







Title: Improved Field-Based Soybean Seed Counting and Localization with Feature Level Considered
Abstract: Developing automated soybean seed counting tools will help automate yield prediction before harvesting and improving selection efficiency in breeding programs. An integrated approach for counting and localization is ideal for subsequent analysis. The traditional method of object counting is labor-intensive and error-prone and has low localization accuracy. T o quantify soybean seed directly rather than sequentially, we propose a P2PNet-Soy method. Several strategies were considered to adjust the architecture and subsequent postprocessing to maximize model performance in seed counting and localization. First, unsupervised clustering was applied to merge closely located overcounts. Second, low-level features were included with high-level features to provide more information. Third, atrous convolution with different kernel sizes was applied to low- and high-level features to extract scale-invariant features to factor in soybean size variation. Fourth, channel and spatial attention effectively separated the foreground and background for easier soybean seed counting and localization. At last, the input image was added to these extracted features to improve model performance. Using 24 soybean accessions as experimental materials, we trained the model on field images of individual soybean plants obtained from one side and tested them on images obtained from the opposite side, with all the above strategies. The superiority of the proposed P2PNet-Soy in soybean seed counting and localization over the original P2PNet was confirmed by a reduction in the value of the mean absolute error, from 105.55 to 12.94. Furthermore, the trained model worked effectively on images obtained directly from the field without background interference
Keywords: NONE
题目:考虑特征水平的改进的基于田间的大豆种子计数和定位
摘要:开发自动大豆种子计数工具将有助于在收获前实现产量预测的自动化,并提高育种计划的选择效率。计数和定位的集成方法是后续分析的理想方法。传统的物体计数方法劳动密集,容易出错,定位精度低。为了直接而不是顺序地量化大豆种子,我们提出了一种P2PNet大豆方法。考虑了几种策略来调整架构和随后的后处理,以最大限度地提高种子计数和定位中的模型性能。[刘1] 首先,将无监督聚类应用于紧密定位的过计数的合并。其次,将低级特征与高级特征一起包含,以提供更多信息。第三,将不同卷积核尺寸的atrous卷积应用于低层次和高层次特征,提取尺度不变特征,以考虑大豆粒径的变化。第四,通道和空间注意力有效地分离了前景和背景,便于大豆种子的计数和定位。最后,将输入图像添加到这些提取的特征中,以提高模型性能。以24份大豆材料为实验材料,利用上述所有策略,我们在从一侧获得的大豆单株的田间图像上训练了模型,并在从另一侧获得的图像上进行了测试。通过将平均绝对误差值从105.55降低到12.94,证实了所提出的P2PNet大豆在大豆种子计数和定位方面优于原始P2PNet。此外,训练后的模型在没有背景干扰的情况下直接从现场获得的图像上有效地工作。
关键词:无
作者:Jiangsan Zhao1, Akito Kaga2, T etsuya Yamada2, Kunihiko Komatsu3, Kaori Hirata4, Akio Kikuchi4, Masayuki Hirafuji1, Seishi Ninomiya1, and Wei Guo1*
作者单位:
1Graduate School of Agriculture and Life Sciences, The University of Tokyo, Tokyo, Japan. 2Institute of Crop Sciences, National Agriculture and Food Research Organization, Tsukuba, Ibaraki, Japan. 3Western Region Agricultural Research Center, National Agriculture and Food Research Organization, Fukuyama, Hiroshima, Japan. 4Tohoku Agricultural Research Center, National Agriculture and Food Research Organization, Morioka, Iwate, Japan.
