







〔更多精彩AI内容,尽在 「魔方AI空间」 公众号,引领AIGC科技时代〕
本文作者:猫先生
引 言
本文是 LLM 基础入门系列的第 2 篇。在本文中,我们的目标是提供关于大语言模型 (LLM) 如何运行的易于理解的解释。
LLM大模型基础入门系列之:(一)(一)什么是大语言模型?-CSDN博客
LLM大模型基础入门系列之:(三)Transformer 架构-CSDN博客
LLM大模型基础入门系列之:(四)从头开始编写LLM代码-CSDN博客
LLM 的工作原理
我们首先看一下文档完成器模型的工作原理:
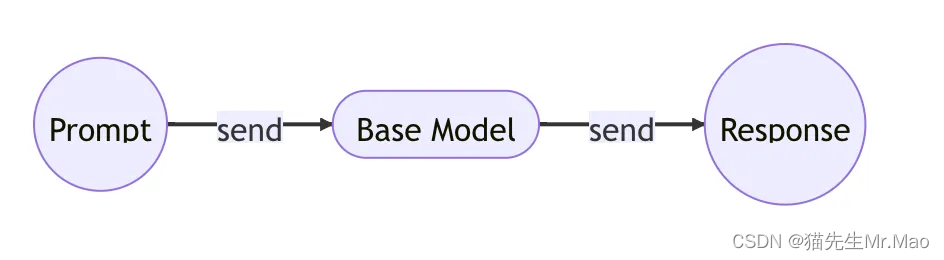
用户提示:
A banana is
模型响应:
an elongated, edible fruit
然后,文档生成器模型的工作原理如下:

用户提示:
I want to buy a new car
模型响应:
What kind of car do you want to buy?
注意上面两者的区别。
第一个模型只是一个文档完成器,它只会用它发现的最有可能成为下一个角色的内容来完成提示。这是我们在互联网数据块上训练的模型,称为基础模型。
第二个模型是一个文档生成器,它将根据提示问题生成更像人类的响应。这就是 ChatGPT 模型。
ChatGPT模型是一个推理模型,可以根据提示问题生成响应。我会说它 99% 是基本模型,但有两个额外的训练步骤:微调步骤和根据人类反馈进行强化学习步骤。
预训练:基础模型
这构成了人工智能革命的核心,也是真正的魔力所在。
训练模型是向其提供大量数据并让它从中学习的过程。
正如 GPT-3 论文中所述,基础模型是在大量互联网数据上进行训练的。对于像你我这样的人来说,这不是一件容易的事。它不仅需要获取数据,还需要GPU、TPU等大量的计算能力。
但不用担心,我们仍然可以学习在自己的计算机上训练小型 GPT 模型。将在下一个主题中展示如何执行此操作。
LLM 训练背后的创新在于 Transformer 架构的引入,该架构使模型能够从大量数据中学习,同时保留输入不同部分之间的关键上下文关系。
通过维护这些联系,模型可以根据提供的上下文有效地推断出新的见解,无论它们是单个单词、句子、段落还是其他内容。凭借这种能力,LLM训练为自然语言处理和生成任务开辟了新的机会,使机器能够更好地理解和响应人类交流。
用于训练基础模型的 Transformer 架构如下所示:
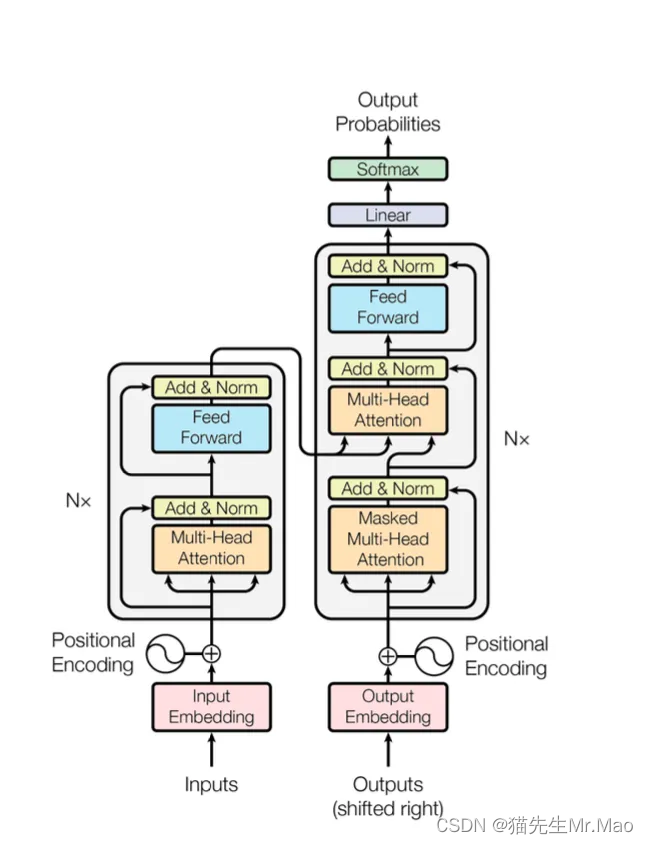
这是一个基于神经网络的模型训练,使用了一些新旧技术: tokenization, embedding, position encoding, feed-forward, normalization, softmax, linear transformation,最重要的是 multi-head attention 。
这部分是最吸引人的。我们想清楚地了解架构背后的想法以及训练到底是如何完成的。
因此,从下一篇文章及以后的文章中,我们将开始深入研究用于训练基本模型的论文、代码和数学。
