






1. 定义与起源
- 定义:YOLO(You Only Look Once)个算法的名字就很形象——你只看一次(You Only Look Once),意味着它通过一次检测过程就能处理整张图片,而不需要像以前的算法那样分步骤处理。是一种单阶段(one-stage)的目标检测算法,其核心思想是将目标检测任务视为一个回归问题,通过单个神经网络直接预测图像中的物体类别和边界框。
- 起源:YOLO最初由Joseph Redmon、Santosh Divvala、Ross Girshick等人于2015年提出,并随着时间的推移发展出了多个版本,如YOLO V2、V3、V4等。
- 缘由:
在YOLO出现之前,检测图像中对象的主要方法是使用不同大小的滑动窗口依次通过原始图像的各个部分,以便分类器显示图像的哪个部分包含哪个对象。这种方法是合乎逻辑的,但非常迟缓。
经过了一段时间的发展,一个特殊的模型出现了:它可以暴露感兴趣的区域,但即便是这样还是太多了。速度最快的算法Faster R-CNN平均在0.2秒内处理一张图片,也就是每秒5帧。
在以前的方法中,原始图像的每个像素都需要被神经网络处理几百次甚至几千次。每次这些像素都通过同一个神经网络进行相同的计算。有没有可能做些什么来避免重复同样的计算?
事实证明这是可能的。但是为了这个,我们必须稍微重新定义这个问题。如果早些时候它是一个分类任务,那么现在它已经变成了一个回归任务。
2. 技术特点
优点:
- 实时性:由于采用单个神经网络模型,YOLO系列模型具有较高的推理速度和低的计算成本,可以实现实时目标检测。例如,YOLO V1的速度可达每秒45帧,甚至更小版本的模型能达到每秒155帧的速度。
- 多尺度特征融合:YOLO系列模型通过采用多层次的特征融合策略,能够有效地处理不同尺度的物体,并对小物体和大物体都有较好的检测效果。
- 鲁棒性和泛化能力:由于采用了深度学习技术,YOLO系列模型具有较强的鲁棒性和泛化能力,可以适应不同场景和环境下的目标检测任务。
结构图:
在结构上,YOLO 模型由以下部分组成:
-
Input ——输入图像被馈送到的输入层
-
Backbone ——输入图像以特征形式编码的部分。
-
Neck ——这是模型的其他部分,用于处理由特征编码的图像
-
