






目录
前言
本文为笔者在学习FAST-LIO时的学习笔记,如有问题欢迎指出,希望能和大家一起交流学习
1 一些概念
1.1 流形(Manifold )
1.1.1 定义:局部具有欧几里得空间性质的 空间 ,在数学上用于描述几何形体
流形学的观点是认为,我们所能观察到的数据实际上是由一个低维流形映射到高维空间上的,即这些数据所在的空间是“嵌入在高维空间的低维流形”。如,一维流形是曲线,二维流形是曲面,三维流形是我们所熟知的物理空间。
注意:流形是空间,不是形状
1.1.2 作用:
-
高维空间有冗余,通过流形的方式对数据进行降维。
eg:三维空间中的一个球面,用xyz桑坐标轴确定时会产生冗余,只需要用经纬两个坐标就可以确定了。所以三维空间中的球面就是一个二维流形
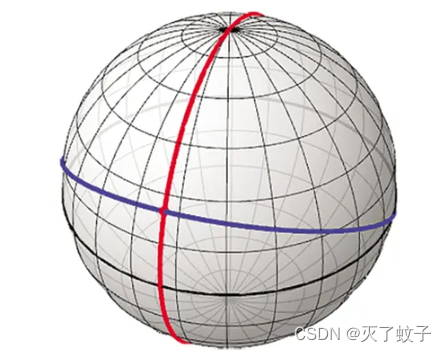
局部同胚
设流形为M,对于所有x属于M 并且 一个包含x的开子集U属于M,存在一个双射函数【同胚】fi,能将U中的点映射到R上
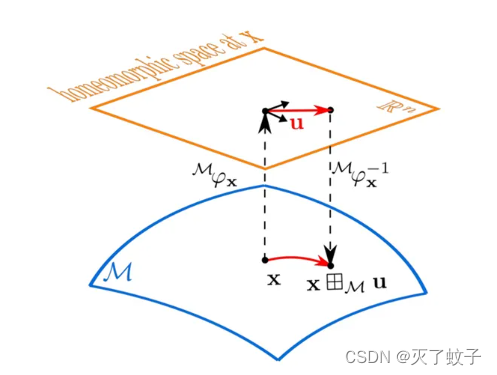
于是乎,我们得到广义加、广义减的定义
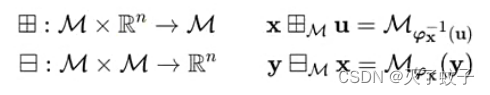
(原谅我打不出这俩符号,只能发挥大家丰富的想象力了)
田:流形M上一个元素 与 R^n上一个元素进行运算,结果还在流形M上,参考上图流形M上的点x
日:流形M上两个元素进行运算,结果是R^n上的向量
上述可能有点抽象,但是当M为SO(3)时,
![]()
流形上x加一个向量空间的u,相对于旋转矩阵加一个扰动u
第二个式子就相对于求李代数上的扰动u
1.2 松耦合与紧耦合
1.2.1 松耦合
原理:分别处理激光雷达与IMU测量结果,并在后端融合两者结果
