaggle社区的参与者的贡献!
我们会持续开源分享AI领域最新最有效的新方法,新进展,为开源社区做贡献。请关注我们。

















 2379
2379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