文章出处:Plant Phenomics
出处杂志的影响因子:6.961 (2021年)
1.引言
实验室开发的这些高度复杂的方法在野外肯定会失败,因为野外图像中的背景、自然日光条件和吊舱重叠程度差异很大。因此,迫切需要更先进的方法来处理复杂背景、广泛重叠的豆荚和变化的光照条件等困难条件下的种子计数。[刘2]
深度学习在图像处理方面有所发展,从而使基于图像的物体计数比以前容易得多[21-23]。基于深度学习的自动大豆种子计数可以成为加快产量预测和后续育种过程的一个非常有价值的工具,特别是考虑到它能够克服人工和传统基于图像的种子计数的几乎所有缺点。常见的基于深度学习的物体计数方法是先检测物体,然后对预测的边界框进行计数的通道[21,24]。然而,这是以人工和昂贵的边界框注释为代价的。此外,当目标的位置太近时,重叠的边界框很难被抑制[25]。此外,物体检测和图像分割不应该是计数的先决条件,因为在计算机视觉中,这两者通常被认为是比计数更具挑战性的任务。基于检测的计数方法之所以受欢迎,可能是由于研究充分且现成的框架可供使用,例如更快的R-CNN[21]、YOLO系列[22,26,27]以及其他全卷积网络[28]、UNET[23]和DeepLab[29]。[刘3]
与其采用顺序的方法,不如利用廉价的点状注释更直接地解决计数问题。通过回归直接计数是另一类用于物体计数的深度学习,它涉及到在点状标签的协助下将计数与目标图像连接起来[30,31]。然而这种技术并不提供被计数物体的确切位置,使其成为图像中的被计数物体。TasselNet系列[32-34]侧重于使用基于回归的方法精确计算流苏的数量。然而,预测对象的可视化密度图无法用直觉来解释。[刘4]
最近提出的P2PNet[35]方法使点的计数更容易。此外,基础的基本理论相对简单,通过直接训练一个以点为标签的模型来定位和计数这些点,而不是传统的边界框或由点状标签创建的密度图。然而,P2PNet在直接用于大豆种子计数时表现出较低的性能,这可以由几个原因来解释。首先,最初的P2PNet是为计数所有同一类的物体而开发的,但没有与背景相似的物体的干扰。相反,当目标植物的旁边和后面出现其他结籽的大豆植物时,田间大豆计数就变得非常困难。因此,田间大豆植物图像的背景是复杂的,而且,不可避免地,邻近植物的种子经常出现在背景中,从而降低了模型性能。第二,对相应的真实种子位置的预测严重超标。真正的种子位置被观察到。[刘5]
2.方法和材料
本节介绍了数据收集和预处理,构成了大豆种子计数和定位的框架。
2.1现场条件和实验设计
本研究共选择了24份表现出相似成熟度的accessions[刘6] 。在同一行中,每一个accession的五株植物被成像,并对种子总数进行统计。进行成像,并计算种子的总数。
2.2 田间数据采集和处理
使用手持式照相机(DSC-RX0M2,日本索尼公司)对每一accession的5株植物的两侧进行成像,以减少来自密集的大豆种子的隐藏或重叠效应(图1)。为了准备训练和测试数据集,我们从块图像中单独裁剪了植物(图2)。


由于相邻植物之间的距离很小,在单个植物图像中无法避免部分包含相邻植物的片段。每种植物的种子都由东京大学田间表型实验室的经验丰富的技术人员点注(图2)。只有那些属于目标作物的种子才会被标注,而来自两边和背景的相邻植物的种子则被忽略。只要图像中能看到种子全尺寸的1/10,就可以对其进行注释,以确保注释的种子数量尽可能接近破坏性取样所统计的种子数量(图2)。共准备了374张单个植物的图像作为本研究的实验数据集;其余的因为豆荚碎裂而没有包括在内。
2.3 大豆种子计数和定位的深度学习框架
最初的P2PNet是一个纯粹基于点的框架[37]。它直接将点注释作为掩码,从而可以提供预测目标的准确位置,而不是纯粹的对象数量或密度图。该模型被训练为预测尽可能接近人工标注的点。P2PNet的最终预测基于两个分支的总和:回归,指示点的位置,分类,基于预测点的置信度得分。两个分支共享VGG-16[38]提取的高级特征。在本研究中,高层和低层特征被定义为conv3-3、conv4-3和conv5-3层,以及由VGG-16的conv1-3和conv2-3层组成的另一组。该网络不仅结构清晰、直观,而且可以同时确定计数对象的数量和位置。因此,它被作为管理大豆种子计数任务的基础。