微调:训练助手
微调是一个非常聪明的实现。我猜这是 OpenAI 首先完成的。这个想法非常简单,但运作起来很聪明:雇用人工贴标签者来创建大量问答对话对(例如 100k 对话)。然后向模型提供对话对并让它从中学习。
这个过程称为微调。您知道将这 10 万个样本对话训练到模型中后会发生什么吗?模型将开始像人类一样做出反应!
让我们看一下这些带有标签的对话示例:
Human labeled Q&A
Q: What is your name?
A: My name is John.
Human labeled Q&A
Q: What's the capital of China?
A: China's capital is Beijing.
Human labeled Q&A
Q: Summarize the plot of the movie Titanic.
A: The movie Titanic is about a ship that sinks in the ocean.
哇,这些示例问答正在嘲笑我们彼此交谈的方式。
通过向模型教授这些响应方式,相关上下文响应的概率将变得非常高,并成为对用户提示的响应。通过以各种对话风格训练模型,我们增加了它对提示提供相关且适合上下文的响应的可能性。
这就是语言模型为何显得如此智能和像人类的原因;通过学习模仿现实世界对话的节奏和模式,他们可以令人信服地模拟与用户的来回对话。
在这一步,我们可以说我们获得了一个助理模型。
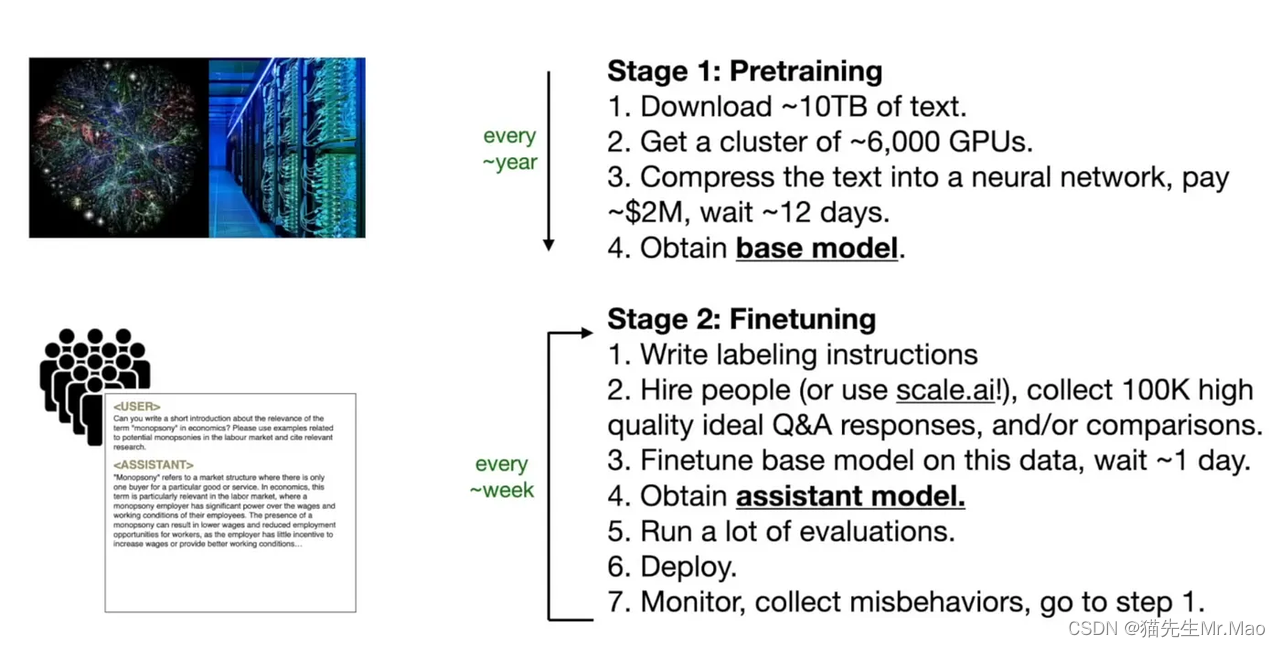
下图显示了从预训练基本模型到微调助理模型的一些要点:
RLHF:根据人类反馈进行强化学习
2022 年 1 月,OpenAI 发表了他们关于对齐语言模型以遵循指令的作品。在他们的博客文章中,他们描述了如何根据人类反馈进一步微调模型:
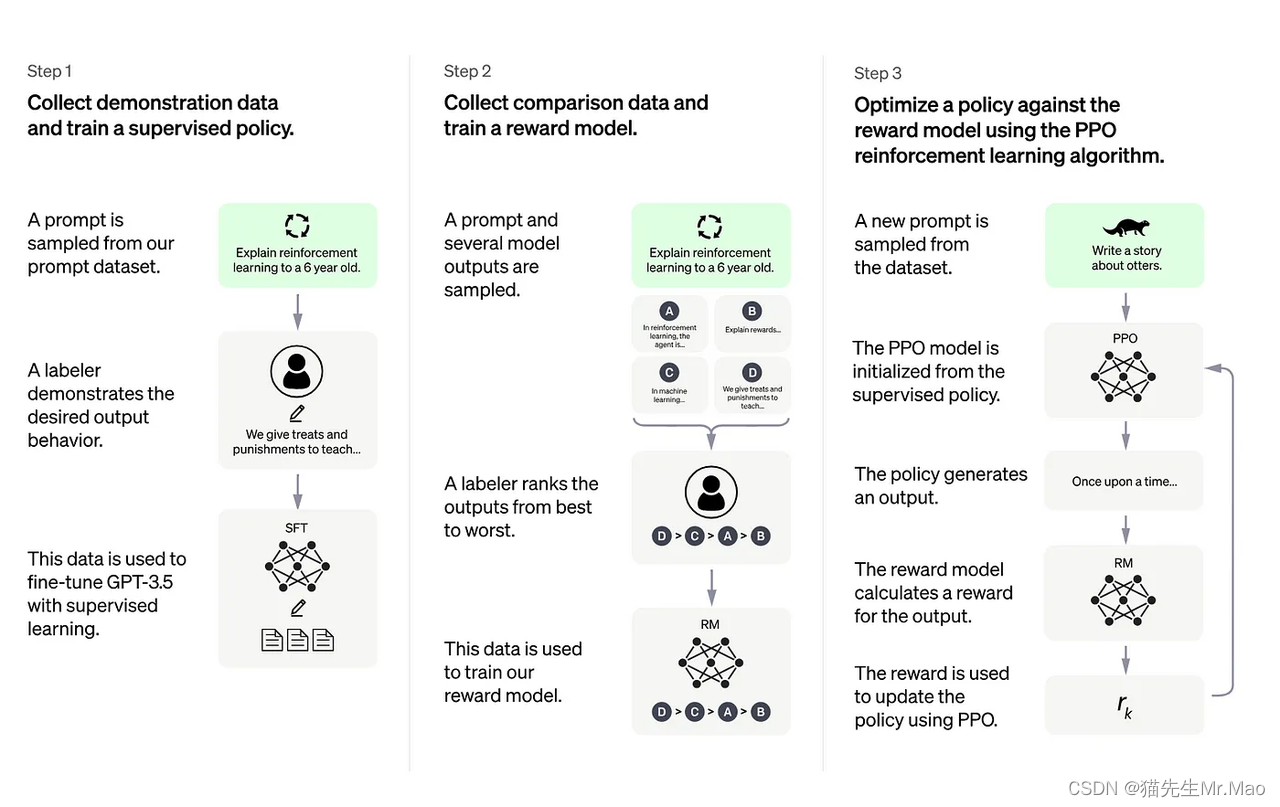
这个有点棘手。这个想法是让模型从人类反馈中学习。他们没有提供约 10 万个带标签的问答对,而是收集用户的提示和模型响应,然后让人类对它们进行排名。将排名后的对话作为最想要的问答样本,然后再次将其输入模型并让它从中学习以提高其整体性能。
OpenAI 在其博客上介绍了这个过程:
为了使我们的模型更安全、更有帮助、更一致,我们使用了一种称为基于人类反馈的**强化学习 (RLHF) 的现有技术。根据客户向 API 提交的提示,我们的贴标机会提供所需模型行为的演示,并对模型的多个输出进行排名。然后我们使用这些数据来微调 GPT-3。
以下是基本模型与微调 / RLHF 响应的比较:

你可以看到,没有fine-tune和RLHF,模型只是一个文档补全器。
提示工程
即使进行了微调和 RLHF,模型仍然需要一些帮助才能获得所需的响应。这就是提示工程的用武之地。
简而言之,我们可以仔细设计提示以从模型中获得所需的响应(有时甚至无需微调)。
如果不想深入研究数学和代码,那么提示工程是给予更多关注的好方法,因为只需输入更好的提示即可充分利用 LLM 模型。
现在让我们看一个例子:
提示:
The sky is
输出:
