







一、随机匹配用户思路
1. 匹配个数:匹配多个,按照匹配的相似度从高到低排序返回给用户
2. 用户匹配的依据
- 用户标签 tags 的相似度:共同标签越多,相似度越高,排名越高
- 没有匹配的用户,随机推荐
3. 举例:A B 匹配度比 A C 匹配度更高(标签相似度更高)
- 用户 A:[Java, 大一, 男]
- 用户 B:[Java, 大二, 男]
- 用户 C:[Python, 大二, 女]
4. 如何计算标签相似度:编辑距离算法
5. 带权重的相似度计算:余弦相似度算法
如与学习方向有关的标签权重更高,性别相关标签权重低或为零
二、编辑距离算法介绍
1. 参考文章:详解编辑距离算法-Levenshtein Distance-CSDN博客
2. 核心思想
- 字符串 1 通过最少多少次增删改字符的操作可以变为字符串 2
- 所需操作次数越少,说明相似度越高
3. 改造编辑距离算法
- 计算字符串列表 1 通过多少次增删改字符串的操作可以变为字符串列表 2
package com.example.usercenter.utils;
import java.util.List;
import java.util.Objects;
/**
* 算法工具类
* @author 乐小鑫
*/
public class AlgorithmUtils {
/**
* 编辑距离算法(用于计算最相似的两组标签)
* 原理:https://blog.csdn.net/DBC_121/article/details/104198838
*
* @param tagList1
* @param tagList2
* @return
*/
public static int minDistance(List<String> tagList1, List<String> tagList2) {
int n = tagList1.size();
int m = tagList2.size();
if (n * m == 0) {
return n + m;
}
int[][] d = new int[n + 1][m + 1];
for (int i = 0; i < n + 1; i++) {
d[i][0] = i;
}
for (int j = 0; j < m + 1; j++) {
d[0][j] = j;
}
for (int i = 1; i < n + 1; i++) {
for (int j = 1; j < m + 1; j++) {
int left = d[i - 1][j] + 1;
int down = d[i][j - 1] + 1;
int left_down = d[i - 1][j - 1];
if (!Objects.equals(tagList1.get(i - 1), tagList2.get(j - 1))) {
left_down += 1;
}
d[i][j] = Math.min(left, Math.min(down, left_down));
}
}
return d[n][m];
}
/**
* 编辑距离算法(用于计算最相似的两个字符串)
* 原理:https://blog.csdn.net/DBC_121/article/details/104198838
*
* @param word1
* @param word2
* @return
*/
public static int minDistance(String word1, String word2) {
