






一 算子开发的概念:
华为CANN算子库包含了丰富的高性能算子,让神经网络的运行性能更高。CANN算子库中的算子都是预先实现和编译的,是华为工程师使用昇腾AI处理器架构专用编程语言开发的高度优化的内核函数,能够较好的适配底层硬件架构,具有较高的性能。
一般场景下,开发者无需自己开发算子。但若遇到以下场景,开发者需要考虑进行自定义算子的开发:
- 训练场景下,将第三方框架(例如TensorFlow、PyTorch等)的网络训练脚本迁移到昇腾AI处理器时遇到了不支持的算子。
- 推理场景下,将第三方框架模型(例如TensorFlow、Caffe、ONNX等)使用ATC工具转换为适配昇腾AI处理器的离线模型时遇到了不支持的算子。
- 网络调优时,发现某算子性能较低,影响网络性能,需要重新开发一个高性能算子替换性能较低的算子。
- 推理场景下,若应用程序中的某些逻辑涉及到数学运算(例如查找最大值,进行数据类型转换等),开发者可以将这些操作通过自定义算子的方式进行实现,然后在应用程序中对算子进行调用,算子在AI处理器运行,可以达到利用AI处理器进行性能提升的目的。 首先看下CANN算子在昇腾AI处理器中的位置,如图1所示:
- AI Core是昇腾AI处理器的计算核心,负责执行矩阵、向量、标量计算密集的算子任务,在AI Core上执行的算子称为TBE(Tensor Boost Engine)算子。
- AI CPU负责执行不适合跑在AI Core上的算子,是AI Core算子的补充,主要承担非矩阵类、逻辑比较复杂的分支密集型计算,在AI CPU上执行的算子称为AI CPU算子。
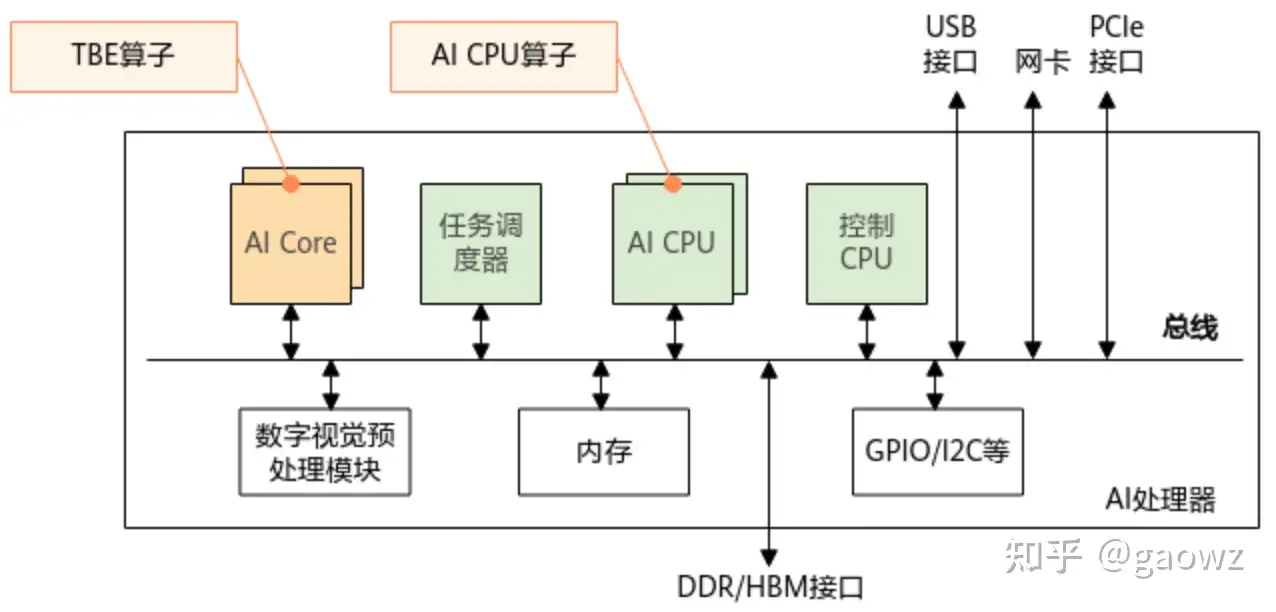
图1 CANN算子在昇腾AI处理器上的位置
本文记录了使用TIK C++,开发运行在AI Core(图2)上的TBE矢量算子的学习关键步骤。