Head(s)——一个或多个产生模型预测的输出层。
3. 工作原理
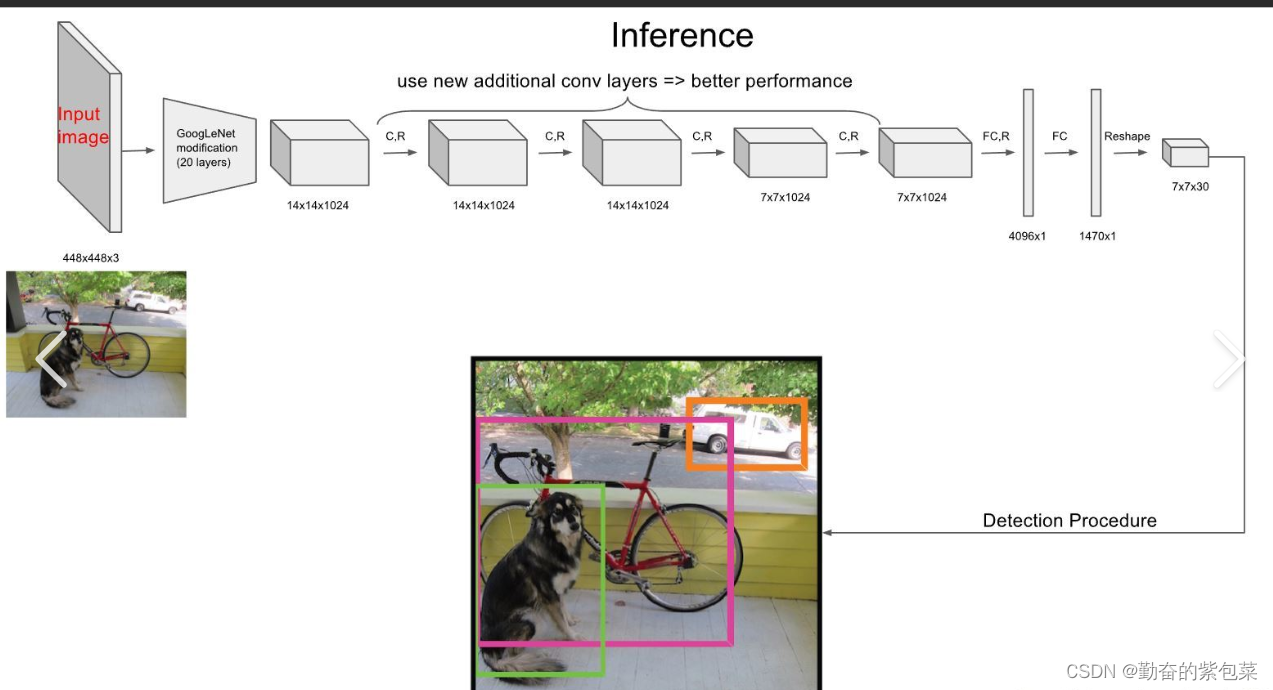
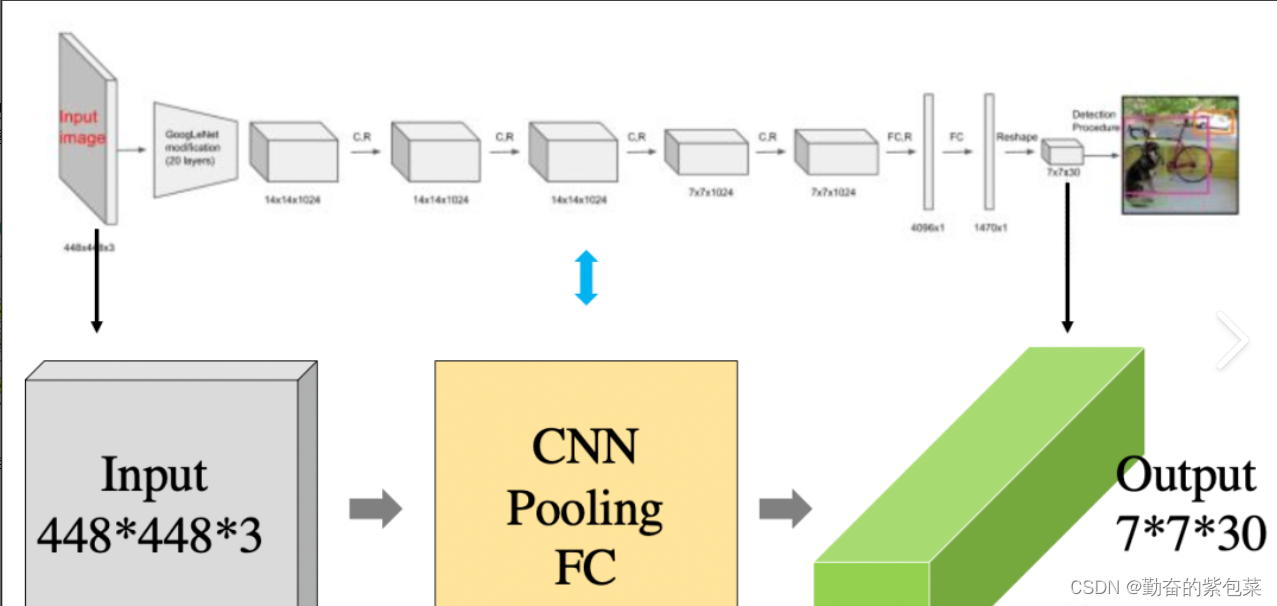
- 图片输入:将图片输入到多层卷积网络中以提取图片特征。
- 目标框回归:直接在输出层回归目标框坐标及其所属的类别。
- 非极大值抑制(NMS):最后通过NMS处理去掉重叠的目标框,以获得最终的检测结果。
4. 应用场景
- 自动驾驶:YOLO目标检测可以帮助自动驾驶系统识别和定位道路上的车辆、行人、交通标志等,从而提高驾驶安全性和智能化水平。
- 视频监控和安防:可以实时监测和识别异常行为、物体入侵等,提供及时的安防预警。
- 工业质检:用于工业生产线上的质量检测,如检测产品的缺陷、计数产品数量等,提高生产效率和质量。
- 零售和物流:实现商品的自动识别和计数,提高零售业和物流业的自动化水平,减少人工成本。
5. 变迁史
YOLOv8(2023年1月)
YOLOv9(2024年2月21日)
-
YOLOv1(2015年)
- 提出者:Joseph Redmon等人