int n = word1.length();
int m = word2.length();
if (n * m == 0) {
return n + m;
}
int[][] d = new int[n + 1][m + 1];
for (int i = 0; i < n + 1; i++) {
d[i][0] = i;
}
for (int j = 0; j < m + 1; j++) {
d[0][j] = j;
}
for (int i = 1; i < n + 1; i++) {
for (int j = 1; j < m + 1; j++) {
int left = d[i - 1][j] + 1;
int down = d[i][j - 1] + 1;
int left_down = d[i - 1][j - 1];
if (word1.charAt(i - 1) != word2.charAt(j - 1)) {
left_down += 1;
}
d[i][j] = Math.min(left, Math.min(down, left_down));
}
}
return d[n][m];
}
}
三、用户标签匹配性能优化✔
1. 旧方案:直接取出所有用户的标签,依次和当前用户的标签计算相似度(分数),取 Top N(耗时 54 s)
2. 存在问题:用户数量大,对数据库的操作和标签的计算耗时过长,资源消耗大
3. 优化方向
- 取消数据库查询的日志输出(取消日志后,耗时 20 s),性能显著提升

- 减少占用内存空间:使用的数据结构 Map 存储了所有计算出来的用户和标签相似度,内存占用高
- 维护一个固定长度的有序集合,只保留分数最高的几个用户
- 需要维护有序集合,判断某一相似度是否要加入集合需要时间
- 细节:计算出来相似度最高点的用户列表中要移除自己
- 只查需要的数据✔
- 过滤掉标签为空的用户
- 只查需要的字段:id 和 tags(优化后耗时 7 s)
- 提前将相似度较高的用户列表查好
- 提前缓存所有用户的标签列表(数据经常更新的不适用)
- 提前计算结果,保存到缓存中(针对 VIP 用户)
@Override
public List<User> matchUsers(long num, User loginUser) {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.select("id", "tags");// 只需要查询 id 和标签字段 tags
queryWrapper.isNotNull("tags");// 过滤标签字段为空的数据
List<User> userList = this.list(queryWrapper);
String tags = loginUser.getTags();
Gson gson = new Gson();
List<String> tagList = gson.fromJson(tags, new TypeToken<List<String>>() {
}.getType());// 将标签字符串转为字符串列表,用于编辑距离算法的比较
// 存储计算结果:用户列表的下标 - 相似度
List<Pair<User, Long>> list = new ArrayList<>();
// 依次计算所有用户和当前用户的相似度