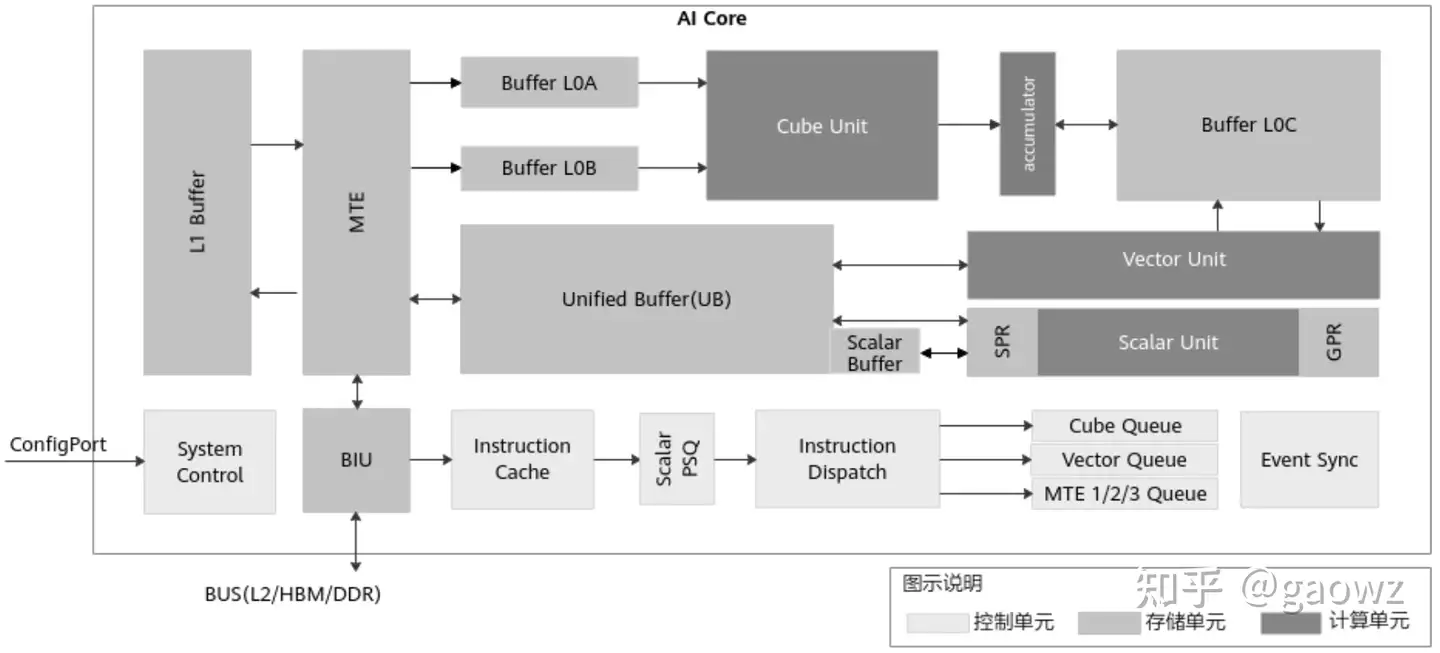
图2 AI Core架构图
二 使用TIK C++开发算子:
TIK C++是一种使用C/C++作为前端语言的算子开发工具,通过四层接口抽象、并行编程范式、CPU侧模拟NPU孪生调试等技术,极大提高算子开发效率,助力AI开发者低成本完成算子开发和模型调优部署。开发流程如图3:
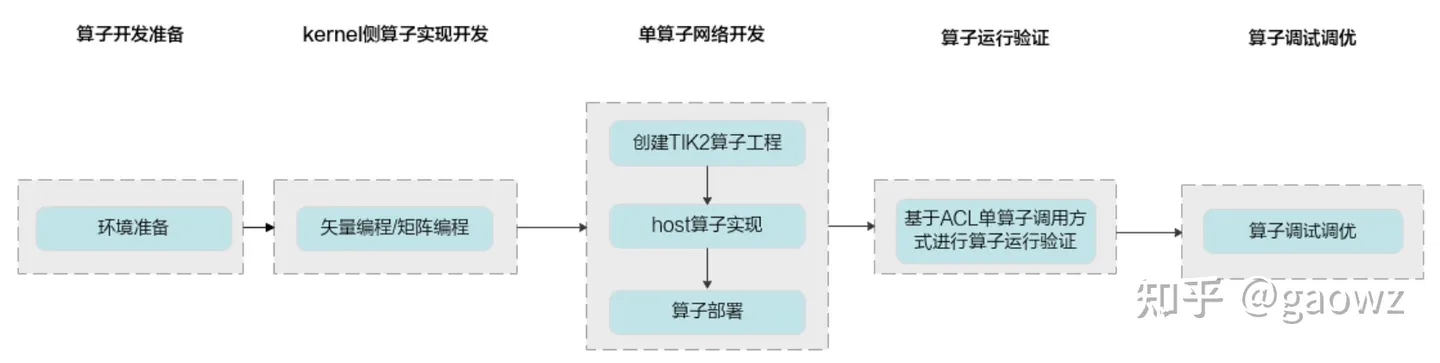
图3 TIK C++算子开发流程
- 算子分析:分析算子的数学表达式、输入、输出以及计算逻辑的实现,明确需要调用的TIK C++接口。
- 核函数定义:定义TIK C++算子入口函数。
- 根据矢量编程范式实现算子类:完成核函数的内部实现。核函数(Kernel Function)是TIK C++算子设备侧实现的入口。TIK C++允许用户使用核函数这种C/C++函数的语法扩展来管理设备端的运行代码,用户在核函数中进行算子类对象的创建和其成员函数的调用,由此实现该算子的所有功能。核函数是主机端和设备端连接的桥梁
- 核函数是直接在设备端执行的代码。在核函数中,需要为在一个核上执行的代码规定要进行的数据访问和计算操作,当核函数被调用时,多个核将并行执行同一个计算任务。核函数需要按照如下规则进行编写。
- 使用函数类型限定符除了需要按照C/C++函数声明的方式定义核函数之外,还要为核函数加上额外的函数类型限定符,包含__global__和__aicore__。
使用__global__函数类型限定符来标识它是一个核函数,可以被<<<...>>>调用;使用__aicore__函数类型限定符来标识该核函数在设备端AI Core上执行: - __global____aicore__ void kernel_name(argument list);