blue.
让我们尝试稍微改进一下:
提示:
Complete the sentence:
The sky is
输出:
blue during the day and dark at night.
通过在提示中包含一些说明,模型将知道要做什么以及要响应什么。
让我们看另一个有趣的例子:
提示:
When I was 6 my sister was half my age. Now
I’m 70 how old is my sister?
输出:
35
答案是错误的。正确答案应该是 67。看起来模型理解了问题,但指的是数学计算而不是逻辑推理。
无需微调和 RLHF,我们只需在提示中添加更多示例指令即可获得正确答案:
Q: There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done,
there will be 21 trees. How many trees did the grove workers plant today?
A: We start with 15 trees. Later we have 21 trees. The difference must be the number of trees they planted.
So, they must have planted 21 - 15 = 6 trees. The answer is 6.
Q: If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot?
A: There are 3 cars in the parking lot already. 2 more arrive. Now there are 3 + 2 = 5 cars. The answer is 5.
Q: Leah had 32 chocolates and her sister had 42. If they ate 35, how many pieces do they have left in total?
A: Leah had 32 chocolates and Leah’s sister had 42. That means there were originally 32 + 42 = 74
chocolates. 35 have been eaten. So in total they still have 74 - 35 = 39 chocolates. The answer is 39.
Q: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops
did Jason give to Denny?
A: Jason had 20 lollipops. Since he only has 12 now, he must have given the rest to Denny. The number of
lollipops he has given to Denny must have been 20 - 12 = 8 lollipops. The answer is 8.