- 主要特点:
- 首次提出将目标分类和定位用一个神经网络统一起来,实现端到端的目标检测。
- 将输入图像分成S×S个小格子,每个格子预测N个边界框,并直接输出边界框的坐标和类别概率。
- 速度快,满足实时性应用要求。
- 引用论文:《You Only Look Once: Unified, Real-Time Object Detection》
-
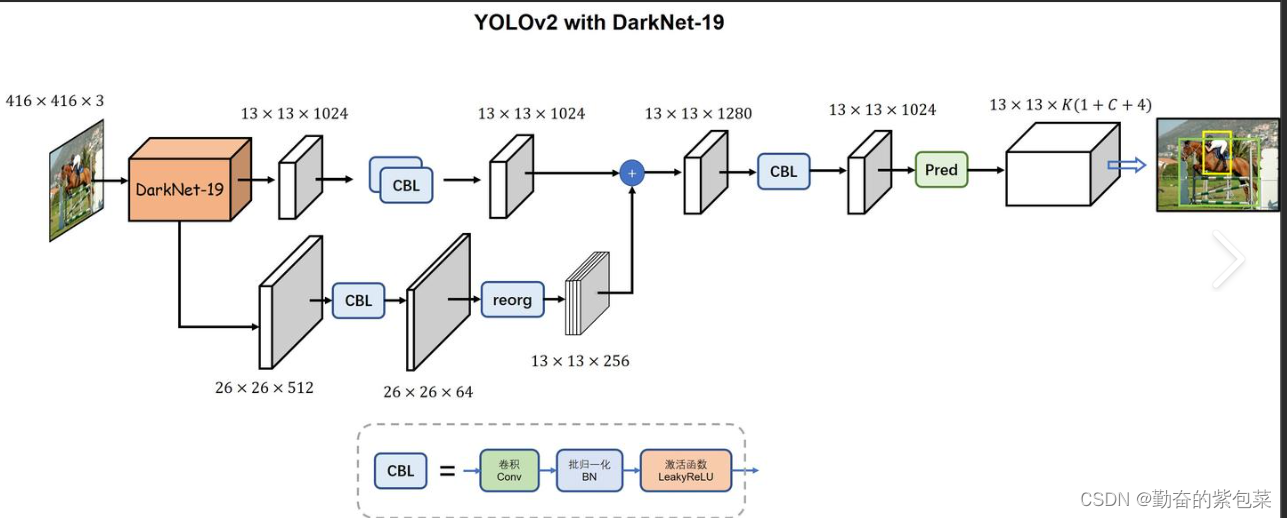
YOLOv2(2016年)
- 主要改进:
- 使用了更深的网络结构(Darknet-19)和更高的分辨率输入图像。
- 引入了Batch Normalization等技术,提高了检测精度和速度。
- 提出了多尺度训练策略,增强了模型对不同尺寸输入图像的鲁棒性。
- 特色功能:能够检测9000种不同的对象,因此也被称为YOLO9000。
- 引用论文:《YOLO9000: Better, Faster, Stronger》
- 主要改进:
-
YOLOv3(2018年)
- 主要改进:
- 采用了更深的网络结构(Darknet-53),进一步提高了特征提取能力。
