






0 RAG 概述
RAG(Retrieval Augmented Generation)技术,通过检索与用户输入相关的信息片段,并结合外部知识库来生成更准确、更丰富的回答。解决 LLMs 在处理知识密集型任务时可能遇到的挑战, 如幻觉、知识过时和缺乏透明、可追溯的推理过程等。提供更准确的回答、降低推理成本、实现外部记忆。
RAG 能够让基础模型实现非参数知识更新,无需训练就可以掌握新领域的知识。本次课程选用的茴香豆应用,就应用了 RAG 技术,可以快速、高效的搭建自己的知识领域助手。
1 环境配置
1.1 配置基础环境
进入开发机后,从官方环境复制运行 InternLM 的基础环境,命名为 InternLM2_Huixiangdou,在命令行模式下运行:
tudio-conda -o internlm-base -t InternLM2_Huixiangdou 
复制完成后,在本地查看环境。
conda env list 结果如下所示。

运行 conda 命令,激活 InternLM2_Huixiangdou python 虚拟环境:
conda activate InternLM2_Huixiangdou1.3 下载安装茴香豆
安装茴香豆运行所需依赖。
# 安装 python 依赖
# pip install -r requirements.txt
pip install protobuf==4.25.3 accelerate==0.28.0 aiohttp==3.9.3 auto-gptq==0.7.1 bcembedding==0.1.3 beautifulsoup4==4.8.2 einops==0.7.0 faiss-gpu==1.7.2 langchain==0.1.14 loguru==0.7.2 lxml_html_clean==0.1.0 openai==1.16.1 openpyxl==3.1.2 pandas==2.2.1 pydantic==2.6.4 pymupdf==1.24.1 python-docx==1.1.0 pytoml==0.1.21 readability-lxml==0.8.1 redis==5.0.3 requests==2.31.0 scikit-learn==1.4.1.post1 sentence_transformers==2.2.2 textract==1.6.5 tiktoken==0.6.0 transformers==4.39.3 transformers_stream_generator==0.0.5 unstructured==0.11.2