然而,通过直接利用P2PNet进行大豆种子计数,充分探索P2PNet的先进理念,在实际的大豆种子计数中并非直接无效。[刘7] 因此,我们提出在原有的P2PNet的基础上应用几种策略,使其完全适应大豆种子计数,特别是田间图像(图3)。

考虑到田间大豆种子计数的复杂情况,我们采取了一些策略来提高模型的性能。首先,有许多预测的种子位置卡在人工标注周围。一种无监督的聚类算法,即k-d树[39],被用来寻找这些位置紧密的预测的中心,以提高最终的预测精度。第二,在原始的P2PNet中,回归和分类任务都只使用了高级特征。由于高层次的特征通常包含全局感知的信息,而低层次的特征则捕捉更详细的空间结构信息,因此,这种组合可能会充分挖掘大豆种子计数的模型潜力[36]。第三,种子的大小在不同的大豆品种中有所不同。考虑大小差异的特征提取方法对提高模型性能也很重要。与3、5、7的方法类似,在不同的层面上覆盖不同的接收场,处理种子大小的变化。第四,应用空间注意力,采用注意力来突出大豆种子的语义信息。空间和通道注意力被用来有效地优先处理目标种子和其背景之间的边界信息,从而获得更好的计数性能。最后,直接将原始图像作为参考,将整个框架格式化为残差学习以提高模型性能。[刘8]
2.4 网络训练和验证
由于大豆植物的图像是在田地里拍摄的,所以从一侧(总共181个)拍摄的裁剪的个体植物图像被用于训练,而从另一侧拍摄的193个图像被用于评估。使用基于193张测试图像的平均绝对误差(MAE)来评估模型性能。最后,在不进行裁剪的情况下直接获得的田间图像中,对模型在种子计数和定位方面的性能进行了可视化。
3.结果
原始P2PNet的MAE为105.55;然而,预测种子计数和人工标注种子计数之间的相关性仍然很高,R2为0.82(图4)。主要的错误是由于原始的P2PNet无法去除这些位置紧密的预测,从图像中可以看出(图5A),导致这些种子的相应真实位置周围有dense “crowd”。[刘9] 通过直接应用k-d树作为后处理程序,MAE的值急剧下降至14.40,并与它们的人工标注具有0.85的改进相关性(图4B)。然而,在这些预测中遗漏了一些尺寸较大的种子(图4)。
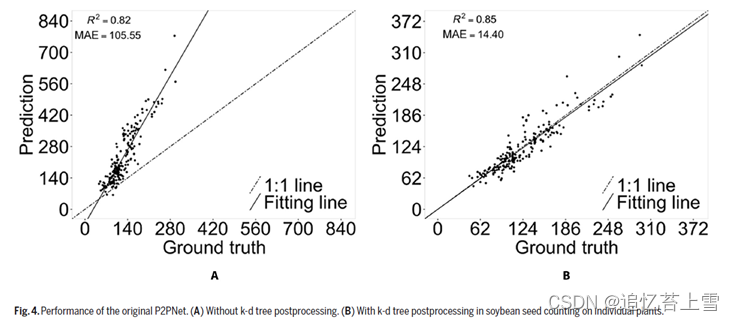
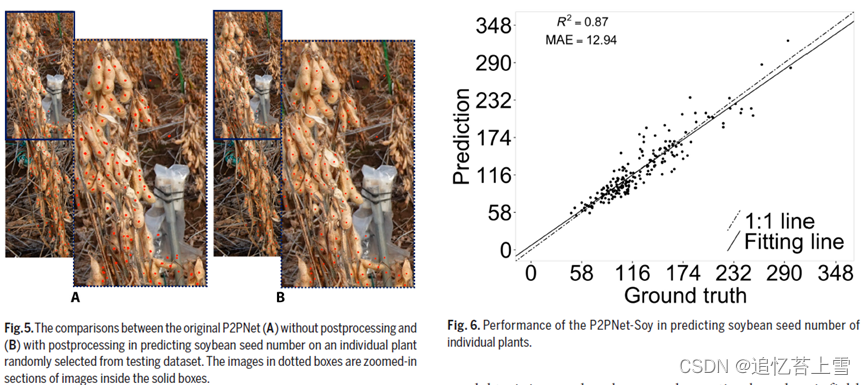
所提出的P2PNet-Soy模型的性能明显优于原始P2PNet,即使在原始P2PNet模型中加入了后处理,其性能依然优越(图6和7)。一些以前在原始P2PNet中缺失的大种子被提出的网络检测出来(图7)。这些模型在应用于直接从田间拍摄的图像时也显示出非常好的性能(图8)。图8显示了优化后的P2PNet-Soy比原来的P2PNet模型性能的提高,即使经过后期处理也是如此。[刘10]
尽管性能有所提高,但所提出的P2PNet-Soy模型仍然高度依赖于后处理,即每个策略的不同贡献(表)。原始P2PNet的MAE值在很大程度上被k-d树后处理所降低,加入低水平和多尺度多接收场特征提取(MSMR)后,该值进一步小幅降低,分别为14.16和14.02。相比之下,仅对低水平特征添加空间关注,增加的原始图像直接被纳入大豆种子计数和定位。对高层次特征加入通道关注,进一步将MAE降低到12.94,达到最佳性能。[刘11]
4.讨论
大豆种子计数对产量预测很重要,有助于更有效的农业决策。利用人群计数的最新进展,直观的P2PNet可以直接获取点标记图像进行模型训练,基于内场图像的大豆种子计数有望大大方便。然而,这种直接转移导致了不令人满意的性能,因为原始的P2PNet模型不是为大豆种子计数设计的。因此,为了使其完全适应大豆种子计数,特别是利用手机摄像头方便地在田间拍照,我们采用了几种策略将原来的P2PNet升级为P2PNet Soy,可以更有效、更准确地用于田间大豆种子计数。