优点:激光雷达点云配准与IMU积分数据松耦合融合方法减少了计算负载
缺点:忽略了系统的其他状态(例如速度)与激光雷达重新扫描姿态之间的相关性。此外,在无特征的情况下,激光雷达点云配准可能在某些方向上退化,点云配准退化,会导致后端融合不再可靠
1.2.2 紧耦合
原理:将激光雷达的原始特征点(而不是点云配准结果)与IMU数据融合。
实现紧耦合LIO的两种主要方法:①基于优化②基于滤波器
1.3 IMU 连续模型和离散模型
1.3.1 连续模型
由于我们的IMU与雷达是刚性安装在机器人上的,它们的相对位置不会发生变化,因此它是一个欧式变化,只包括旋转、平移。
我们通过 ①物理测量与 ②传感器标定 ,可以得到Lidar到IMU的外参矩阵,反之乘上-1即可。
①物理测量,拿把卷尺,手动测量雷达和IMU的相对位置
②传感器标定教程参考大佬的文章LIO-SAM运行自己数据包遇到的问题解决--SLAM不学无数术小问题_lio_sam 建图不清晰-CSDN博客
Tips:【若选择②,记得标定完检查下参数是否正常,笔者曾踩过坑,使用标定功能包得到了很离谱的数据】
雷达和IMU的关系可用下式表示
进而推出运动学模型:



测量模型
测量值=真值+噪声+零偏
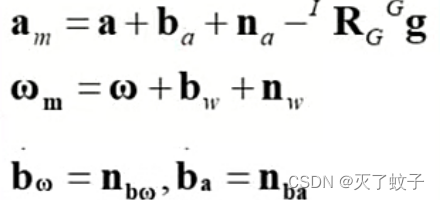
需要注意的是,加速度测量值的计算,需减去重力加速度的影响,由于我们需要转换到IMU坐标系下,还需乘上I^R_G
其余跟中学公式很像,此处不再赘述
1.3.2 离散模型
基于上面定义的运算,我们可以在IMU采样周期delta_t 处使用零阶保持器对连续模型进行离散化。得到的离散模型为
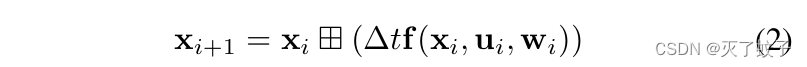