- 引入了多尺度检测策略,可以检测不同尺度的目标。
- 使用了逻辑回归损失函数来预测边界框的置信度,提高了定位精度。
- 性能提升:在保持原有算法速度优势的同时,提升了模型的精度。
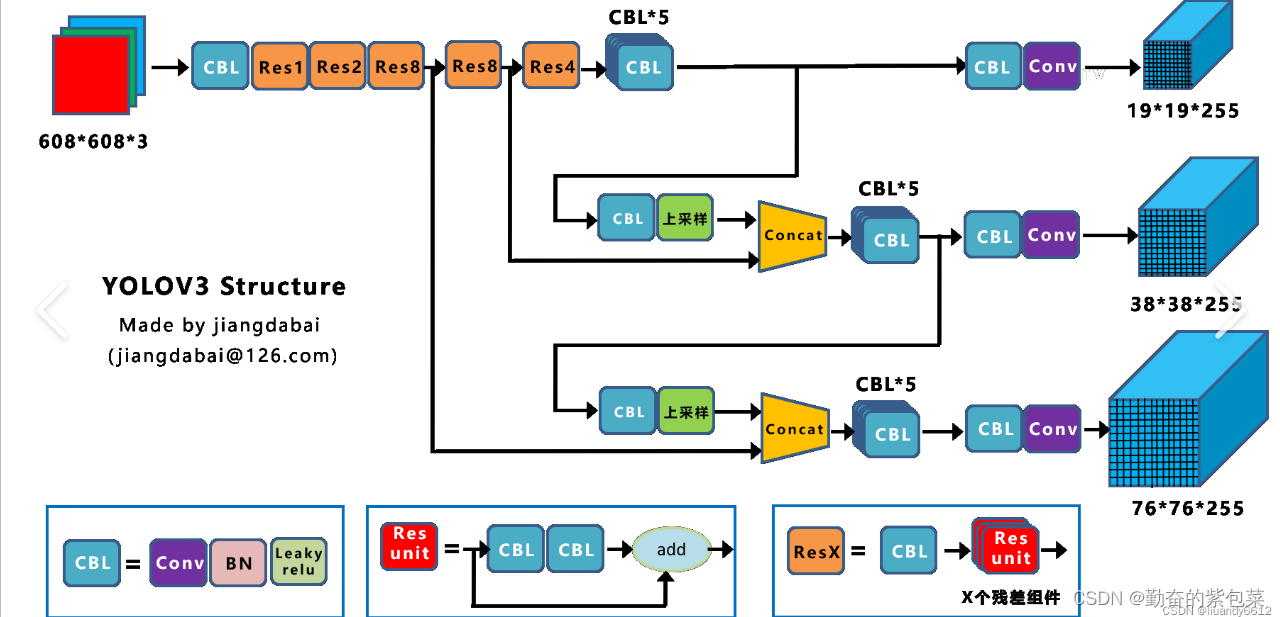
- 主要改进:
-
YOLOv4(2020年)
- 主要特点:
- 采用了更多的技术,如SPP(Spatial Pyramid Pooling)、CSP(Cross Stage Partial Network)等,进一步提高了检测精度和速度。
- 使用了Mosaic数据增强方法,提高了模型的泛化能力。
- 引入了DropBlock正则化策略,防止了模型过拟合。
- 性能表现:在多个数据集上均取得了优异的检测效果。
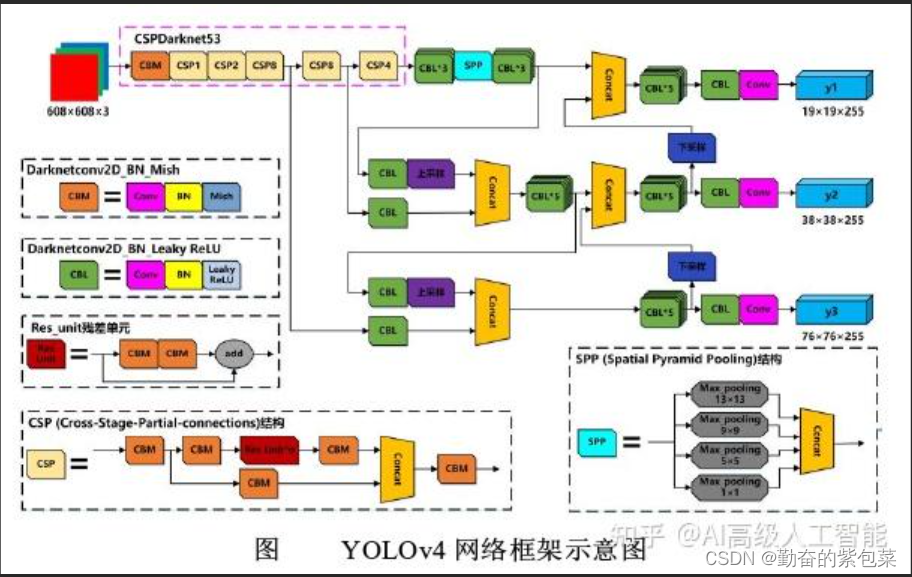
- 主要特点:
-
YOLOv5(2020年)
- 主要特点:
- 采用了轻量级网络结构,实现了更快的速度和更高的精度。
- 引入了新的训练策略和数据增强方法,进一步提升了模型的性能。