Q: Shawn has five toys. For Christmas, he got two toys each from his mom and dad. How many toys does
he have now?
A: He has 5 toys. He got 2 from mom, so after that he has 5 + 2 = 7 toys. Then he got 2 more from dad, so
in total he has 7 + 2 = 9 toys. The answer is 9.
Q: There were nine computers in the server room. Five more computers were installed each day, from
monday to thursday. How many computers are now in the server room?
A: There are 4 days from monday to thursday. 5 computers were added each day. That means in total 4 * 5 =
20 computers were added. There were 9 computers in the beginning, so now there are 9 + 20 = 29 computers.
The answer is 29.
Q: Michael had 58 golf balls. On tuesday, he lost 23 golf balls. On wednesday, he lost 2 more. How many
golf balls did he have at the end of wednesday?
A: Michael initially had 58 balls. He lost 23 on Tuesday, so after that he has 58 - 23 = 35 balls. On
Wednesday he lost 2 more so now he has 35 - 2 = 33 balls. The answer is 33.
Q: Olivia has $23. She bought five bagels for $3 each. How much money does she have left?
A: She bought 5 bagels for $3 each. This means she spent $15. She has $8 left.
Q: When I was 6 my sister was half my age. Now I’m 70 how old is my sister?
A:
上面英文对应的中文意思:
Q: 小树林里有15棵树。林木工人今天将在树林里种树。完成后,将有21棵树。小树林的工人今天种了多少棵树?