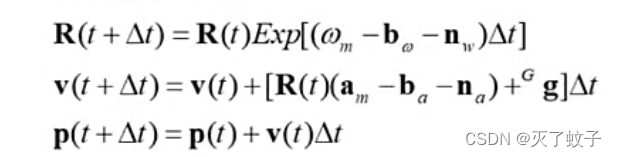
零阶保持器: 将采样信号转变为在两个连续采样瞬时之间保持常量的信号。
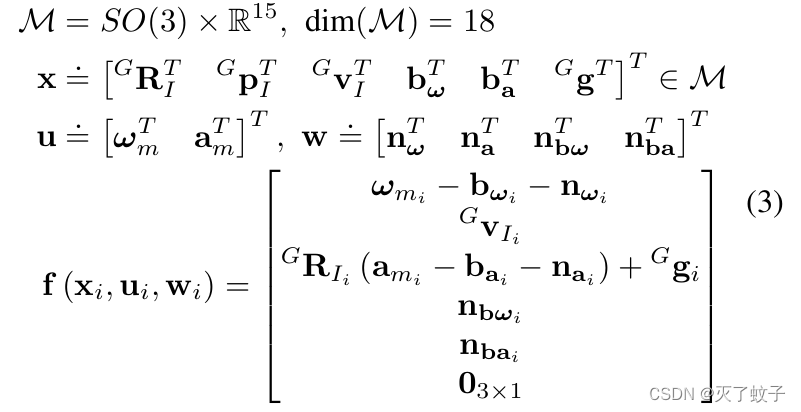
2 论文学习
论文引入了两个符号,广义加、广义减
![]()
定义M是一个n维的流形(流形定义参考上文):
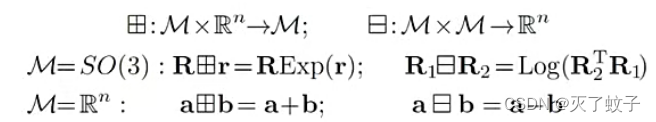
(1)当R是SO(3)旋转矩阵,r是一个三维向量,那么R田r,得到R乘r的指数映射
(2)当a、b都是R^n上的向量,运算就如平时的向量加减
2.1 框架
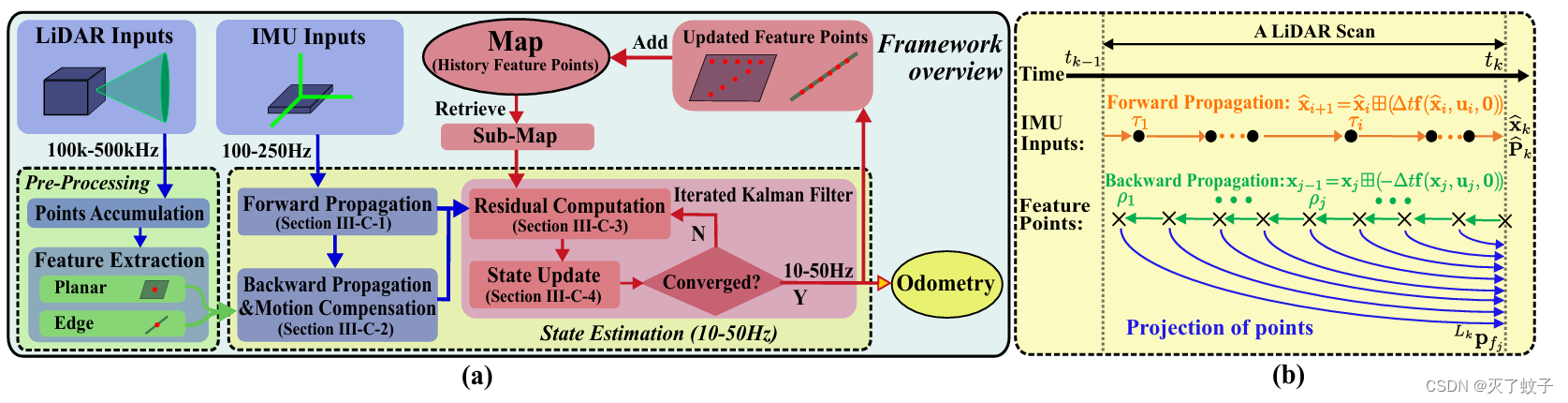
图(a)
-
雷达输入到预处理模块——>点累积到一定数量——>特征提取——>获得面点和角点
-
IMU输入进行前向传播(积分得到粗略位姿估计),反向传播进行运动补偿
-
计算雷达里程计残差,利用迭代卡尔曼滤波估计位姿变换,直到收敛
-
更新点云地图,下采样——>用于下一步注册更多的新点
2.2 创新点
之前算法存在的问题:
-
易受到无特征环境或小视场(FOV)激光雷达的影响
-
特征点数量多,计算量大
-
激光点采样时间不同,导致运动失真
创新:
-
高计算效率、高鲁棒性的雷达里程计;1200特征点25ms
-
紧耦合迭代扩展卡尔曼滤波,融合雷达特征点和IMU测量,提出反向传播来弥补运动失真;
-
新卡尔曼增益计算公式;
2.3 雷达数据预处理
2.3.1 雷达点累积(间隔采样)
-
为什么:原始雷达点采样频率非常高,不会一接收到新点就对其处理,这样会导致计算量大、效率低下。于是采用累积的方法,就像拼夕夕拉满多少助力就能拿到现金红包,不好意思跑偏了。累积法将一段时间内【默认最小累积时间间隔为20ms】的点统一进行处理,这段时间内的点作为一次scan。