原有的P2PNet模型由于出现了比相应的地面实况值高10倍以上的超额预测,出现了(suffered severely from)巨大的MAE值。主要的错误因素是该模型抑制远离相应真实位置的预测的能力较低。k-d树[39]后处理在搜索过度预测的种子中心方面非常有效,从而降低了MAE值,并使预测的位置更接近真实位置。尽管预测种子数和地面实况种子数之间的回归R2值降低了0.2,但预测种子数的准确性和位置都显著提高。由于种子计数和定位对育种至关重要,因此后处理对于提高其精度至关重要。此外,匈牙利算法[40]用于在训练期间将预测分配给地面实况种子标签;然而,当地面实况种子标签不可用于外部测试图像时,它变得不适用。原始模型在后处理后性能的提高证实了其对大豆种子计数的极大便利,尤其是使用点注释标签。由于涉及更有效架构的模型的任何小型升级都可能相当困难,因此额外的后处理不仅可以有效地提高模型的性能,而且可以更容易地采取行动。


信息量更大的提取特征为任何成功的深度学习框架提供了更坚实的基础[35]。忽略包含与原始输入图像中的信息非常不同的信息的不同特征级别是解释原始模型性能差的另一个原因。在原始P2PNet中有两个独立的分支,一个用于分类,另一个用于回归,与任何一个模块本身相比,这两个分支的组合显示出优越的实验性能[37]。高级和低级特征具有不同的特征,与深度学习任务相辅相成。这些低层过滤器检测边缘和角落等特征,而高级过滤器检测零件和对象等高级语义模式[41]。更高层次的特征通常更模糊,并侧重于对象的一般上下文;然而,它们的空间分辨率相当低,因此,准确定位大物体或识别小物体的可能性较低[42]。添加具有详细预测精度的较低级别特征[36]。包含不同级别的功能,可以完全捕获满足不同任务的所有必要信息,从而确保更高的模型性能。[刘12]
模型性能的显著提高来自于对低级特征的空间关注以及原始输入图像的添加。提取的低级特征图包含许多细节;然而,它们中的大多数都是干扰模型搜索更有用信息的噪声。空间注意力用于帮助模型关注边缘信息,并可能找到目标种子与其背景之间的边界,以进行更有效的计数[43]。很少为了检测目的而直接捕获原始图像;然而,原始图像提供了比低级特征更完整的空间信息[35]。与仅依赖于提取的特征的模型相比,直接包含原始图像减少了学习负荷,从而提高了本研究的性能。
通过atrous卷积[44]提取多尺度特征以覆盖大豆种子大小差异是由于数据集中的不同材料或每个材料中的差异。与不同大小的核进行严格的卷积不仅增加了感受野,而且确保了提取的特征是尺度不变的,有助于模型在不同尺度上识别种子,并提高模型对图像中种子可见大小变化的鲁棒性。[刘13]
考虑到模型MAE值的降低,与其他组件相比,后处理组件对改进性能的贡献最大。高层次和低层次特征与原始输入图像的结合,加上萎缩卷积和注意力机制,提高了模型在大豆种子计数和定位中的性能。根据CNN提取的不同层次特征中包含的信息,应将其融合,以进一步改进大豆种子计数和定位。我们展示了空间信息丰富的下层特征,提高了模型的性能。原始图像在提高模型性能方面也发挥了重要作用。将原始图像包含在大豆种子计数和定位中凸显了其在深度学习任务中的潜在关键作用,因为提取的特征大多用于不同的深度学习任务,而不是原始图像。在许多深度学习任务中,后处理是不可避免的,要么嵌入到主网络中,要么依次添加[45-48]。与相应的人工标注值非常接近的错误预测一般与提前提出许多点的网络架构有关,从而导致在网络学习过程中难以去除这些点。此外,应该提出一个先进的架构,以减少由此产生的假象,这样,额外的后处理可能就没有必要了。[刘14]
5.结论
