







原论文地址:原论文下载地址
即插即用的多尺度全局注意力机制
本文提出了一种新颖的多尺度空洞 Transformer,简称DilateFormer,以用于视觉识别任务。原有的 ViT 模型在计算复杂性和感受野大小之间的权衡上存在矛盾。众所周知,ViT 模型使用全局注意力机制,能够在任意图像块之间建立长远距离上下文依赖关系,但是全局感受野带来的是平方级别的计算代价。同时,有些研究表明,在浅层特征上,直接进行全局依赖性建模可能存在冗余,因此是没必要的。为了克服这些问题,作者提出了一种新的注意力机制——多尺度空洞注意力(MSDA)。MSDA 能够模拟小范围内的局部和稀疏的图像块交互,这些发现源自于对 ViTs 在浅层次上全局注意力中图像块交互的分析。作者发现在浅层次上,注意力矩阵具有局部性和稀疏性两个关键属性,这表明在浅层次的语义建模中,远离查询块的块大部分无关,因此全局注意力模块中存在大量的冗余。
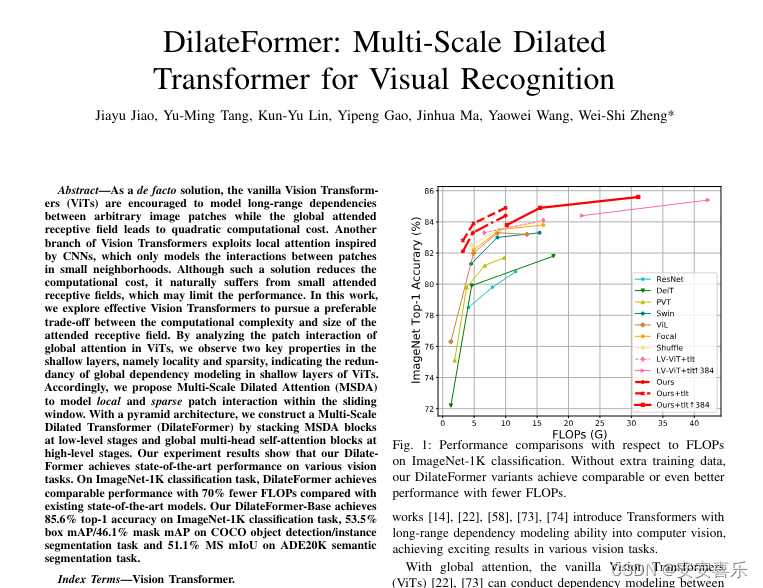

DilateFormer 是一个以金字塔结构为基础的深度学习模型,它主要设计用来处理基础的视觉任务。DilateFormer 的关键设计概念是利用多尺度空洞注意力(Multi-Scale Dilated Attention, MSDA)来有效捕捉多尺度的语义信息,并减少自注意力机制的冗余。
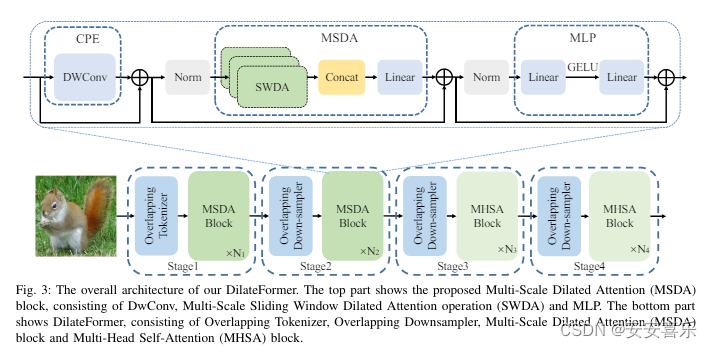 如上图所示,
如上图所示,DilateFormer的整体架构主要由四个阶段构成。在第一阶段和第二阶段,使用 MSDA,而在后两个阶段,使用普通的多头自注意力(MHSA)。对于图像输入,DilateFormer 首先使用重叠的分词器进行 patch 嵌入,然后通过交替控制卷积核的步长大小(1或2)来调整输出特征图的分辨率。对于前一阶段的 patches,采用了一个重叠的下采样器,具有重叠的内核大小为 3,步长为 2。整个模型的每一部分都使用了条件位置嵌入(CPE)来使位置编码适应不同分辨率的输入。
2.MSDA引入到YOLOv8的步骤:
2.1 MSDA加入ultralytics/nn/attention/dilateformer.py
import torch
import torch.nn as nn
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class DilateAttention(nn.Module):
"Implementation of Dilate-attention"
def __init__(self, head_dim, qk_scale=None, attn_drop=0, kernel_size=3, dilation=1):
super().__init__()
self.head_dim = head_dim
self.scale = qk_scale or head_dim ** -0.5
self.kernel_size=kernel_size 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3231
3231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