A: 我们从15棵树开始。后来我们有了21棵树。区别一定是他们种的树的数量。所以,他们一定种了21-15=6棵树。答案是6。
Q: 如果停车场有3辆车,又有2辆车到达,那么停车场有多少辆车?
A: 停车场里已经有三辆车了。还有2个到达。现在有3+2=5辆车。答案是5。
Q: Leah有32块巧克力,她姐姐有42块。如果他们吃了35块,他们总共还剩多少块?
A: Leah有32块巧克力,Leah的姐姐有42块。这意味着最初有32+42=74块巧克力。35人已被吃掉。所以他们总共还有74-35=39块巧克力。答案是39。
Q: 杰森有20根棒棒糖。他给了丹尼一些棒棒糖。现在杰森有12根棒棒糖。杰森给了丹尼多少根棒棒糖?
A: 杰森有20根棒棒糖。既然他现在只有12个,他一定把剩下的都给了丹尼。他给丹尼的棒棒糖数量一定是20-12=8根棒棒糖。答案是8。
Q: 肖恩有五个玩具。圣诞节,他从父母那里各得到两个玩具。他现在有多少玩具?
A: 他有5个玩具。他从妈妈那里得到了2个,所以之后他有了5+2=7个玩具。然后他又从爸爸那里得到了两个,所以他总共有7+2=9个玩具。答案是9。
Q: 服务器室里有九台电脑。每天又安装了五台计算机,从
星期一到星期四。服务器机房里现在有多少台电脑?
A: 从星期一到星期四有4天。每天增加5台计算机。这意味着总共4*5=
增加了20台计算机。一开始有9台计算机,所以现在有9+20=29台计算机。答案是29。
Q: 迈克尔有58个高尔夫球。周二,他丢了23个高尔夫球。周三,他又输了2场。周三结束时,他有多少个高尔夫球?
A: 迈克尔最初有58个球。他在周二输了23个球,所以在那之后他有58-23=35个球。周三他又输了2个球,所以现在他有35-2=33个球。答案是33。
Q: 奥利维亚有23美元。她买了五个百吉饼,每个3美元。她还剩多少钱?
A: 她买了5个百吉饼,每个3美元。这意味着她花了15美元。她还剩8美元。
Q: 当我6岁的时候,我姐姐只有我的一半大。现在我70岁了,我姐姐多大了?
A.
输出1:
When I was 6 my sister was half my age, so she was 3. Now I am 70, so she is 70 - 3 = 67. The answer is 67.
我6岁的时候,我姐姐只有我的一半大,所以她才3岁。现在我70岁了,所以她70岁了。答案是67。
输出2:
When the narrator was 6, his sister was half his age, which is 3. Now that the narrator is 70, his sister would be 70 - 3 = 67 years old. The answer is 67.
叙述者6岁时,他的妹妹只有他3岁的一半。现在叙述者已经70岁了,他的妹妹也就70-3=67岁了。答案是67。
两个答案都是正确的!我们只需在提示中添加一些示例作为逻辑解释,然后再次询问相同的问题。该模型现在可以理解问题并正确回答。
强提示可用于指导模型执行复杂的任务,例如**解决数学问题或总结文本。**所以 prompt engineering 在LLM生态系统中也扮演着非常重要的角色。
有关提示工程的更多信息,这里有一个很好的提示指南教程。
总结
读到这里,我相信您需要一段时间才能消化所有信息,特别是对于那些刚接触 LLM 的人来说。
现在我相信我们已经在基本概念和背景信息方面涵盖了足够的基础。现在是我们开始准备构建我们自己的大语言模型的时候了。理论已经讲完了,我们将在下一篇文章中讨论 Transformers 架构的关键组成部分。
参考资料:
https://medium.com/@waylandzhang/how-large-language-model-works-llms-zero-to-hero-d2a8c1ac0e1e
技术交流
加入 「AIGCmagic社区」群聊,一起交流讨论,涉及 AI视频、AI绘画、Sora技术拆解、数字人、多模态、大模型、传统深度学习、自动驾驶等多个不同方向,可私信或添加微信号:【m_aigc2022】,备注不同方向邀请入群!!
更多精彩内容,尽在 「魔方AI空间」,关注了解全栈式 AIGC 内容!!















 3943
3943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