- 提供了多种预训练模型供用户选择,方便用户根据自己的需求进行微调。
- 发布版本:自2020年6月起,YOLOv5已发布多个版本,最新版本为v7.0。
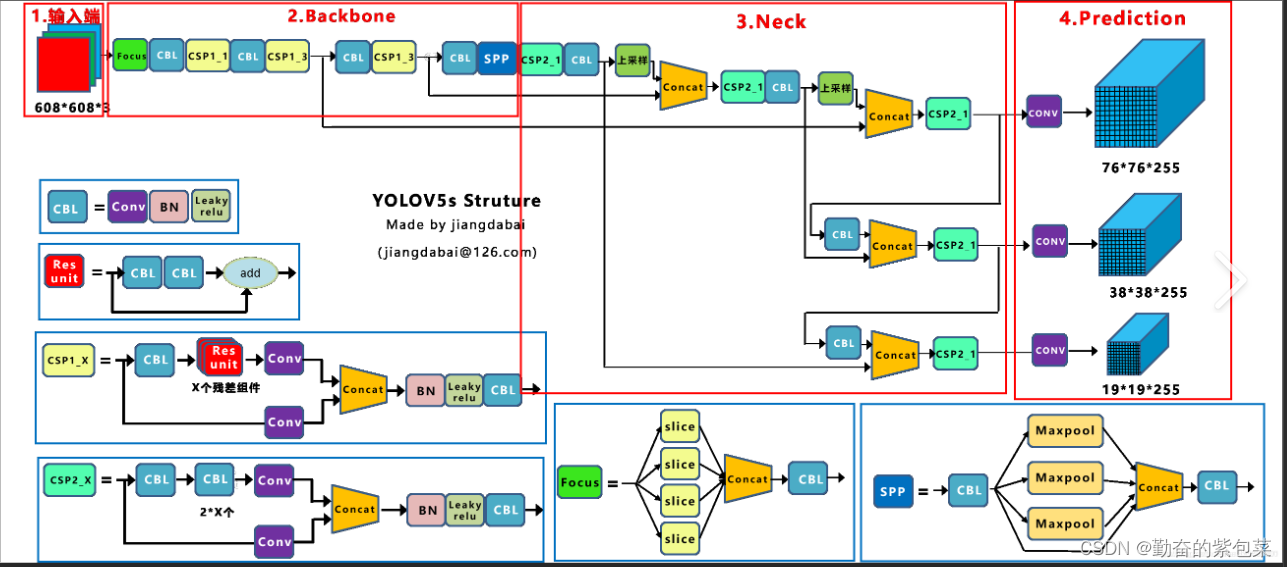
- 主要特点:
-
YOLOv6(2022年)
- 主要改进:
- 采用了更先进的网络结构和优化策略,进一步提高了模型的性能和效率。
- 专门针对工业应用场景进行了优化,提高了模型在实际应用中的表现。
- 应用场景:适用于工业自动化、智能制造等领域的目标检测任务。
- 主要改进:
-
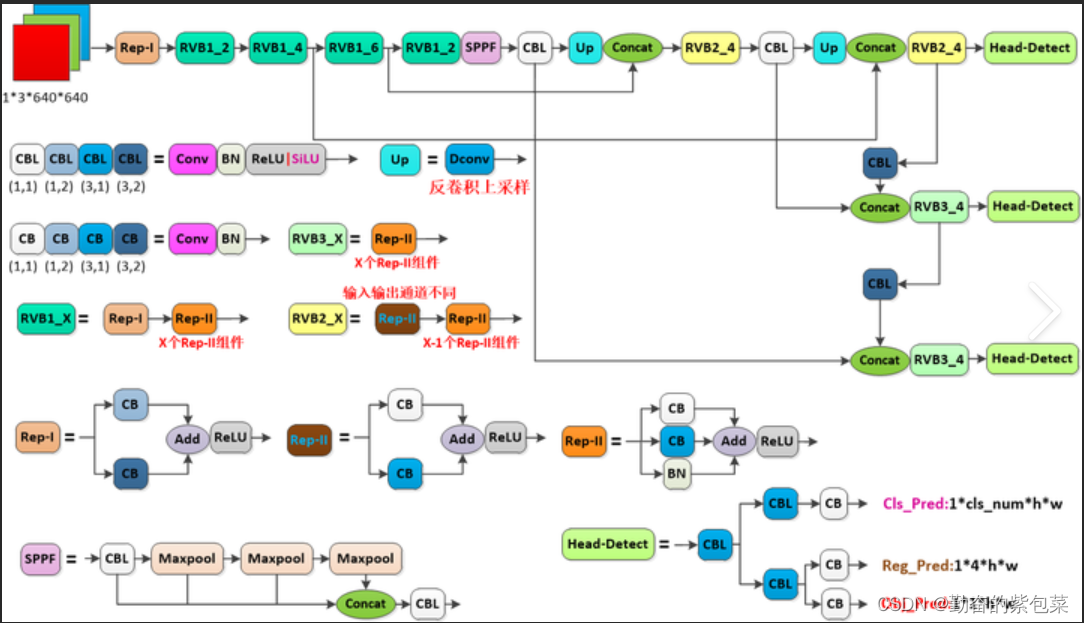
YOLOv7(2022年7月7日)
- 主要特点:
- 相较于YOLOv5,YOLOv7在保持速度优势的同时,通过改进骨干网络和特征融合方法等方式,进一步提升了检测精度。
- 引入了模型重参数化、新的标签分配策略、ELAN高效网络架构以及带辅助头的训练等创新技术。
- 技术细节:
- 模型重参数化:采用REPVGG中的思想,减少模型层数和参数量,同时保持或提高模型性能。
