







Generative Variational-Contrastive Learning for Self-Supervised Point Cloud Representation | IEEE Transactions on Pattern Analysis and Machine Intelligence (acm.org)
作者:Bohua Wang; Zhiqiang Tian; Aixue Ye; Feng Wen; Shaoyi Du; Yue Gao
摘要
三维点云的自监督表示学习受到了越来越多的关注。然而,现有的3D计算机视觉领域的方法通常使用固定的嵌入来表示潜在特征,并对嵌入施加硬约束,以使正样本的潜在特征值趋于一致,这限制了特征提取器在不同数据域上的泛化能力。为了解决这个问题,我们提出了一个生成变分对比学习(GVC)模型,其中使用高斯分布来构建潜在特征的连续、平滑表示。构建了分布约束和交叉监督,以提高特征提取器在合成和真实世界数据上的迁移能力。具体来说,我们设计了一个变分对比模块来约束特征分布,而不是潜在空间中每个样本对应的特征值。此外,引入了一个生成交叉监督模块,以保留不变特征并促进正样本间特征分布的一致性。实验结果表明,GVC在不同的下游任务上实现了最先进的性能。特别是,仅在合成数据集上预训练,GVC在转移到真实世界数据集时,在线性分类和少样本分类上分别取得了8.4%和14.2%的领先优势。
关键词
-
对比学习
-
生成学习
-
点云
-
自监督
-
变分推断
I. 引言
如今,3D视觉已广泛应用于自动驾驶汽车、机器人、增强现实等领域。作为一种常见的数据结构,点云为3D对象提供了简洁的表示,并促进了3D视觉的发展。通过雷达或深度相机可以轻松获取点云数据,点云数据处理已成为3D视觉研究的重要领域。近年来,深度学习已被引入到点云表示学习中,并在分类、分割、目标检测等任务中表现良好。然而,这些基于深度学习的方法高度依赖于大量标记数据,这需要大量的人力成本来标记每个样本。近年来,自监督学习在文本和图像处理领域取得了显著成果。相关工作将自监督学习引入到3D视觉中,它们使用生成、对比等预文本任务来预训练特征提取器。通过这些预文本任务,这些模型使得基于深度学习的特征提取器能够在没有手动标记的情况下提取点云的潜在特征。
然而,获取和构建真实世界的实例级点云数据集比捕获图像需要更多的人力和设备成本。像ImageNet一样构建一个包含数百万样本的点云数据集是困难的。相比之下,合成数据更容易获得。因此,现有的点云自监督模型通常在具有高数据量的合成数据集上进行预训练,然后将特征提取器迁移到真实世界数据集以执行下游任务。然而,数据域之间的差异导致先前自监督方法在合成数据和真实世界数据之间的性能差距很大(图1)。在少样本分类中,这种差距更为显著,其中特征提取器的泛化能力要求更高。因此,如何提高点云特征提取器在合成和真实世界数据域的自适应能力仍然是一个紧迫的问题。
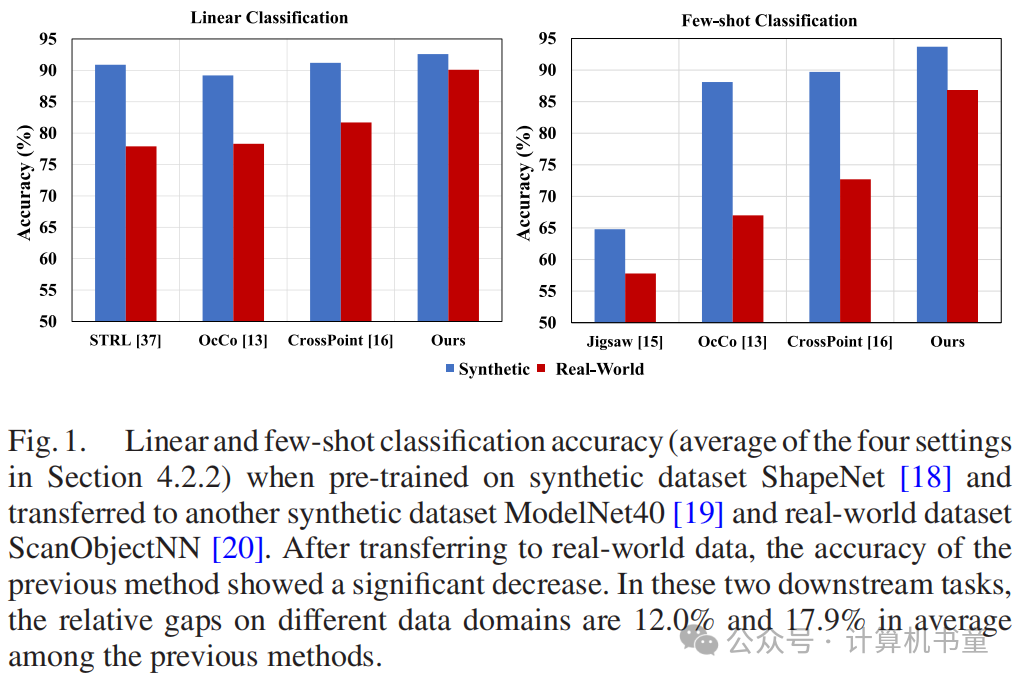
现有的点云自监督学习方法通常在合成数据集上进行预训练,因为这些数据集是通过CAD合成的,具有大量的数据、丰富的类型和低建设成本。然而,现有的点云3D对比学习方法主要遵循SimCLR或MoCo的框架,将样本投影到高维空间以获得固定潜在特征,并对其相似性施加硬约束。这些模型在相同的合成数据集上表现良好,但在转移到更具挑战性的真实世界数据集时性能显著下降。我们可以观察到,合成数据中的点是均匀分布的,没有局部信息缺失和噪声很少,而真实世界数据容易受到噪声和异常值的影响,不同区域的点不是均匀分布的(图2)。因此,在这种情况下,如何提高点云表示的泛化能力仍然是一个开放的问题。

为了解决这个问题,我们提出使用分布来构建潜在特征的连续和平滑表示。我们的模型不再约束潜在空间中每个样本对应的特征值,而是它们遵循的分布。与现有方法对潜在特征的硬约束相比,我们的方法可以避免在合成数据域上的过拟合,从而允许特征提取器具有更强的数据域迁移能力。具体来说,我们使用对比学习来约束潜在特征的分布,使得来自同一类别的样本的特征分布趋于相似,并区分不同类别的特征分布。此外,我们将对比学习与生成学习结合起来,提出了一个生成变分对比(GVC)模型,旨在整合生成学习与对比学习的优势,使我们的模型在保留不变特征的同时关注类别间的差异。而且,我们的生成交叉监督模块使用交叉监督而不是传统的自监督来促进正样本间特征分布的一致性。与应用于图像处理的对比学习模型不同,GVC不需要像SimCLR那样构建一个巨大的负样本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2453
2453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