-
好处:提高状态估计【里程计输出】、地图更新频率
2.3.2特征提取
曲率计算公式:
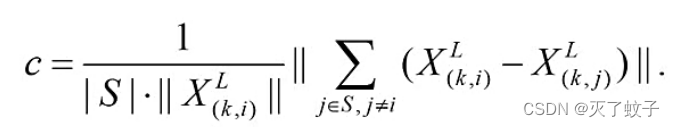
S:相同scan的近邻点集
上式可以用下图表示,
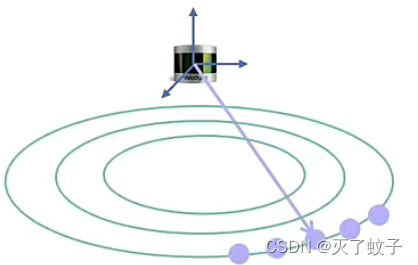
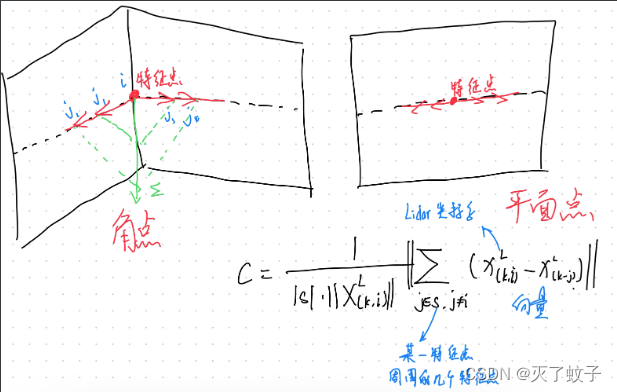
曲率C大的为角点,小的为面点。
详细讲解见如何轻松拿捏LIO-SAM-LOAM论文及原理讲解_哔哩哔哩_bilibili
2.4 状态估计
为估计状态量,使用了迭代扩展卡尔曼滤波IEKF,
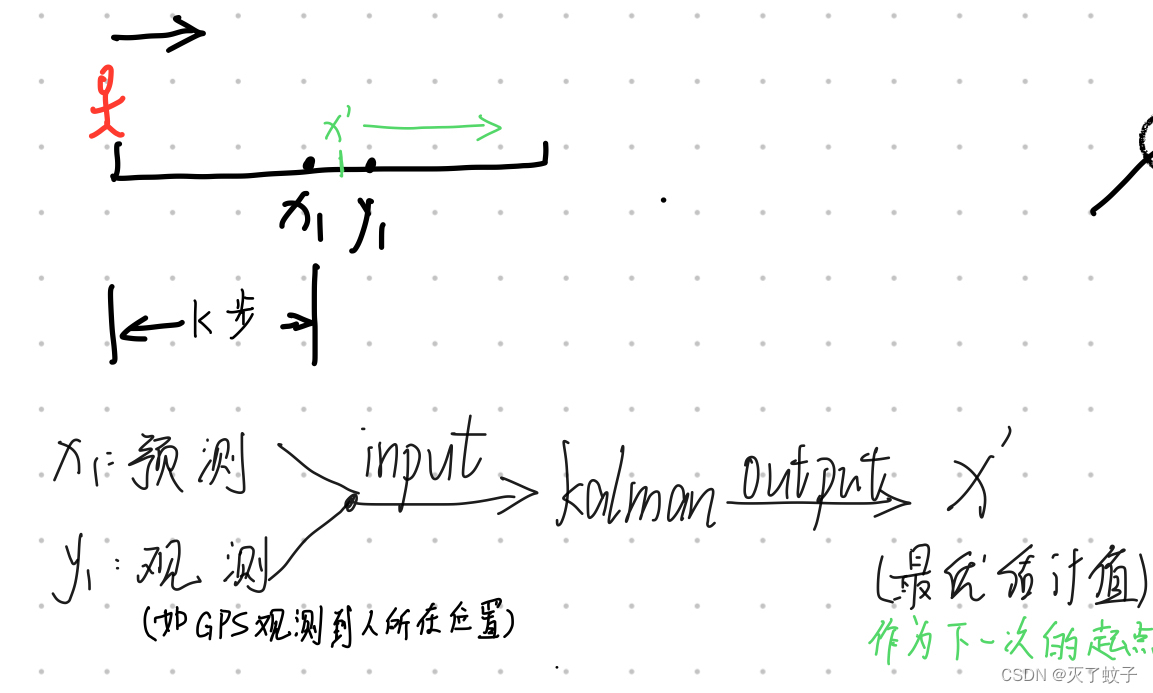
举个栗子,有一个人从起点出发,走了K步。x1为他预测自己所在的地方,y1是GPS观测到他所在地。将这两个数据输入给卡尔曼滤波器,输出一个最优估计值x',作为下一次的起点,再重复上述过程,直到到达目的地
2.4.1 雷达IMU数据处理
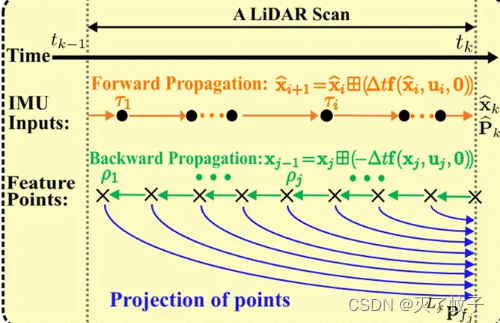

1. 前向传播(状态估计)
看到这个词不禁让我联想到,深度学习中的一张插图,
(输入层——隐藏层——输出层,上一层的输出作为下一层的输入,并计算下一层的输出,直到运算到输出层为止)
只不过此处我们的输入输出数据为
输入:IMU数据
输出:状态量(估计的位移、加速度、误差量、协方差矩阵等)
目的:
-
对两帧雷达间的IMU积分,得到预估位置变换
-
传递误差量的变化【因为FAST-LIO采用误差状态卡尔曼滤波】——>传递误差量的协方差矩阵——>用于迭代更新
步骤:
-
利用IMU积分算出一个粗略的状态量(用于反向传播)