- 标签分配策略:结合YOLOv5的跨网格搜索和YOLOX的匹配策略,以提高目标检测的准确性。
- ELAN高效网络架构:提出新的网络架构ELAN,以高效为主要特点,优化模型性能。
- 带辅助头的训练:辅助头仅用于训练过程,不影响推理速度,旨在提升模型精度。
- 性能表现:
- 在GPU V100的实时目标检测器中,YOLOv7表现出色,具有较高的平均精度(AP)和较快的处理速度。
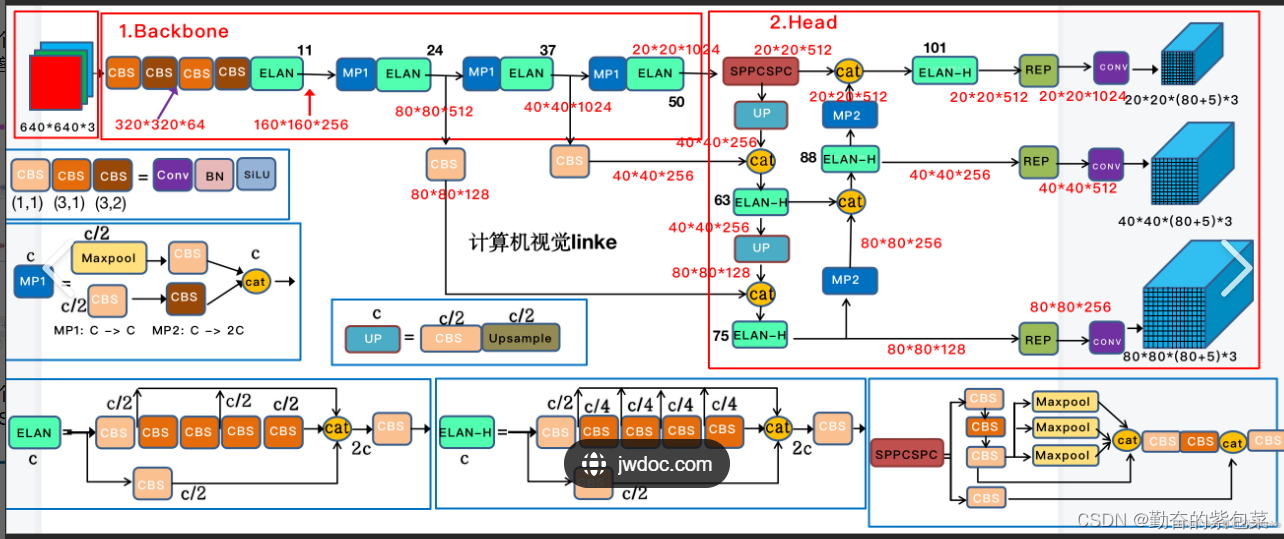
- 在GPU V100的实时目标检测器中,YOLOv7表现出色,具有较高的平均精度(AP)和较快的处理速度。
- 主要特点:
- YOLOv8是YOLO系列中的又一重要更新,进一步提升了模型的性能和效率。
- 该版本的具体技术细节和性能表现未在参考文章中详细提及,但可以推测其在保持YOLO系列一贯优势的同时,可能引入了新的优化策略和技术手段。
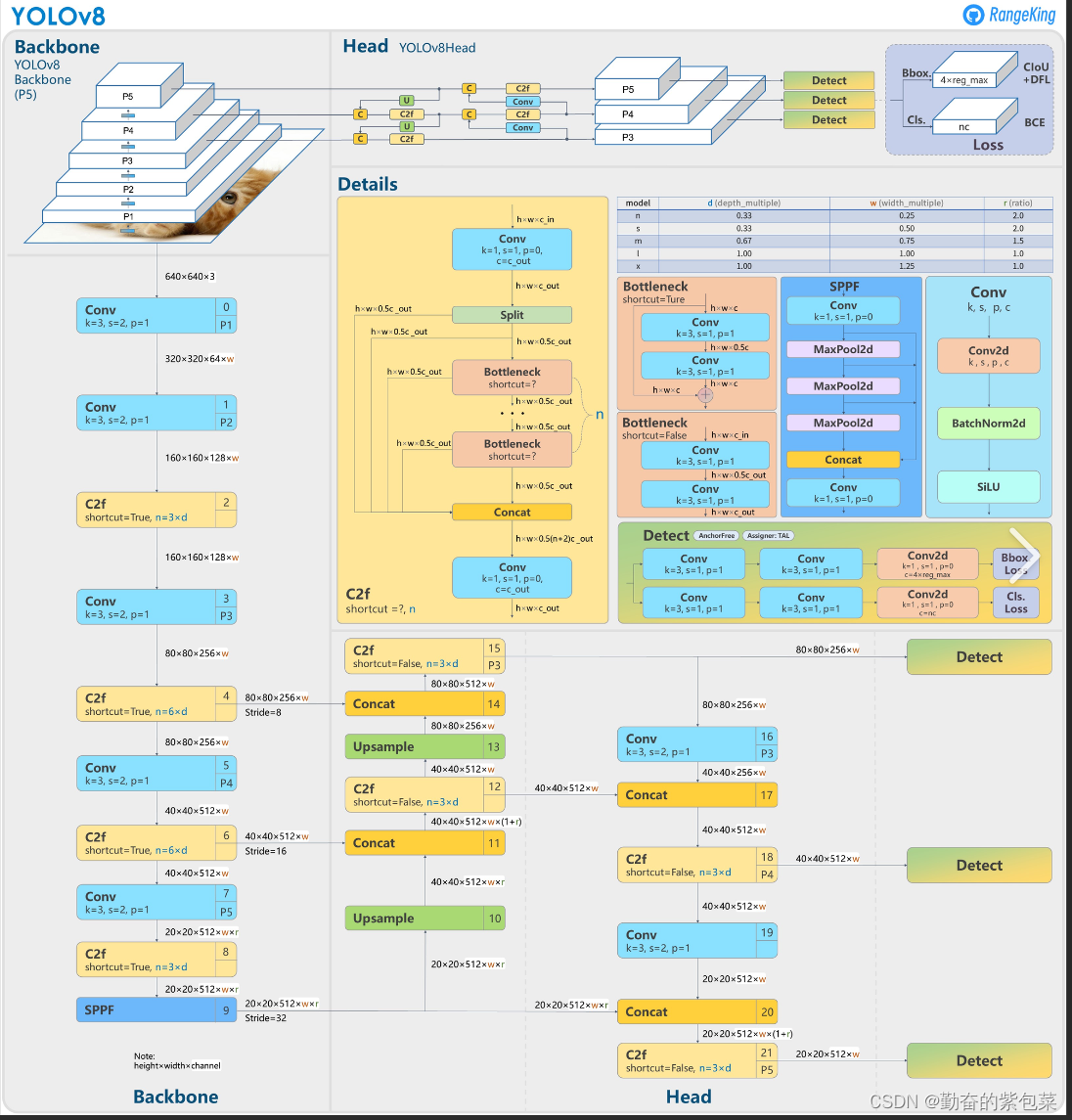
- 主要特点:
- YOLOv9是YOLO系列的最新版本,是YOLOv7的改进版,由Chien-Yao Wang等人提出。