## 因为 Intern Studio 不支持对系统文件的永久修改,在 Intern Studio 安装部署的同学不建议安装 Word 依赖,后续的操作和作业不会涉及 Word 解析。
## 想要自己尝试解析 Word 文件的同学,uncomment 掉下面这行,安装解析 .doc .docx 必需的依赖
# apt update && apt -y install python-dev python libxml2-dev libxslt1-dev antiword unrtf poppler-utils pstotext tesseract-ocr flac ffmpeg lame libmad0 libsox-fmt-mp3 sox libjpeg-dev swig libpulse-dev 
从茴香豆官方仓库下载茴香豆。
cd /root # 克隆代码仓库
git clone https://github.com/internlm/huixiangdou && cd huixiangdou
git checkout ded0551 
茴香豆工具在 Intern Studio 开发机的安装工作结束。
2 使用茴香豆搭建 RAG 助手
2.1 修改配置文件
用已下载模型的路径替换 /root/huixiangdou/config.ini 文件中的默认模型,需要修改 3 处模型地址,分别是:
命令行输入下面的命令,修改用于向量数据库和词嵌入的模型
sed -i '6s#.*#embedding_model_path = "/root/models/bce-embedding-base_v1"#' /root/huixiangdou/config.ini 用于检索的重排序模型
sed -i '7s#.*#reranker_model_path = "/root/models/bce-reranker-base_v1"#' /root/huixiangdou/config.ini 和本次选用的大模型
sed -i '29s#.*#local_llm_path = "/root/models/internlm2-chat-7b"#' /root/huixiangdou/config.ini 修改好的配置文件应该如下图所示:
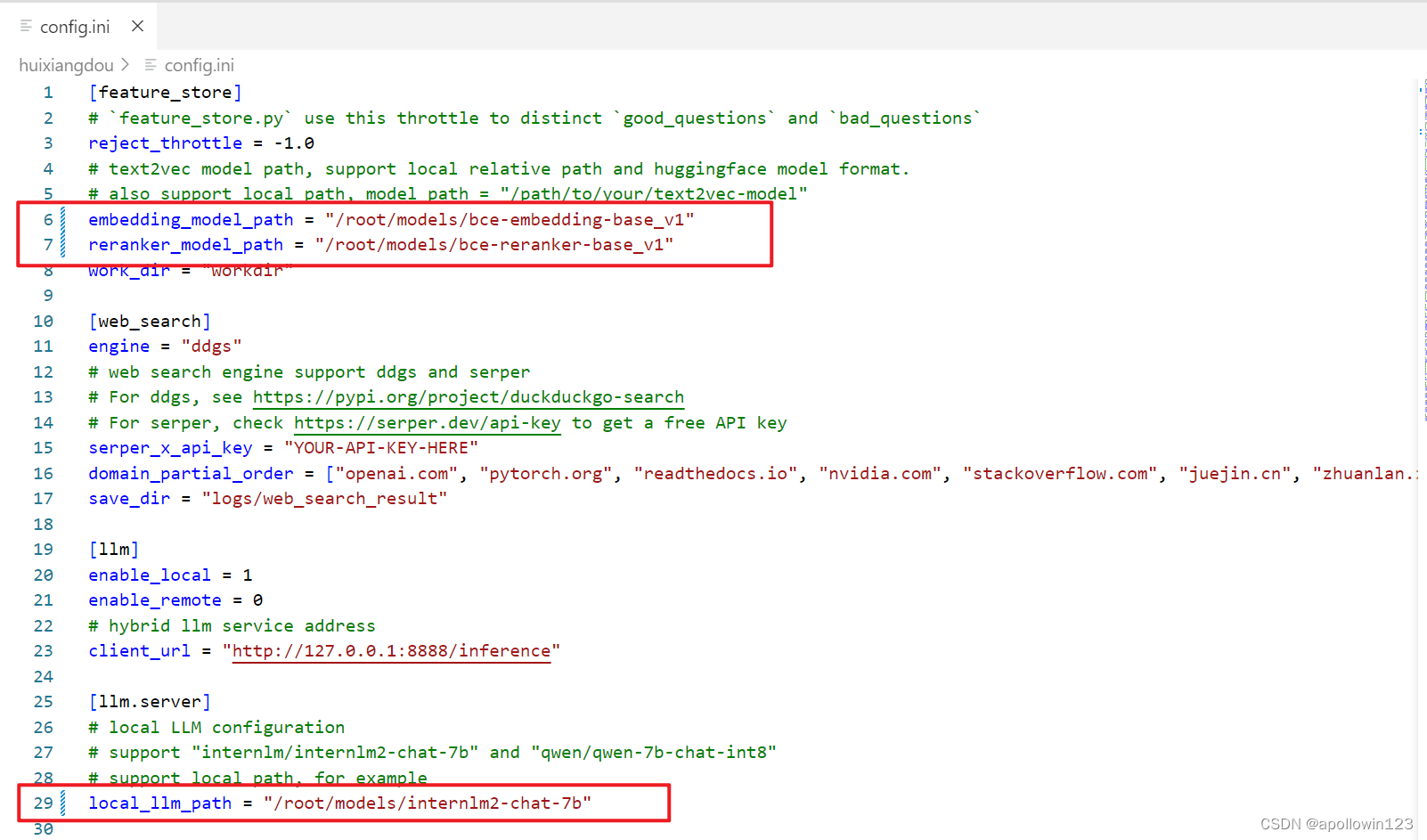
2.2 创建知识库
本示例中,使用 InternLM 的 Huixiangdou 文档作为新增知识数据检索来源,在不重新训练的情况下,打造一个 Huixiangdou 技术问答助手。
首先,下载 Huixiangdou 语料:
cd /root/huixiangdou && mkdir repodir
git clone https://github.com/internlm/huixiangdou --depth=1 repodir/huixiangdou 
提取知识库特征,创建向量数据库。数据库向量化的过程应用到了 LangChain 的相关模块,默认嵌入和重排序模型调用的网易 BCE 双语模型,如果没有在 config.ini 文件中指定本地模型路径,茴香豆将自动从 HuggingFace 拉取默认模型。