使用变量类型限定符
指针入参变量统一的类型定义为__gm__ uint8_t*,这里统一使用uint8_t类型的指针,在后续的使用中需要将其转化为实际的指针类型;用户亦可直接传入实际的指针类型。

- 核函数的调用语句是C/C++函数调用语句的一种扩展。
核函数使用内核调用符<<<...>>>这种语法形式,来规定核函数的执行配置:
kernel_name<<<blockDim, l2ctrl, stream>>>(argument list);
内核调用符仅可在NPU侧编译时调用,CPU侧编译无法识别该符号。
执行配置由3个参数决定: - blockDim,规定了核函数将会在几个核上执行。每个执行该核函数的核会被分配一个逻辑ID,表现为内置变量block_idx,可以在核函数的实现中直接使用;
- l2ctrl,保留参数,暂时设置为固定值nullptr,开发者无需关注;
- stream,类型为aclrtStream,stream是一个任务队列,应用程序通过stream来管理任务的并行。核函数的调用是异步的,核函数的调用结束后,控制权立刻返回给主机端,可以调用以下函数来强制主机端程序等待所有核函数执行完毕。
aclError aclrtSynchronizeStream(aclrtStream stream);

三 实现计算核函数的例子:两个矢量相加返回一个矢量
1.函数原型定义
本样例中,函数名为add_tik2(核函数名称可自定义);确定有3个参数x,y,z,参数类型统一设置成uint8_t*(在使用该入参时,需要首先转化为实际的half*类型,用户亦可设置为half*),其中x,y都为输入内存,z为输出内存;根据编写核函数核函数的规则介绍,返回值为void,并增加extern "C"标识。
由此,可以得到函数原型定义为:
extern "C" void add_tik2(uint8_t* x, uint8_t* y, uint8_t* z) { }
除了需要按照C/C++函数声明的方式定义核函数之外,还要为核函数加上额外的函数类型限定符和变量类型限定符。
使用__global__函数类型限定符来标识它是一个核函数,可以被<<<...>>>调用;使用__aicore__函数类型限定符来标识该核函数在设备端aicore上执行;参数列表中使用变量类型限定符__gm__来表明输入输出的指针变量指向Global Memory上的某处地址。
增加限定符后的函数原型定义为:
extern "C" __global__ __aicore__ void add_tik2(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z) { }
2.调用算子类的Init和Process函数。
算子类的Init函数,完成内存初始化相关工作,Process函数完成算子实现的核心逻辑,具体介绍参见算子类实现。
extern "C" __global__ __aicore__ void add_tik2(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z) { // 初始化算子类,算子类提供算子初始化和核心处理等方法 KernelAdd op; // 初始化函数,获取该核函数需要处理的输入输出地址,同时完成必要的内存初始化工作 op.Init(x, y, z); // 核心处理函数,完成算子的数据搬运与计算等核心逻辑 op.Process(); }
3.对核函数的调用进行封装,得到add_tik2_do函数,便于主程序调用。
#ifndef __CCE_KT_TEST__表示该封装函数仅在编译运行NPU侧的算子时会用到,编译运行CPU侧的算子时,可以直接调用add_tik2函数。根据调用核函数章节,调用核函数时,除了需要传入参数x,y,z,还需要传入blockDim(核函数执行的核数), l2ctrl(保留参数,设置为nullptr), stream(应用程序中维护异步操作执行顺序的stream)来规定核函数的执行配置。
#ifndef __CCE_KT_TEST__ // call of kernel function
void add_tik2_do(uint32_t blockDim,
void* l2ctrl,
void* stream, uint8_t* x, uint8_t* y, uint8_t* z) { add_tik2<<<blockDim, l2ctrl, stream>>>(x, y, z); }

















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









