







目录
YOLOv3 网络架构
论文原址:https://arxiv.org/pdf/1804.02767
Code:https://github.com/ultralytics/yolov3
YOLO官方模型总览:https://pjreddie.com/darknet/yolo/#google_vignette
YOLOv3 目标检测算法由 Joseph Redmon 和 Ali Farhadi 在 2018 年提出,是一种用于实时目标检测的深度学习算法。YOLOv3 网络的模型架构如下:
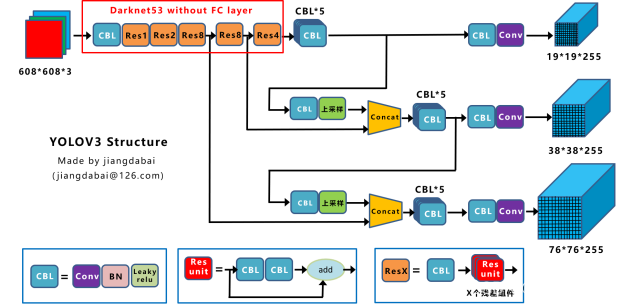
CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
Concat:张量拼接,会扩充两个张量的维度,例如26*26*256和26*26*512两个张量拼接,结果是26*26*768。Concat和cfg文件中的route功能一样。
add:张量相加,张量直接相加,不会扩充维度,例如104*104*128和104*104*128相加,结果还是104*104*128。add和cfg文件中的shortcut功能一样。
YOLOv3的网络架构基于其前身进行了改进,主要特点包括:
- 主干网络:采用Darknet-53作为其主干网络,这是一个53层深的卷积神经网络,由多个卷积层和残差块组成,这些残差块有助于训练更深的网络而不会遭遇梯度消失问题。但YOLOv3中并没有使用Darknet-53的全连接层,并且为了降低池化带来的梯度负面效果,作者直接摒弃了池化层,直接使用步长为2的卷积来进行下采样。
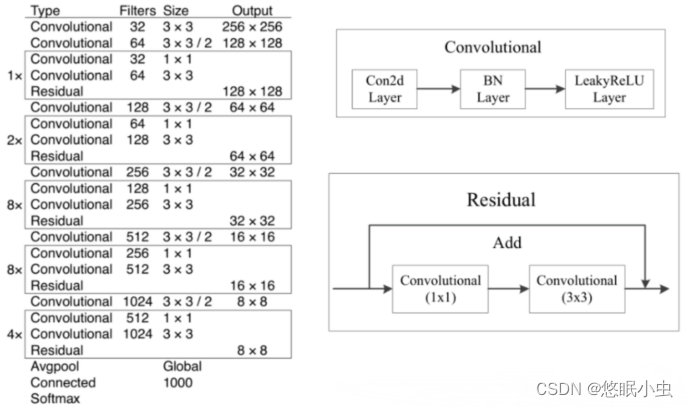
- 多尺度预测:在基础网络的末端设计了三个不同的输出层(通常称为YOLO层),分别在不同尺度的特征图上进行预测。这样做是为了提高对不同大小目标的检测能力。每个输出层负责预测一组边界框及其相应的类别概率和置信度。
- 锚框:使用了一组更丰富的预定义锚框(先验框),这些框具有不同的形状和比例,帮助模型适应多种尺寸的目标。(
负责大物体、
负责中物体、
负责小物体)


- 特征融合:为了进一步增强对小目标的检测,在不同尺度的预测层之间进行了特征融合。这涉及上采样某些特征图并与较早层的高分辨率特征图相加,以结合深层次的语义信息和浅层次的位置信息。
YOLOv3 检测流程
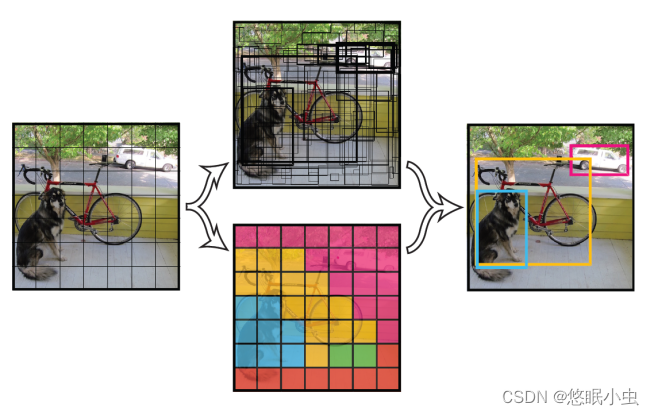
简单来说,YOLOv3就是把一个图像划分成不同的网格,每个网格点负责一个区域的检测,只要物体的中心点落在这个区域,这个物体就有这个网格点来确定。(每个网格由其左上角的那个网格点负责,等同于每个网格点负责其右下区域的网格。锚点是每个网格的左上角)
下面介绍详细检测流程:
三个特征层的提取
- (52,52,256) 特征层:这是网络中较浅层次的特征图,提供了更多的空间细节,适用于检测图像中较大的目标。
- (26,26,512) 特征层:位于中间层次,提供了中等级别的空间细节和语义信息,适用于中等大小的目标。
- (13,13,1024) 特征层:这是最深的特征层,提供了最强的语义信息,但空间分辨率最低,适用于检测较小的目标。
特征层的处理与上采样
(13,13,1024) 特征层:首先,该特征层会经过几次卷积操作来进一步提取特征。然后,通过 1x1 卷积层减少通道数,并通过 3x3 卷积层进一步提取特征。最后,使用上采样(或称为转置卷积)将特征图的尺寸扩大两倍,变为 (26,26,512)。
特征层的拼接与再次处理
(26,26,512) 特征层:将上采样后的特征图与 Darknet-53 中原有的 (26,26,512) 特征层拼接,形成 (26,26,1024) 的特征图。然后,再次经过卷积操作,并通过 1x1 和 3x3 卷积层进行特征提取。最后,同样使用上采样将其尺寸扩大两倍,得到 (52,52,256) 的特征图。
生成预测结果
(13,13,75)、(26,26,75)、(52,52,75) 特征层:每个尺度的特征图都会通过一个 1x1 卷积层来预测边界框的数量、每个边界框的类别概率、目标的置信度等。这里的 75 是每个网格单元预测的边界框数量乘以每个边界框的参数数量。例如,如果每个网格单元预测 5 个边界框,每个边界框有 5 个参数(中心坐标 (x, y)、宽度 w、高度 h 和置信度 c),则 75 = 5 * 15。计算公式如下:
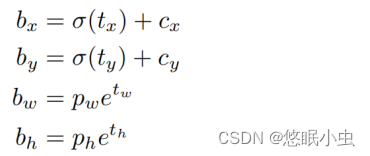
:该点所在网格的左上角距离最左上角相差的格子数。
:先验框的边长
:目标中心点相对于该点所在网格左上角的偏移量
:预测边框的宽和高
非极大值抑制(NMS)
NMS的本质是搜索局部极大值,抑制非极大值元素。非极大值抑制,主要就是用来抑制检测时冗余的框。因为在目标检测中,在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,所以需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。
算法流程:
- 对所有预测框的置信度降序排序
- 选出置信度最高的预测框,确认其为正确预测,并计算他与其他预测框的IOU
- 根据步骤2中计算的IOU去除重叠度高的,IOU > threshold阈值就直接删除4.剩下的预测框返回第1步,直到没有剩下的为止
YOLOv3 网络搭建
Backbone网络搭建:Darknet-53
import math
from collections import OrderedDict
import torch.nn as nn
#---------------------------------------------------------------------#
# 残差结构
# 利用一个1x1卷积下降通道数,然后利用一个3x3卷积提取特征并且上升通道数
# 最后接上一个残差边
#---------------------------------------------------------------------#
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes[0], kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes[0])
self.relu1 = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(planes[0], planes[1], kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes[1])