除了语料知识的向量数据库,茴香豆建立接受和拒答两个向量数据库,用来在检索的过程中更加精确的判断提问的相关性,这两个数据库的来源分别是:
- 接受问题列表,希望茴香豆助手回答的示例问题
- 存储在
huixiangdou/resource/good_questions.json中
- 存储在
- 拒绝问题列表,希望茴香豆助手拒答的示例问题
- 存储在
huixiangdou/resource/bad_questions.json中 - 其中多为技术无关的主题或闲聊
- 如:"nihui 是谁", "具体在哪些位置进行修改?", "你是谁?", "1+1"
- 存储在
运行下面的命令,增加茴香豆相关的问题到接受问题示例中:
在确定好语料来源后,运行下面的命令,创建 RAG 检索过程中使用的向量数据库:
# 创建向量数据库存储目录
cd /root/huixiangdou && mkdir workdir
# 分别向量化知识语料、接受问题和拒绝问题中后保存到 workdir
python3 -m huixiangdou.service.feature_store --sample ./test_queries.json 向量数据库的创建需要等待一小段时间,过程约占用 1.6G 显存。
2.3 运行茴香豆知识助手
我们已经提取了知识库特征,并创建了对应的向量数据库。现在,让我们来测试一下效果:
命令行运行:
# 填入问题
sed -i '74s/.*/ queries = ["huixiangdou 是什么?", "茴香豆怎么部署到微信群", "今天天气怎么样?"]/' /root/huixiangdou/huixiangdou/main.py
# 运行茴香豆
cd /root/huixiangdou/
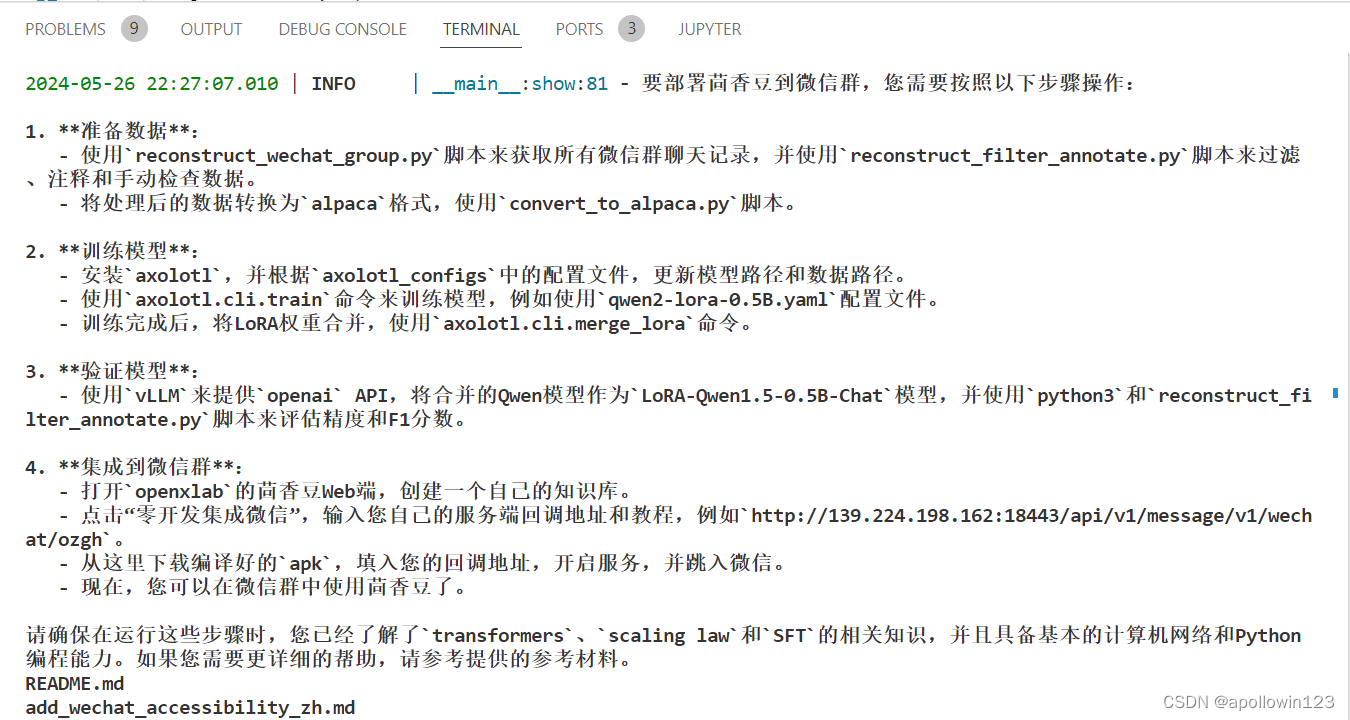
python3 -m huixiangdou.main --standalone RAG 技术的优势就是非参数化的模型调优,这里使用的仍然是基础模型 InternLM2-Chat-7B, 没有任何额外数据的训练。面对同样的问题,我们的茴香豆技术助理能够根据我们提供的数据库生成准确的答案:
回答结果如下:
3 茴香豆进阶(待更新)
3.1 利用 Gradio 搭建网页 Demo
让我们用 Gradio 搭建一个自己的网页对话 Demo,来看看效果。
- 首先,安装 Gradio 依赖组件:
pip install gradio==4.25.0 redis==5.0.3 flask==3.0.2 lark_oapi==1.2.4 - 运行脚本,启动茴香豆对话 Demo 服务:
d /root/huixiangdou python3 -m tests.test_query_gradio 














 146
146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









