







这是我们专业的上机实验二,写这篇博客用于记录,供大家学习使用,若有错误,欢迎大家批评指正,下面话不多说,直接进入正题!
前情提要:使用imread读取灰度图和使用cvtColor读取灰度图的效果不一样,经实验对比,后者可以保存更多的人体肉质结构的细节;因此可以利用前者获去更优的骨骼细节并增强,利用后者对人体非骨骼细节细化——(这里是查资料了解到的,两种函数的处理方式不同)
项目思路:本项目分三部分进行,第一部分实现对骨骼细节的增强与平滑降噪,第二部分实现对肉质细节的增强与平滑降噪;第三部分实现对前两者的处理后的图像进行叠加,并用灰度幂变换将图像提亮。
第一部分:对骨骼细节的增强与平滑降噪
- 通过cv2.imread()函数以灰度读取图片,用高斯滤波器降噪,高斯核大小选取7*7;
- 利用Prewitt算子增强骨骼细节;
- 将Prewitt算子处理后的图像与原始图像进行叠加,在增强骨骼细节的同时保留原始图像的低频细节
说明:Prewitt算子适合用来识别噪声较多、灰度渐变的图像,相比于Roberts算子,在水平方向和竖直方向上对边缘的检测更加明显。
| Prewitt处理之后的图像 | 将Prewitt处理后的图像与原始图像叠加 | |
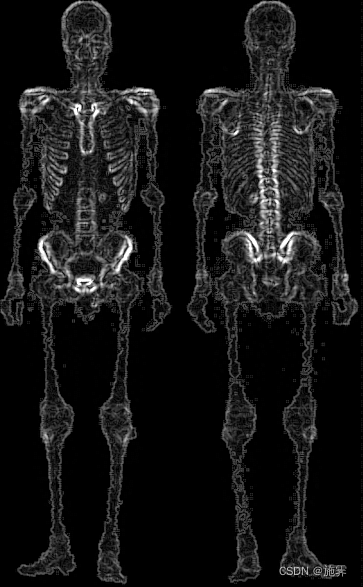 | 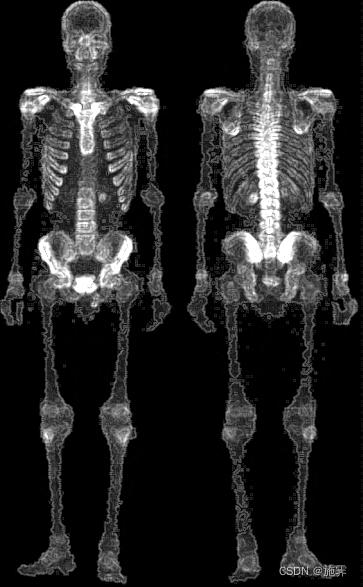 |
第二部分:对肉质细节的增强与平滑降噪
- 通过cv2.cvtColor()函数以灰度读取图片,采用高斯滤波器,高斯核大小选取7*7;
- 利用Laplace算子处理第一步高斯平滑之后的图像,增强骨骼细节,算子中心系数为正,将处理后的图像与原始图像相加;
| Laplace处理之后的图像 | 将Laplace处理后的图像与原始图像叠加 |
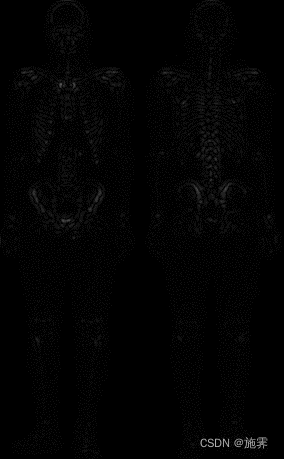 | 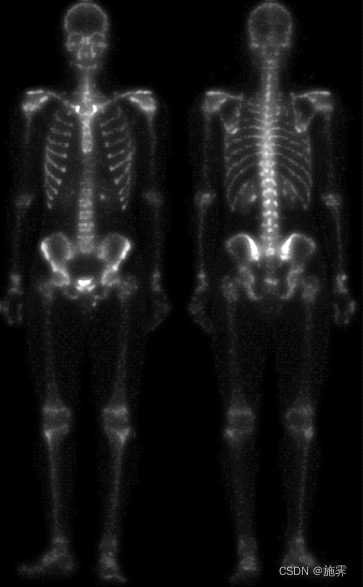 |
3. 利用Sobel算子处理第一步高斯平滑之后的图像,增强灰度变化较弱的细节(肉质细节),并用双边滤波器平滑噪声保留边界;
| Sobel处理之后的图 | 将Sobel处理后的图像与双边滤波后的图像叠加 |
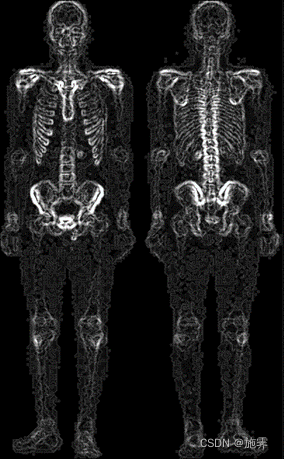 | 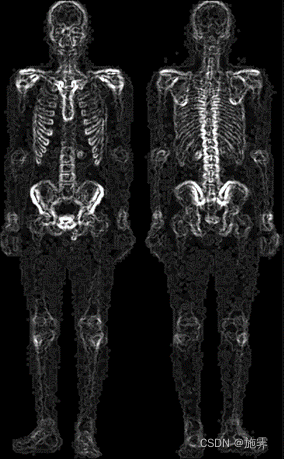 |
4. 使用cv2.addWeighted()函数将第二步与第三步处理之后的图像叠加;
5. 考虑到处理之后仍然存在噪点,利用中值滤波再次平滑图像;
| 前两步叠加效果图 | 降噪处理 |
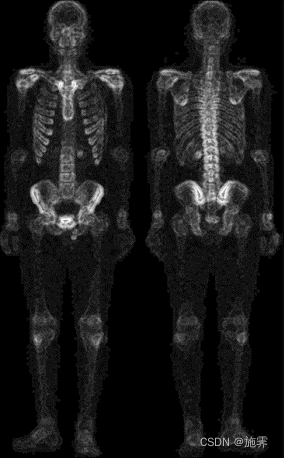 | 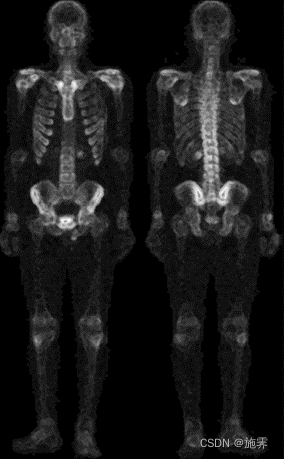 |
第三部分:将前两部分处理后的图像进行叠加操作,将所有增强的特征细节汇去在一张图像上,并将图像进行灰度幂变换提亮整体的图像
- 使用cv2.addWeighted()函数将前两部分的图像叠加;
- 使用灰度幂变换对处理后的图像做最后的处理,常数c=1,γ=0.6;
| 将所有的效果图叠加 | 灰度幂变换 |
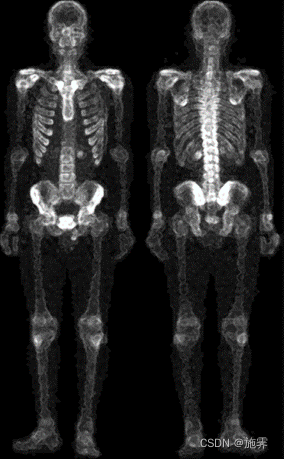 | 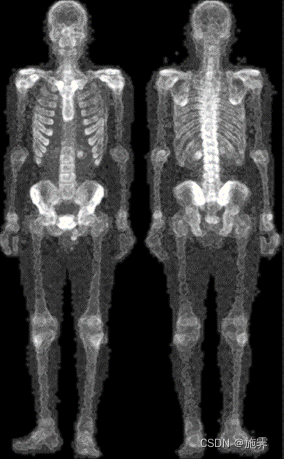 |
结果分析:通过上述步骤处理后的效果图骨骼结构得到了明显的增强,同时肉质细节等灰度变化缓慢的部分也得到了显著增强,效果可嘉(自我评价);美中不足的是仍然存在小部分的噪点没有平滑掉,考虑用频域增强技术解决,利用高频提升滤波器等等。
下面是在Jupyter notebook运行的代码:
import cv2
import math
import numpy as np
import matplotlib.pyplot as plt
<h2>第一步: 以imread方式读取灰度图</h2>
path = './Human.png'
# 原图展示
original = cv2.imread(path)