self.relu2 = nn.LeakyReLU(0.1)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out += residual
return out
class DarkNet(nn.Module):
def __init__(self, layers):
super(DarkNet, self).__init__()
self.inplanes = 32
# 416,416,3 -> 416,416,32
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes)
self.relu1 = nn.LeakyReLU(0.1)
# 416,416,32 -> 208,208,64
self.layer1 = self._make_layer([32, 64], layers[0])
# 208,208,64 -> 104,104,128
self.layer2 = self._make_layer([64, 128], layers[1])
# 104,104,128 -> 52,52,256
self.layer3 = self._make_layer([128, 256], layers[2])
# 52,52,256 -> 26,26,512
self.layer4 = self._make_layer([256, 512], layers[3])
# 26,26,512 -> 13,13,1024
self.layer5 = self._make_layer([512, 1024], layers[4])
self.layers_out_filters = [64, 128, 256, 512, 1024]
# 进行权值初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
#---------------------------------------------------------------------#
# 在每一个layer里面,首先利用一个步长为2的3x3卷积进行下采样
# 然后进行残差结构的堆叠
#---------------------------------------------------------------------#
def _make_layer(self, planes, blocks):
layers = []
# 下采样,步长为2,卷积核大小为3
layers.append(("ds_conv", nn.Conv2d(self.inplanes, planes[1], kernel_size=3, stride=2, padding=1, bias=False)))
layers.append(("ds_bn", nn.BatchNorm2d(planes[1])))
layers.append(("ds_relu", nn.LeakyReLU(0.1)))
# 加入残差结构
self.inplanes = planes[1]
for i in range(0, blocks):
layers.append(("residual_{}".format(i), BasicBlock(self.inplanes, planes)))
return nn.Sequential(OrderedDict(layers))
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.layer1(x)
x = self.layer2(x)
out3 = self.layer3(x)
out4 = self.layer4(out3)
out5 = self.layer5(out4)
return out3, out4, out5
def darknet53():
model = DarkNet([1, 2, 8, 8, 4])
return model
YOLOv3完整网络实现
from collections import OrderedDict
import torch
import torch.nn as nn
from nets.darknet import darknet53
def conv2d(filter_in, filter_out, kernel_size):
pad = (kernel_size - 1) // 2 if kernel_size else 0
return nn.Sequential(OrderedDict([
("conv", nn.Conv2d(filter_in, filter_out, kernel_size=kernel_size, stride=1, padding=pad, bias=False)),
("bn", nn.BatchNorm2d(filter_out)),
("relu", nn.LeakyReLU(0.1)),
]))
#------------------------------------------------------------------------#
# make_last_layers里面一共有七个卷积,前五个用于提取特征。
# 后两个用于获得yolo网络的预测结果
#------------------------------------------------------------------------#
def make_last_layers(filters_list, in_filters, out_filter):
m = nn.Sequential(
conv2d(in_filters, filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
nn.Conv2d(filters_list[1], out_filter, kernel_size=1, stride=1, padding=0, bias=True)
)
return m
class YoloBody(nn.Module):
def __init__(self, anchors_mask, num_classes, pretrained = False):
super(YoloBody, self).__init__()
#---------------------------------------------------#