for (int i = 0; i < userList.size(); i++) {
User user = userList.get(i);
String userTags = user.getTags();
// 无标签或者为当前用户自己
if (StringUtils.isBlank(userTags) || user.getId() == loginUser.getId()) {
continue;
}
List<String> userTagList = gson.fromJson(userTags, new TypeToken<List<String>>() {
}.getType());// 将标签字符串转为字符串列表,用于编辑距离算法的比较
// 调用编辑距离算法计算分数
long distance = AlgorithmUtils.minDistance(tagList, userTagList);
list.add(new Pair<>(user, distance));
}
// 按编辑距离由小到大排序:value 越小说明需要编辑的次数越少,标签相似度越高
List<Pair<User, Long>> topUserPairList = list.stream()
.sorted((a, b) -> (int) (a.getValue() - b.getValue()))
.limit(num)
.collect(Collectors.toList());
// 原本顺序的 userId 列表
List<Long> userIdList = topUserPairList.stream().map(pair -> pair.getKey().getId()).collect(Collectors.toList());
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
userQueryWrapper.in("id", userIdList);
// 1, 3, 2
// User1、User2、User3
// 1 => User1, 2 => User2, 3 => User3
Map<Long, List<User>> userIdUserListMap = this.list(userQueryWrapper)
.stream()
.map(user -> getSafetyUser(user))
.collect(Collectors.groupingBy(User::getId));
List<User> finalUserList = new ArrayList<>();
for (Long userId : userIdList) {
finalUserList.add(userIdUserListMap.get(userId).get(0));
}
return finalUserList;
}
四、功能测试
1. 查看数据库中用户标签信息
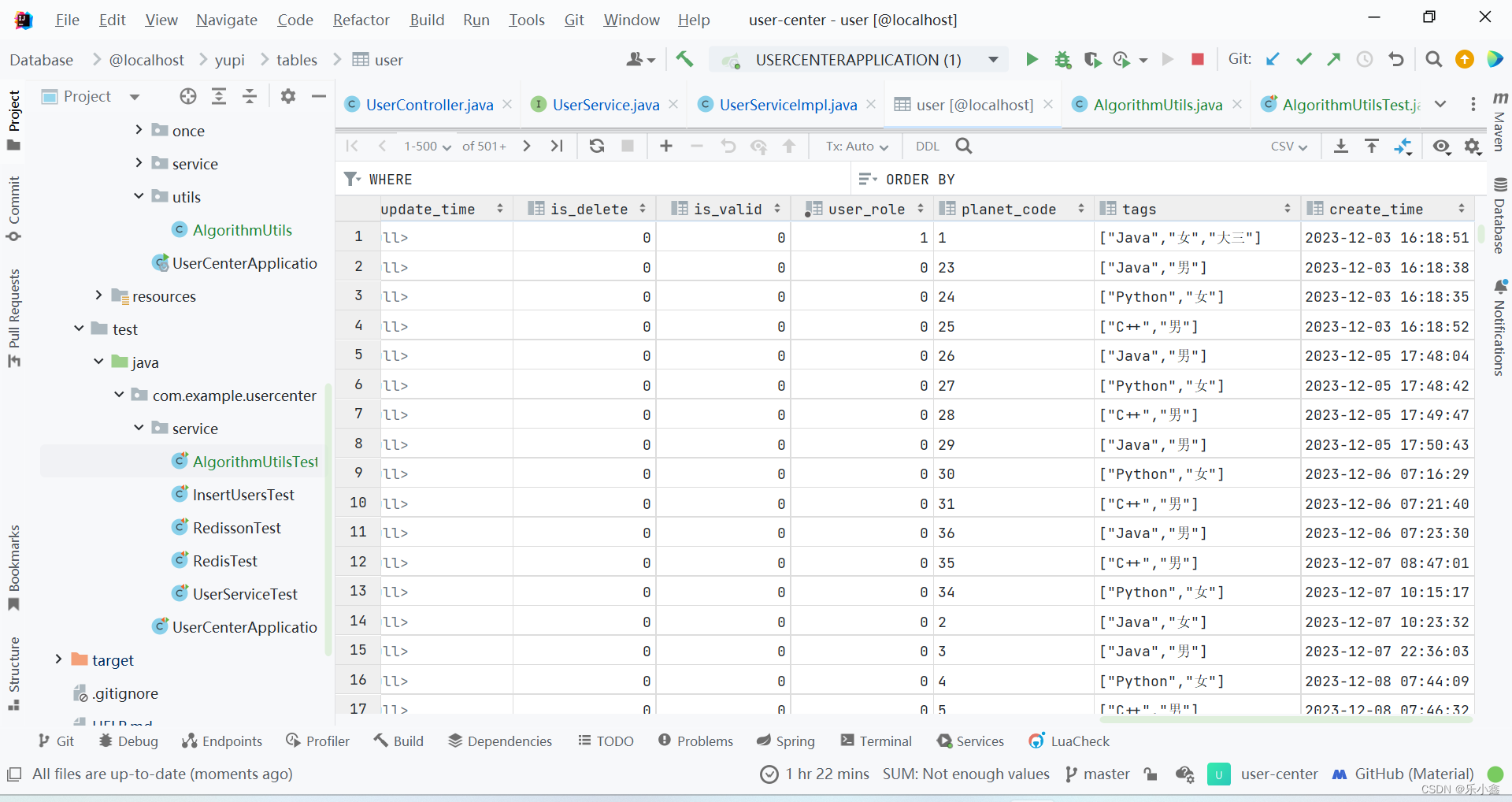
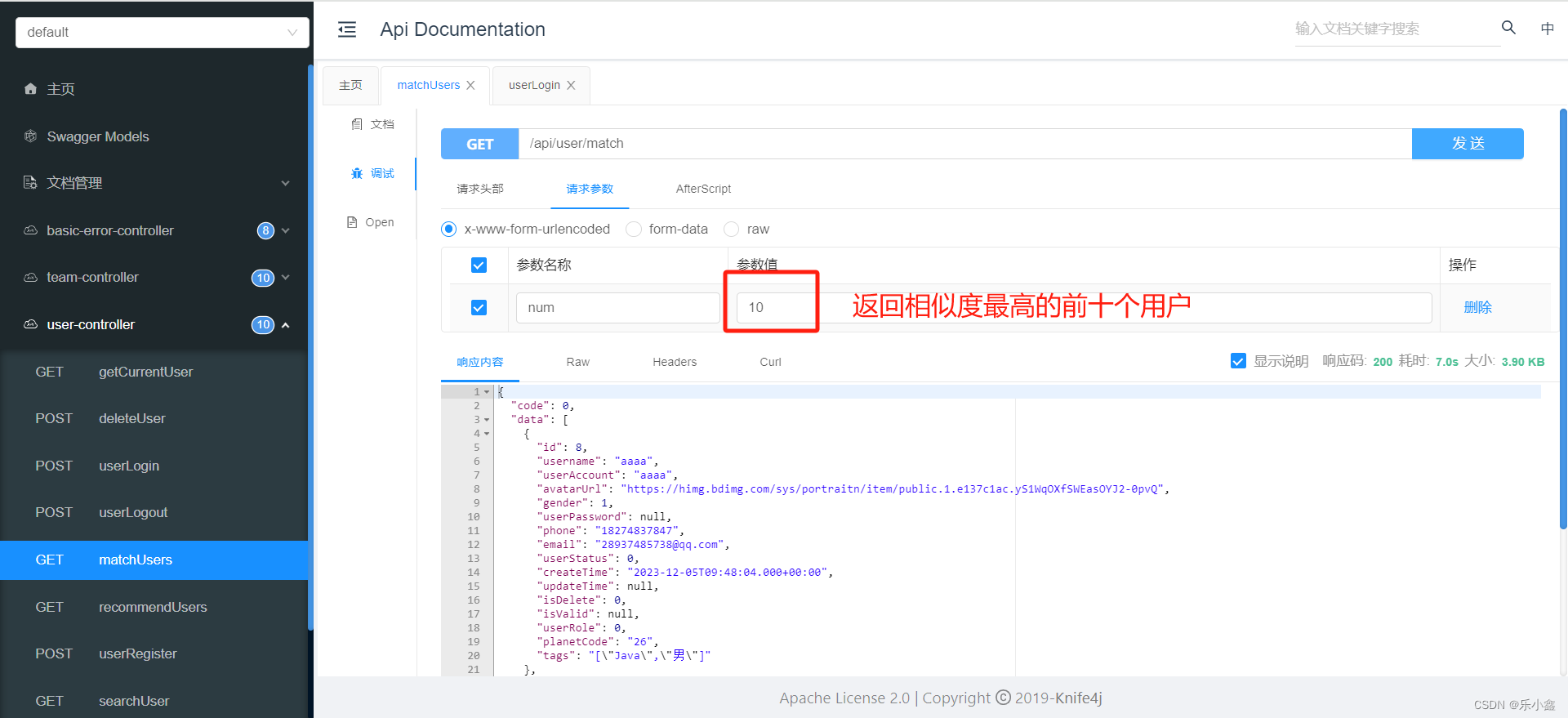
2. 使用 Knife4j 接口文档进行测试
- 测试返回的用户列表是否是按照标签相似度降序排序(越相似的排在越前面)

















 2151
2151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