- 引入了可编程梯度信息(PGI)和通用高效层聚合网络(GELAN)两种创新技术,旨在解决信息瓶颈问题,提高目标检测的准确性和效率。
- 技术细节:
- 可编程梯度信息(PGI):包括用于推理的主分支、用于可靠梯度计算的辅助可逆分支以及多级辅助信息,有效解决深度监督问题,无需增加额外的推理成本。
- 通用高效层聚合网络(GELAN):代表了一种适合PGI框架的独特设计,增强了模型更有效地处理和学习数据的能力。
- 性能表现:
- YOLOv9通过引入先进的深度学习技术和架构设计,展现出更好的性能。它利用PGI和GELAN技术,在保持高速处理速度的同时,实现了更高的检测精度。
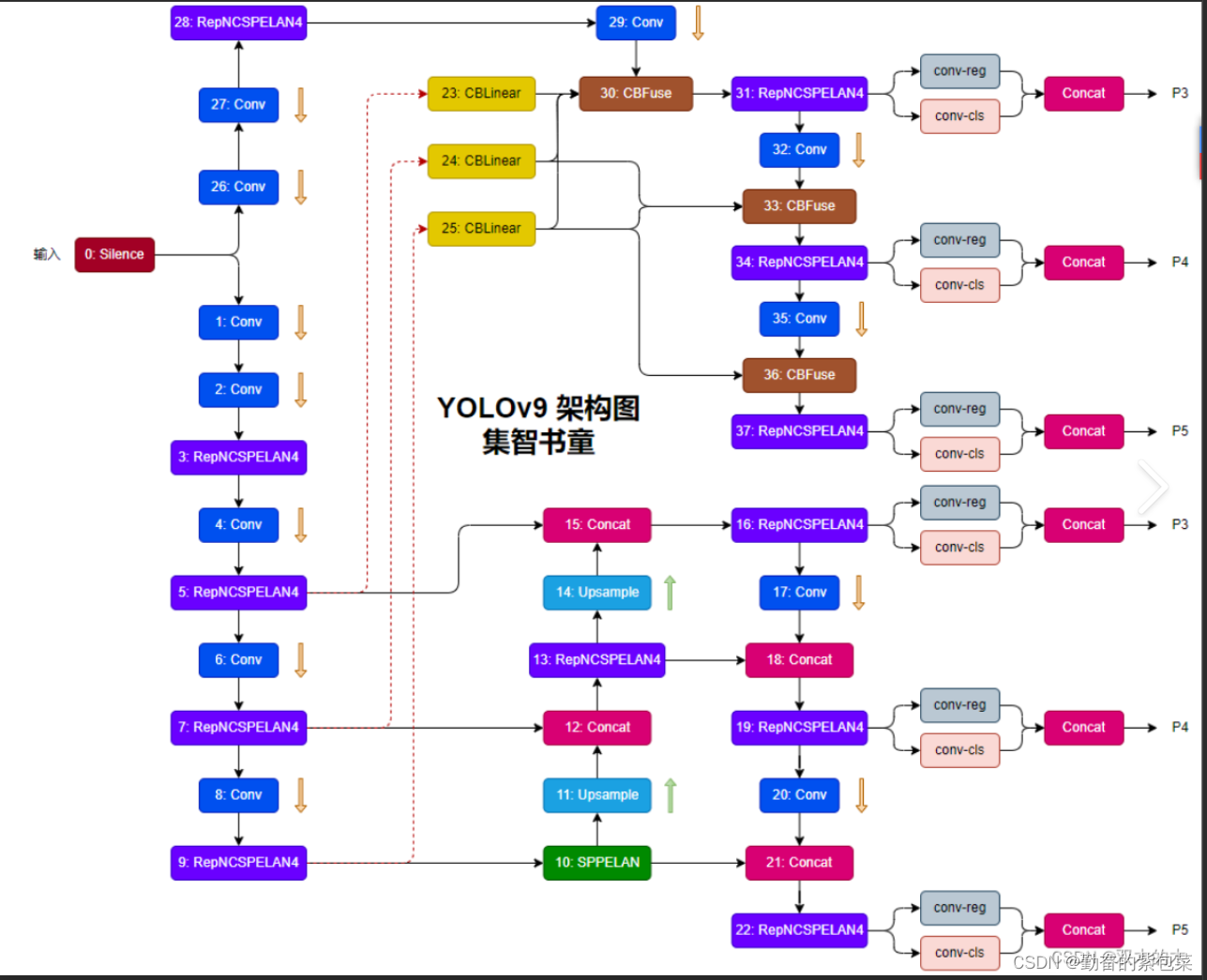
- YOLOv9通过引入先进的深度学习技术和架构设计,展现出更好的性能。它利用PGI和GELAN技术,在保持高速处理速度的同时,实现了更高的检测精度。

















 9066
9066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