# 生成darknet53的主干模型
# 获得三个有效特征层,他们的shape分别是:
# 52,52,256
# 26,26,512
# 13,13,1024
#---------------------------------------------------#
self.backbone = darknet53()
if pretrained:
self.backbone.load_state_dict(torch.load("model_data/darknet53_backbone_weights.pth"))
#---------------------------------------------------#
# out_filters : [64, 128, 256, 512, 1024]
#---------------------------------------------------#
out_filters = self.backbone.layers_out_filters
#------------------------------------------------------------------------#
# 计算yolo_head的输出通道数,对于voc数据集而言
# final_out_filter0 = final_out_filter1 = final_out_filter2 = 75
#------------------------------------------------------------------------#
self.last_layer0 = make_last_layers([512, 1024], out_filters[-1], len(anchors_mask[0]) * (num_classes + 5))
self.last_layer1_conv = conv2d(512, 256, 1)
self.last_layer1_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.last_layer1 = make_last_layers([256, 512], out_filters[-2] + 256, len(anchors_mask[1]) * (num_classes + 5))
self.last_layer2_conv = conv2d(256, 128, 1)
self.last_layer2_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.last_layer2 = make_last_layers([128, 256], out_filters[-3] + 128, len(anchors_mask[2]) * (num_classes + 5))
def forward(self, x):
#---------------------------------------------------#
# 获得三个有效特征层,他们的shape分别是:
# 52,52,256;26,26,512;13,13,1024
#---------------------------------------------------#
x2, x1, x0 = self.backbone(x)
#---------------------------------------------------#
# 第一个特征层
# out0 = (batch_size,255,13,13)
#---------------------------------------------------#
# 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512
out0_branch = self.last_layer0[:5](x0)
out0 = self.last_layer0[5:](out0_branch)
# 13,13,512 -> 13,13,256 -> 26,26,256
x1_in = self.last_layer1_conv(out0_branch)
x1_in = self.last_layer1_upsample(x1_in)
# 26,26,256 + 26,26,512 -> 26,26,768
x1_in = torch.cat([x1_in, x1], 1)
#---------------------------------------------------#
# 第二个特征层
# out1 = (batch_size,255,26,26)
#---------------------------------------------------#
# 26,26,768 -> 26,26,256 -> 26,26,512 -> 26,26,256 -> 26,26,512 -> 26,26,256
out1_branch = self.last_layer1[:5](x1_in)
out1 = self.last_layer1[5:](out1_branch)
# 26,26,256 -> 26,26,128 -> 52,52,128
x2_in = self.last_layer2_conv(out1_branch)
x2_in = self.last_layer2_upsample(x2_in)
# 52,52,128 + 52,52,256 -> 52,52,384
x2_in = torch.cat([x2_in, x2], 1)
#---------------------------------------------------#
# 第一个特征层
# out3 = (batch_size,255,52,52)
#---------------------------------------------------#
# 52,52,384 -> 52,52,128 -> 52,52,256 -> 52,52,128 -> 52,52,256 -> 52,52,128
out2 = self.last_layer2(x2_in)
return out0, out1, out2希望能够对大家理解YOLOv3 模型有所帮助呀!
















 5378
5378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