cv2.imshow('Original', original)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 以imread方式读入图片
img = cv2.imread(path, 0)
# 利用高斯滤波平滑降噪
blur = cv2.GaussianBlur(img, (7,7), 0)
"""Prewitt算子适合用来识别噪声较多、灰度渐变的图像,相比于Roberts算子,在水平方向和竖直方向上对边缘的检测更加明显"""
# 利用Prewitt算子增强骨骼细节
kernelx = np.array([[1, 1, 1], [0, 0, 0], [-1, -1, -1]], dtype=int)
kernely = np.array([[-1, 0, 1], [-1, 0, 1], [-1, 0, 1]], dtype=int)
x = cv2.filter2D(img, cv2.CV_16S, kernelx)
y = cv2.filter2D(img, cv2.CV_16S, kernely)
# 转uint8
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Prewitt = cv2.addWeighted(absX, 1., absY, 1., 0)
cv2.imshow('Prewitt', Prewitt)
cv2.imwrite('Prewitt.png', Prewitt)
cv2.waitKey(0)
cv2.destroyAllWindows()
"""--------叠加-------"""
# 将处理后的图像叠加到img上
img_Prewitt = cv2.add(img, Prewitt)
cv2.imshow('img_Prewitt', img_Prewitt)
cv2.imwrite('img_Prewitt.png', img_Prewitt)
cv2.waitKey(0)
cv2.destroyAllWindows()
<h2>第二步: 以cvtColor读取灰度图</h2>
# 以cvtColor读入
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imshow('o', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 利用高斯滤波降噪
blur = cv2.GaussianBlur(img, (7,7), 0)
# 利用Laplacian增强骨骼图像细节
def Laplace(img):
h = img.shape[0]
w = img.shape[1]
res = img.copy()
L = np.array([[-1,-1, -1],
[-1, 8, -1],
[-1,-1, -1]])
for i in range(h - 2):
for j in range(w - 2):
res[i + 1, j + 1] = np.clip(np.abs(np.sum(img[i:i + 3, j:j + 3] * L)), 0, 255)
return np.uint8(res)
Laplacian = Laplace(blur)
# 将原始图像与Laplacian处理后的图像叠加
img_Laplacian = cv2.addWeighted(img, 1.0, Laplacian, 1.0, 0)
cv2.imshow('Laplacian', Laplacian)
cv2.imwrite('Laplacian.png', Laplacian)
cv2.imshow('img_Laplacian', img_Laplacian)
# 保存Laplacian处理后的图像
cv2.imwrite('img_Laplacian.png', img_Laplacian)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 利用Sobel算子增强灰度变化较弱的细节——>肉质细节
x = cv2.Sobel(img, cv2.CV_16S, 1, 0, ksize=3)