-
计算传播误差量
-
计算协方差矩阵
-
直至搜索到最终时刻,结束
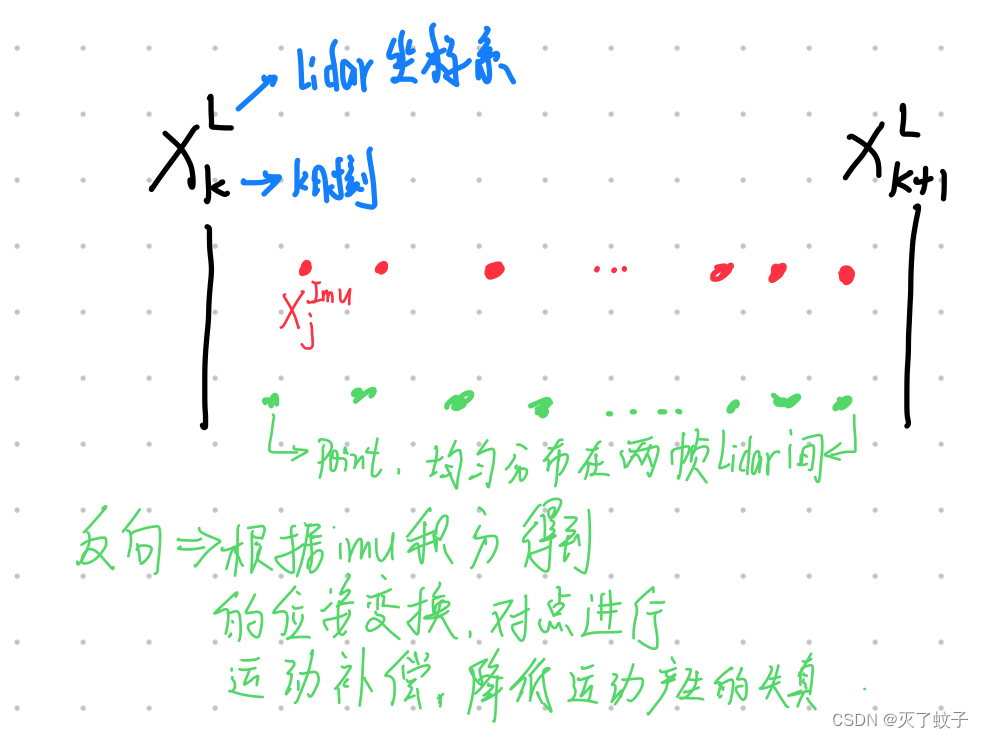
2. 反向传播和运动补偿
原理:根据IMU积分得到的 位姿变换 ,估计扫描中每个点相对于扫描结束时间的位姿的激光雷达位姿。估计的相对姿态使我们能够根据扫描中每个单独点的精确采样时间,将所有点投射到扫描结束时间。
反向传播的目的:补偿运动失真/去除运动畸变
3 总结:前向传播与反向传播
2.4.2 残差
定义:残差是或预期模型之间的差异。通常使用距离度量来定义残差,比如点到地图或模型的最近距离。
存在原因:进行特征提取时,会将得到的间隔采样雷达数据点与现有的地图数据点相比较,并提取出其中更加接近的系列特征点,而在这个过程中存在着偏差。
常用方法:
-
ICP:通过最小化两个点云或线段的距离度量来优化点云的对齐
-
点到平面、点到线:将地图表示为平面or线段,计算到每个点的距离
-
特征匹配:kd-Tree中搜索得到
输入:前向传播得到的状态量,反向传播输出的(补偿后的)点云
残差计算:
-
角点:点到近邻直线距离
-
面点:点到近邻平面距离
-
通过优化位姿,使残差和趋于0
残差 = dist | 特征点的估计全局坐标 - 地图上最近的平面或边缘点 |
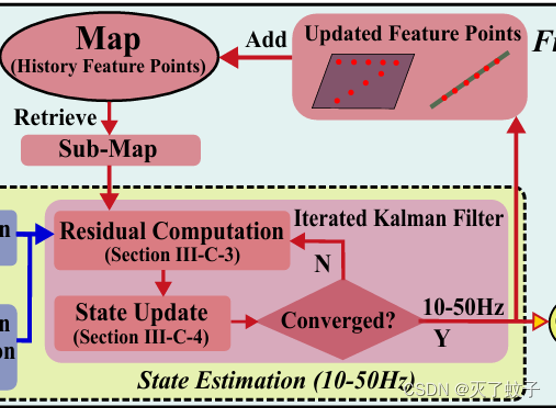
计算完残差后,通过误差状态卡尔曼滤波器,进行状态更新,一直迭代直到收敛
2.4.3 误差卡尔曼滤波器ESKF
-
为什么要使用ESKF
-
旋转的误差状态通常是一个很小的值,
-
ESKF通常用旋转向量表示,四元数过参数化(用4X4的协方差矩阵表示三自由度)
-
传统卡尔曼滤波器(及其变种)具有时间复杂度O(m²),其中m是测量维度,这可能导致在处理大量激光雷达测量数据时候计算负载非常高