我们提出了一种升级的P2PNet大豆方法,用于更有效的大豆种子计数和定位,与原始P2PNet和其他大豆荚计数方法相比,精度高得多。由于背景复杂,叶片和其他豆荚重叠,田间大豆的计数和定位相对比实验室实验更困难。更令人惊讶的是,经过训练的模型在内场图像上也表现出色,没有裁剪出单个植物,这使其成为未来在野外实施的潜在工具。然而,目前的方法仍有一些局限性。首先,来自植物前后的种子总数肯定是对产量的高估,需要改进,并且计数应该基于关于种子分布的位置信息和其他相关信息的比较。第二,不可见的部分(从未出现在图像中)不能被算法检测到。为了解决这个问题,我们最初考虑使用视频而不是图片,因为视频可以从不同的方向获得多个帧,这可能使不可见的豆荚从某个视角变得可见。这在我们以前的工作中也得到了证明[Deep-learning-based in-field citrus fruit detection and tracking]。[Deep-learning-based in-field citrus fruit detection and tracking]中的图10和图11显示了苹果是如何因为视频摄像机的移动而出现和消失的。然而,对于某些品种,大豆植株结构和豆荚位置可能非常复杂,任何红、绿、蓝传感方法都无法捕捉到所有豆荚。目前的解决方案无法检测和计算种子。我们可能需要考虑用更先进的方法来解决这个问题,作为未来的挑战,如(a)不同的传感技术(技术),如X射线或计算机断层扫描来获取大豆植株的不可见部分,(b)根据可见信息来预测不可见部分的助理三维模型,以及(c)能够将当前来自可见部分的检测和计数结果与通过破坏性人工采样获得的真实计数数联系起来的统计模型。第三,种子发育过程中的种子流产或种子充实失败会影响产量,并且很容易因为各种因素如环境压力、疾病和昆虫伤害而发生。然而,由于调查所需的时间和精力,一直很难评估其程度。我们的方法也没有对这种情况进行测试。[刘15]
我们希望在未来推进这项研究,以研究种子流产的程度是否可以容易地量化,以及种子生产的生理学和遗传学是否可以阐明。未来应实施移动机器人的升级模型,以减少人类在自主任务中的劳动参与。这些有效的策略也应该应用于其他计数和定位相关的任务,如小穗和流苏计数。未来应该提出用更简单的架构去除后处理的模型,通过利用深度相机或激光雷达有效抑制背景信息来促进大豆产量预测。

6.数据获取
本研究中使用的数据可应要求提供:GitHub - UTokyo-FieldPhenomics-Lab/P2PNet-Soy: Soybean seed localization and counting based on dot annotated infield images
[刘1]研究背景和意义
[刘2]现在算法研究的必要性
[刘3]说明深度学习的必要性和现在深度学习还存在的问题
[刘4]另一类回归算法的弊端
[刘5]引出能解决上述深度问题的框架,并说明该框架内的问题,引出我们提出方法的必要性
[刘6]An accession is a group of related plant material from a single species which is collected at one time from a specific location. Each accession is an attempt to capture the diversity present in a given population of plants. Accessions are given a unique identifier, an accession number, which is used to maintain associated information in the GRIN database. This is similar to call numbers that libraries use, except instead of books we are able to manage plants.
[刘7]说明现在的难题,原框架无法较好的使用
[刘8]模型改进方案
[刘9]原始P2PNet网络的缺陷
[刘10]改进后模型的优势
[刘11]消融实验得到最佳性能
[刘12]讨论改进对模型提升的原因
[刘13]讨论改进后空洞卷积的作用
[刘14]讨论后处理的必要性和未来可以升级的地方
[刘15]未来对缺点的改进方向















 430
430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