y = cv2.Sobel(img, cv2.CV_16S, 0, 1, ksize=3)
absx = cv2.convertScaleAbs(x)
absy = cv2.convertScaleAbs(y)
Sobel = cv2.addWeighted(absx, 1., absy, 1., 0)
# 结合图像的空间邻近度和像素值相似度的一种折衷处理,同时考虑了像素空间差异与强度差异,达到保边去噪的目的。
# 均值滤波、中值滤波和高斯滤波,都属于各向同性滤波,它们对待噪声和图像的边缘信息都采取一视同仁的处理方式,
# 噪声被磨平的同时,图像中具有重要地位的边缘、纹理和细节也同时被抹平
# 利用双边滤波平滑噪声并保留边界
img_Sobel = cv2.bilateralFilter(Sobel, 5, 11, 11)
cv2.imshow('Sobel', Sobel)
cv2.imwrite('Sobel.png', Sobel)
cv2.imshow('img_Sobel',img_Sobel)
cv2.imwrite('img_Sobel.png', img_Sobel)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 将上述两个代码块的图像按指定权重叠加保留变化强烈的写别,平滑灰度变化平缓的噪声
# 图像融合
blend = cv2.addWeighted(img_Laplacian, .5, img_Sobel, .5, 0)
# blend = cv2.add(img_Laplacian, img_Sobel)
# 将结果转换回 uint8 类型
blend = np.clip(blend, 0, 255).astype(np.uint8)
cv2.imshow("blend", blend)
cv2.imwrite('blend.png', blend)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 利用中值滤波再次平滑图像
img_Spicy = cv2.medianBlur(blend, 3)
cv2.imshow('img_Spicy', img_Spicy)
cv2.imwrite('img_Spicy.png', img_Spicy)
cv2.waitKey(0)
cv2.destroyAllWindows()
<h2>第三步: 将两种方式处理的图像叠加</h2>
# 将两种方式处理后的图像叠加
add = cv2.addWeighted(img_Prewitt, 0.3, img_Spicy, 1.0, 0)
cv2.imshow('add', add)
cv2.imwrite('add.png', add)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 将结果叠加到原图并做灰度图幂变换
def gammaTranform(c, gamma, image):
h, w = image.shape[0],image.shape[1]
new_img = np.zeros((h,w),dtype=np.float32)
for i in range(h):
for j in range(w):
new_img[i, j] = c*math.pow(image[i, j], gamma)
cv2.normalize(new_img, new_img, 0, 255, cv2.NORM_MINMAX)
new_img = cv2.convertScaleAbs(new_img)
return new_img
res = gammaTranform(1 , 0.6, add)
cv2.imshow('res', res)
cv2.imwrite('res.png', res)
cv2.waitKey(0)
cv2.destroyAllWindows()















 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