-
过程
ESKF估计的是误差量 𝑥~,结合状态量的估计——>得到最优估计x-,如下
我们再回到刚刚人走路的例子,他从起点出发走了K步(按照他认为均匀步长走)。x1为他预测自己所在的地方,y1是GPS观测到他所在地。【这跟刚刚一样】,不同的是,输入给卡尔曼滤波器的数据换成了x1和y1误差量,即小人自己估算他步长的误差量,以及GPS观测与小人预测之间的误差。
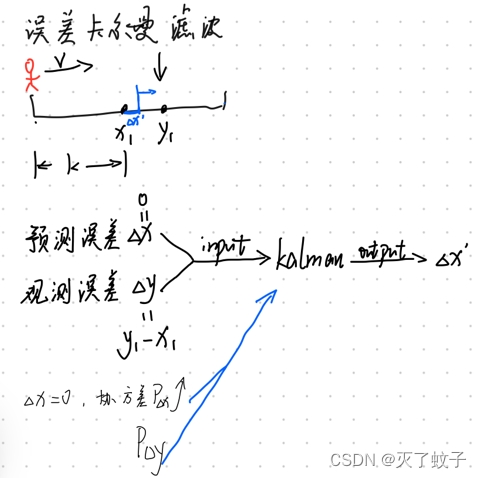
由于步长是小人自己认为走的均匀的,他每次以自己认为的步长(比如50厘米)进行运动,那他每次预测的误差就是0。但是由于他在运动,协方差是不断增加的,于是乎我们将预测误差、观测误差、两个协方差输入给卡尔曼滤波器,得到误差量delta_x',那么得到最终的估算位置就是【x1+误差量delta_x'】,再以该点为下一个起点,重复上述操作,直至抵达目标点/收敛。
收敛后把新点云插入全局地图中,同时,从地图下采样的submap中通过残差计算寻找近邻点,见下图
3 FAST-LIO2
比较:FAST-LIO2相较于1,做了以下改进:
-
状态估计方面,状态变量变为24维【FL1有18维,此处增加了旋转、平移的外参共六个维度】
-
直接将原始点云注册到地图,不提取特征
-
建图方面,论文提出了ikd-Tree的方法
解决问题:
-
减少计算量
-
地图数据庞大,需要支持有效的查询通信搜索,同时实时更新,纳入新的测量
后期笔者将整理FAST-LIO2改进部分的笔记,与大家一同学习、讨论。















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









